空间变换网络:提升深度学习的不变性与性能
需积分: 10 94 浏览量
更新于2024-07-18
收藏 7.89MB PDF 举报
《1506.02025_Spatial Transformer Networks》这篇论文由Max Jaderberg、Karen Simonyan、Andrew Zisserman和Koray Kavukcuoglu四位作者在Google DeepMind伦敦分部共同完成,发表于2015年。论文的主要贡献在于提出了一种名为Spatial Transformer(空间变换器)的新型可学习模块,这一创新在深度学习领域具有重要意义。
传统卷积神经网络(Convolutional Neural Networks, CNN)因其强大的表征能力而受到广泛关注,然而它们在处理空间不变性方面仍有局限性。即,CNN模型缺乏以高效计算和参数效率的方式处理输入数据在空间上的变化(如平移、缩放、旋转或更复杂的扭曲)的能力。为解决这个问题,论文引入了Spatial Transformer,它是一个可插入到现有CNN架构中的模块,使得神经网络能够在无额外训练监督或优化过程调整的情况下,根据特征图条件自适应地对特征图进行空间变换。
这个模块的核心优势在于其可微分性,这意味着它可以在训练过程中动态学习最佳的变换策略,从而提高模型的泛化能力和性能。通过使用Spatial Transformer,作者展示了模型在处理多种空间变换时能够学习到内在的不变性,这显著提升了他们在多个基准测试中的表现,并且对于多种类型的变换类别都表现出最先进的技术水平。
论文的1.0节概述了这一工作的背景,指出随着深度学习的快速发展,尤其是CNN的成功应用,对模型处理空间不变性的需求日益增强。作者们通过引入Spatial Transformer,不仅填补了这一空白,还展示了其在实际任务中的潜力,预示着这种技术可能会引领未来计算机视觉和深度学习领域的研究方向。
Spatial Transformer Networks论文是一项重要的突破,它通过增强CNN的内在空间灵活性,促进了计算机视觉模型在各种复杂场景下的稳健性和准确性,为后续的研究者提供了新的工具和技术,推动了深度学习领域的发展。
U
V
Localisation net
Sampler
Spatial Transformer
Grid !
generator
T
✓
(G)
✓
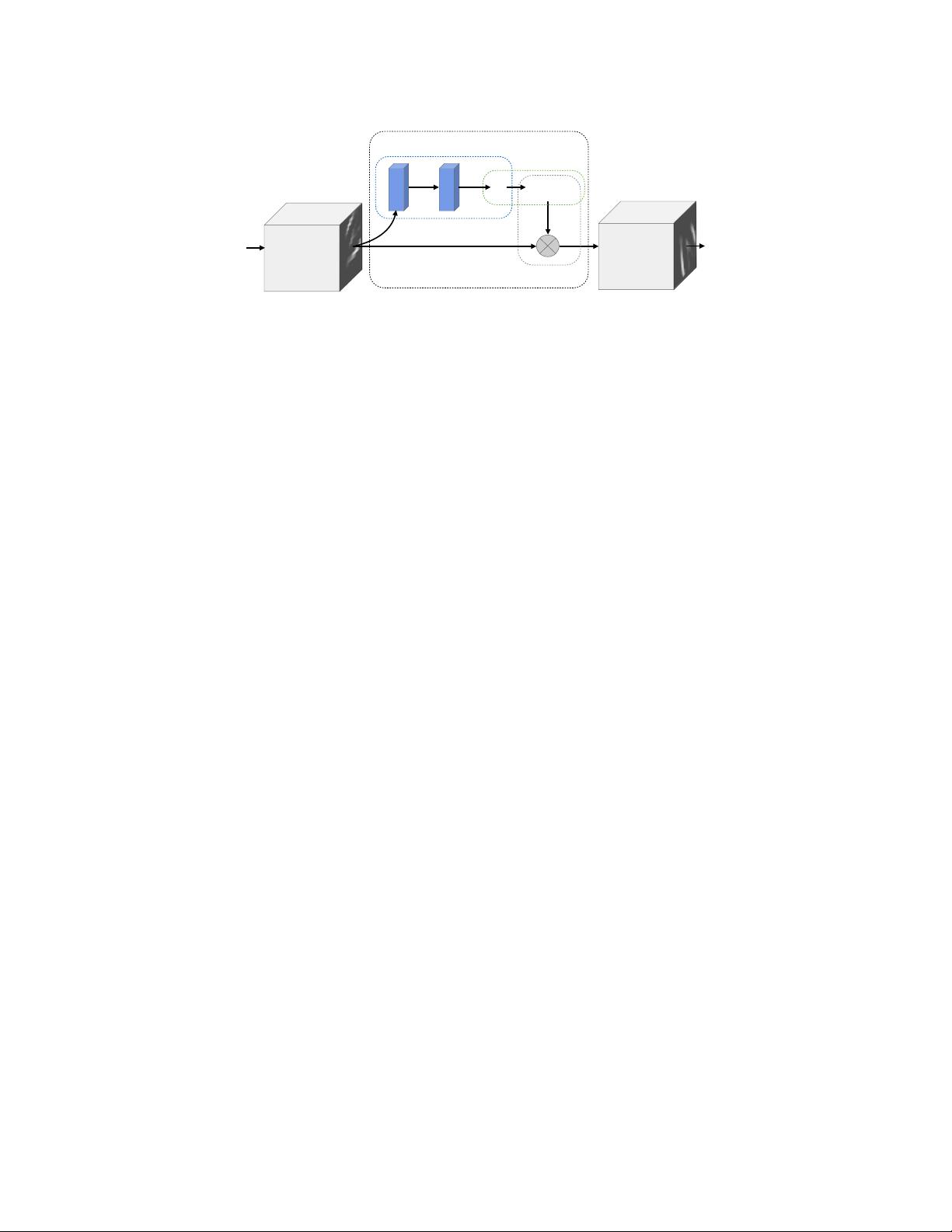
Figure 2: The architecture of a spatial transformer module. The input feature map U is passed to a localisation
network which regresses the transformation parameters θ. The regular spatial grid G over V is transformed to
the sampling grid T
θ
(G), which is applied to U as described in Sect. 3.3, producing the warped output feature
map V . The combination of the localisation network and sampling mechanism defines a spatial transformer.
need for a differentiable attention mechanism, while [14] use a differentiable attention mechansim
by utilising Gaussian kernels in a generative model. The work by Girshick et al. [11] uses a region
proposal algorithm as a form of attention, and [7] show that it is possible to regress salient regions
with a CNN. The framework we present in this paper can be seen as a generalisation of differentiable
attention to any spatial transformation.
3 Spatial Transformers
In this section we describe the formulation of a spatial transformer. This is a differentiable module
which applies a spatial transformation to a feature map during a single forward pass, where the
transformation is conditioned on the particular input, producing a single output feature map. For
multi-channel inputs, the same warping is applied to each channel. For simplicity, in this section we
consider single transforms and single outputs per transformer, however we can generalise to multiple
transformations, as shown in experiments.
The spatial transformer mechanism is split into three parts, shown in Fig. 2. In order of computation,
first a localisation network (Sect. 3.1) takes the input feature map, and through a number of hidden
layers outputs the parameters of the spatial transformation that should be applied to the feature map
– this gives a transformation conditional on the input. Then, the predicted transformation parameters
are used to create a sampling grid, which is a set of points where the input map should be sampled to
produce the transformed output. This is done by the grid generator, described in Sect. 3.2. Finally,
the feature map and the sampling grid are taken as inputs to the sampler, producing the output map
sampled from the input at the grid points (Sect. 3.3).
The combination of these three components forms a spatial transformer and will now be described
in more detail in the following sections.
3.1 Localisation Network
The localisation network takes the input feature map U ∈ R
H×W ×C
with width W , height H and
C channels and outputs θ, the parameters of the transformation T
θ
to be applied to the feature map:
θ = f
loc
(U). The size of θ can vary depending on the transformation type that is parameterised,
e.g. for an affine transformation θ is 6-dimensional as in (10).
The localisation network function f
loc
() can take any form, such as a fully-connected network or
a convolutional network, but should include a final regression layer to produce the transformation
parameters θ.
3.2 Parameterised Sampling Grid
To perform a warping of the input feature map, each output pixel is computed by applying a sampling
kernel centered at a particular location in the input feature map (this is described fully in the next
section). By pixel we refer to an element of a generic feature map, not necessarily an image. In
general, the output pixels are defined to lie on a regular grid G = {G
i
} of pixels G
i
= (x
t
i
, y
t
i
),
forming an output feature map V ∈ R
H
0
×W
0
×C
, where H
0
and W
0
are the height and width of the
grid, and C is the number of channels, which is the same in the input and output.
3
剩余14页未读,继续阅读
2021-05-14 上传
2018-01-17 上传
2021-02-04 上传
2022-07-14 上传
2022-09-24 上传
2022-07-14 上传
2022-07-14 上传
2022-09-23 上传

XGF的碎碎念
- 粉丝: 6
- 资源: 20
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
