知识图谱关系预测:结构与文本特征融合方法
需积分: 0 94 浏览量
更新于2024-08-05
收藏 3.61MB PDF 举报
“融合结构与文本特征的知识图谱关系预测方法研究_林泽斐1”
本文主要探讨了如何利用知识图谱的内部结构特征和外部文本特征来预测实体间缺失的关系类型,这是一种针对知识图谱关系预测的新方法。作者林泽斐和欧石燕通过这种方法,旨在提高预测的准确性和效率,进一步完善知识图谱的构建。
知识图谱是当前信息技术领域中的一个重要概念,它是一种结构化的知识表示方式,能够清晰地描述实体(如人、地点、事件等)及其相互关系。关系预测是知识图谱中的关键任务,其目标是预测两个已知实体之间可能存在的未知关系,这对于知识图谱的扩展和更新至关重要。
传统的知识图谱关系预测方法主要依赖于结构信息,即实体间的三元组模式。然而,这种依赖于结构的方法可能无法充分捕捉到实体的复杂语义信息。因此,文章提出了将结构特征与文本特征相结合的新策略。结构特征通常涉及实体之间的链接模式和关系分布,而文本特征则来源于实体相关的文本数据,如文档、网页内容等,这些数据可以提供丰富的上下文信息,帮助理解实体的语义含义。
文章中提到的融合方法可能包括以下步骤:首先,提取知识图谱的结构特征,如实体间的路径信息、关系频率等;其次,利用自然语言处理技术从文本数据中提取实体的语义特征,例如词向量表示、命名实体识别等;最后,通过集成学习或者深度学习模型,将这两种特征进行有效的融合,以预测新的关系。
在实施这个方法时,可能会遇到的挑战包括如何有效地提取和整合两种类型的特征,以及如何设计合适的模型来处理高维度特征。此外,处理大量文本数据和避免过拟合也是需要注意的问题。文章可能还讨论了实验结果,包括与其他方法的对比,以及对预测性能的评估。
网络首发的论文通常在经过严格的同行评审和主编终审后发布,确保了内容的科学性和合规性。这篇论文在网络首发后,虽然标题、作者、机构和内容原则上不可更改,但可以根据编辑规范进行小幅度的文字调整,以保证最终的发布质量。
这篇研究工作对于提升知识图谱的完整性、准确性和实用性具有重要意义,特别是在大数据时代,如何有效地利用多源信息来增强知识图谱的智能应用具有广泛的应用前景。
第 64卷 第 21期 2020年 11月
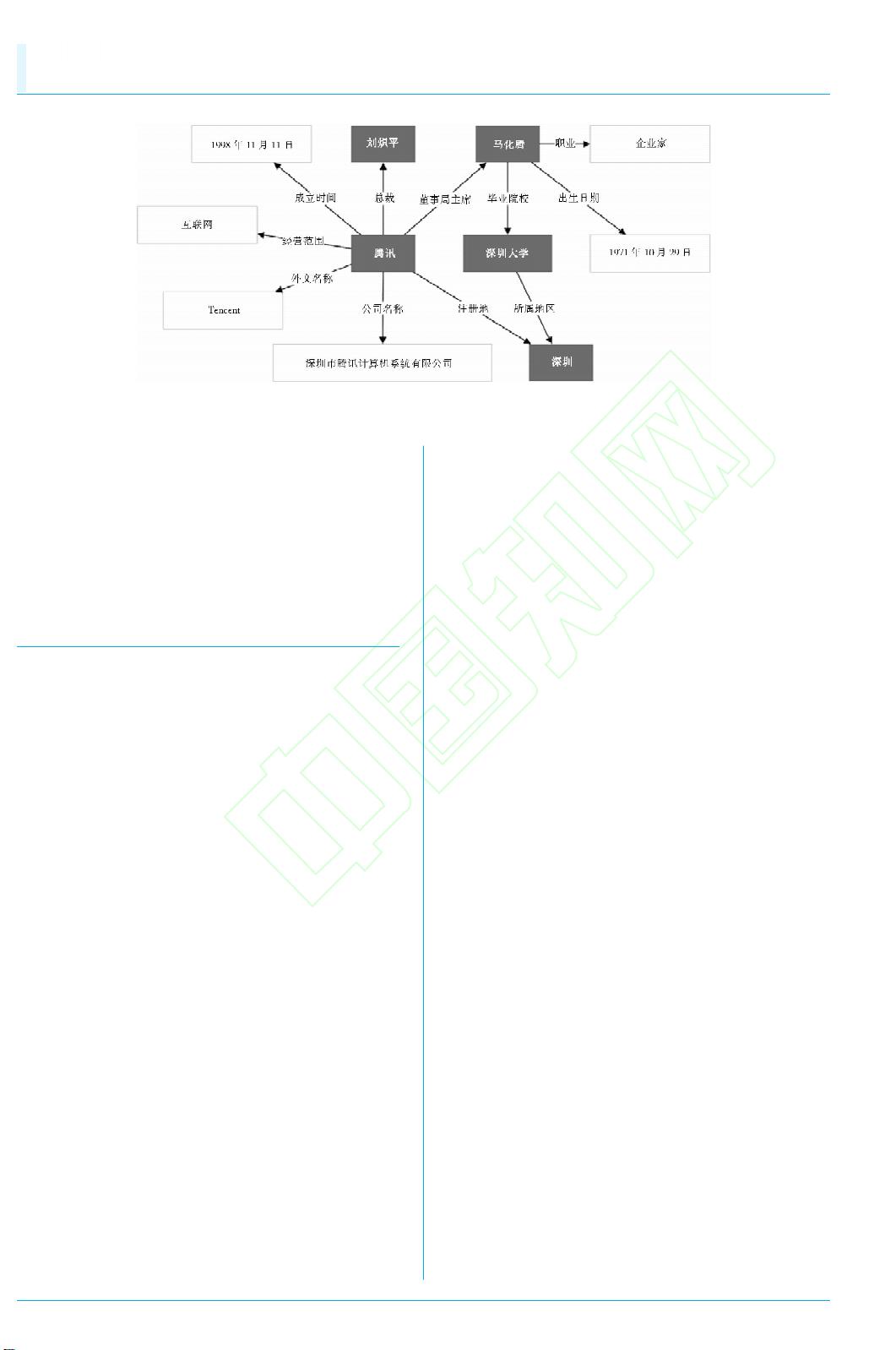
图 1 CNDBpedia知识图谱中的局部实体 -关系视图
者结合进行关系预测的研究仍十分缺乏。针对这一问
题,本研究将探索一种新的知识图谱关系预测方法,其
创新之处在于设计了一种对实体间关系路径结构特征
进行学习的深度学习模型,并将外部文本的特征集成
到该模型中,从而构建出一个融合知识图谱内部结构
与外部文本特征的关系预测集成模型。
1 相关工作
当前,针对知识图谱中缺失关系的预测有两种典
型方法:基于知识表示学习的方法和基于关系路径的
方法。
知识表示学习是利用机器学习技术学习出知识图
谱中实体和关系的低维稠密向量表示
[7]
。以 TransE
模型为代表的翻译模型是当前知识表示学习的主流模
型
[8]
。TransE模型
[9]
将关系向量 r视为头实体向量 h
和尾实体向量 t之间的平移向量,如 h(腾讯)+r(董事
会主席)
≈
t(马化腾),通过最小化 h+r与 t之间的距
离训练出实体和关系的向量表示。得到每一实体和关
系的向量表示后,通过寻找使 h+r与 t之间的距离尽
可能小 的 r,即 可 预 测 出 头 尾 实 体 间 的 关 系 类 型。
TransE在处理“一对多”“多对多”等复杂关系时存在
局限性,故一些学者提出了 TransE模型的变体形式,
如 TransH、TransR和 TransD等,其中 TransH
[10]
为不同
关系指定不同的超平面,从而使一个实体在不同的关
系下拥有不同的向量表示,而 TransR
[11]
和 TransD
[12]
模
型则通过在不同语义空间内表示实体和关系来解决上
述问题。除翻译模型外,语义匹配模型也是知识表示
学习中的一类经典模型,此类模型将实体和关系映射
到向量空间中,通过相似度评价函数来学习实体和关
系的隐含特征
[13]
,代表性工作包括 RESCAL模型
[14]
及
其改进模型 DistMult
[15]
和 ComplEx
[16]
等。基于知识表
示学习的关系预测方法其优势在于预测准确率较高,
且具有较强的通用性,训练出的实体和关系向量不仅
适用于关系预测任务,也适用于实体预测和三元组分
类等其他任务;不足之处在于其主要关注以三元组为
单元的局部信息,而较少关注知识图谱的网状结构与
关系间的逻辑推理。
关系路径是知识图谱中两实体间的连通路径,这
些连通路径也能反映出实体之间的语义关系。基于关
系路径的方法使用关系路径作为特征来对实体间的关
系类型进行预测。卡内基梅隆大学的 N.Lao等所提
出的路径排序算法(
pathrankingalgorithm,PRA)
[17]
是
此类方法的典型代表。该算法从知识图谱中提取出所
有带有关系 r的三元组集合,以集合中每个三元组的
头实体作为起点进行随机游走,若三步内可到达尾实
体,则将该游走路径
π
作为关系 r的一条关系路径用
于模型训练,通过逻辑回归算法在训练集上学习出各
路径相对于关系 r的权重。接下来,通过一种路径约
束的随机游走(pathconstraintrandom walk)方法来计
算头实体沿着路径
π
到达尾实体的转移概率。最后,
使用一个综合路径权重和转移概率的评分函数来评估
实体对间存在关系 r的可能性。基于关系路径的方法
利用了知识图谱的网状结构与实体关系间的逻辑推
理,具有良好的可解释性,但 PRA对于关系路径的学
习能力仍较为有限,其关系预测性能相比 TransE等主
流模型有一定差距
[18]
。
上述两种方法均基于知识图谱内部结构特征进行
关系预测,区别在于前者关注以三元组为单元的微观
结构,而后者关注以路径为单元的宏观结构。除结构
特征外,知识图谱外部的文本信息也可作为知识图谱
关系预测的依据。近年来,一些研究者开始利用外部
文本信息改善知识图谱补全的效果,相关研究多是将
001
剩余12页未读,继续阅读
2021-10-03 上传
2022-08-03 上传
2020-05-06 上传
2022-08-04 上传
2018-09-13 上传
246 浏览量
2018-01-21 上传
2018-01-21 上传

方2郭
- 粉丝: 32
- 资源: 324
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
