监督学习:从入门到应用策略
需积分: 9 190 浏览量
更新于2024-07-15
收藏 1.88MB PDF 举报
监督式学习是机器学习中的核心概念,它涉及使用已知的输入数据(训练集)及其对应的输出结果(目标变量)来训练模型,以便对新的输入数据进行预测。这种学习方式适用于那些有明确输出类别或数值的情况,比如区分垃圾邮件与非垃圾邮件(二分类问题)或者预测股票价格(回归问题)。监督学习算法可以分为两大类:分类和回归。
分类算法用于预测离散的输出,例如判断邮件类型(垃圾邮件或非垃圾邮件)、肿瘤大小分类等。这类任务中,模型会学习将数据分成不同的类别,常见的分类算法有逻辑回归,它特别适合于二分类问题,因为它能够计算每个类别的概率。对于多分类问题,如图像识别,可能需要更复杂的算法来处理多个类别之间的区分。
回归算法则预测连续的输出值,如温度预测、设备故障时间估计或电力需求预测。这种方法关注的是数据点之间关系的连续性,如预测股价变化或声信号处理中的参数估计。
在选择监督式学习算法时,需要考虑多个因素:训练速度(模型构建所需的时间),内存使用(模型的复杂性和存储需求),预测准确度(模型性能的关键指标),以及算法的透明度和可解释性(理解模型决策背后的逻辑)。通过比较不同算法在这些方面的表现,可以选择最适合特定任务的模型。
监督式学习是数据科学中不可或缺的一部分,它通过训练数据驱动模型,帮助我们在未知数据上做出准确预测。然而,实际应用中,需要根据具体问题的特性(是二分类还是多分类,数据的离散或连续性)和业务需求来选择合适的算法,并在实践中不断优化和调整,以达到最佳效果。
4
应用监督式学习
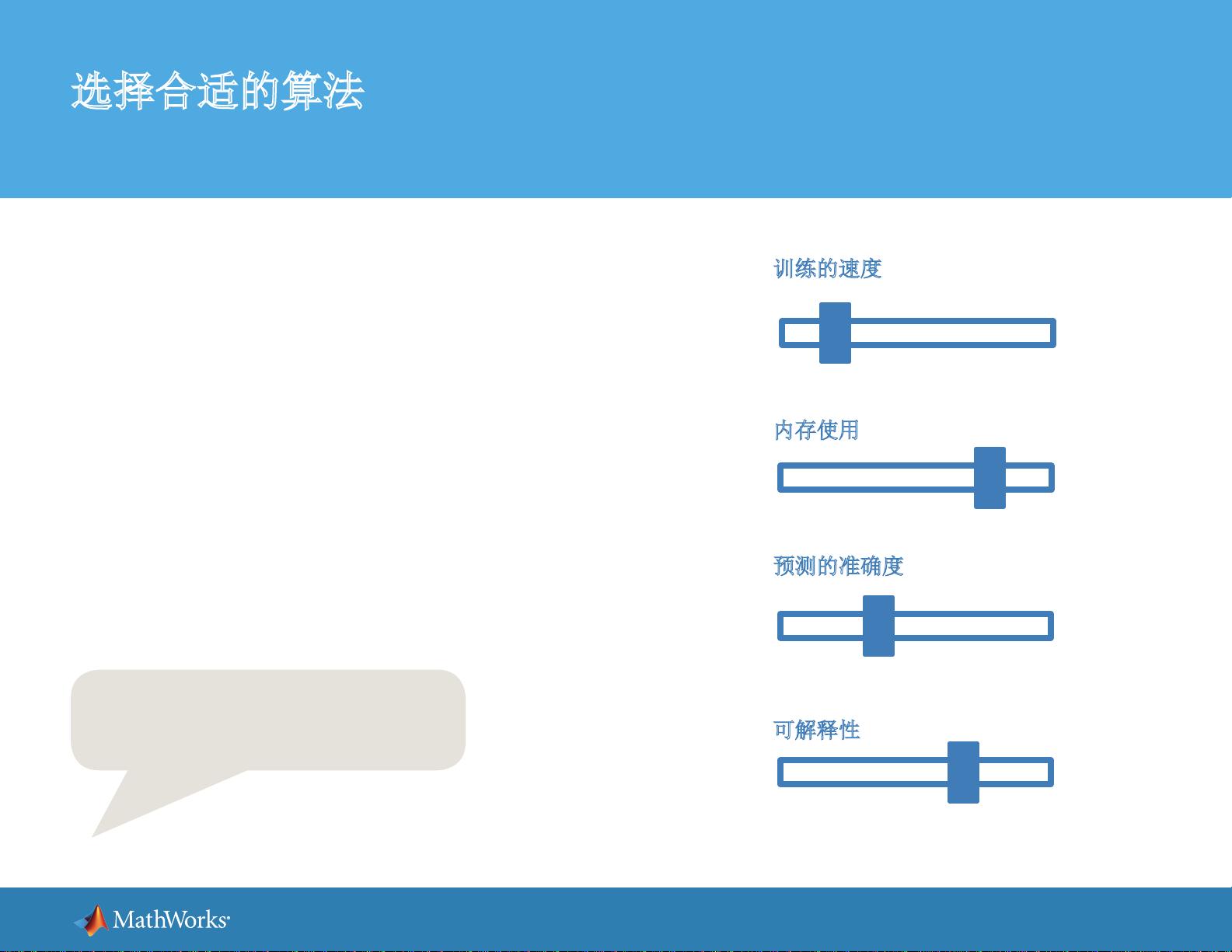
选择合适的算法
如我们在第 1 部分所见,选择机器学习算法是一个试错过程。
同时也是算法具体特性的一种权衡,比如:
• 训练的速度
• 内存使用
• 对新数据预测的准确度
• 透明度或可解释性(您对算法做出预测的理由的理解难易程度)
我们详细介绍最常用的分类和回归算法。
使用较大的训练数据集生成的模型通常对新数据
归纳得比较完善。
训练的速度
内存使用
预测的准确度
可解释性
剩余19页未读,继续阅读
2021-09-24 上传
2018-08-11 上传
2023-07-24 上传
2023-07-05 上传
2023-12-04 上传
2024-02-08 上传
2023-09-10 上传
2023-11-17 上传
2023-12-05 上传

Dr.ZJH
- 粉丝: 5
- 资源: 41
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
