机器学习常用算法总结:因子分析和主成分分析
需积分: 12 106 浏览量
更新于2024-07-18
收藏 23.26MB DOCX 举报
机器学习常用算法汇总
机器学习是一门重要的计算机科学和统计学学科,旨在研究如何使计算机系统自动提高性能,通过经验和数据来不断改进自己的性能。机器学习中有很多常用的算法,本文将对其中的一些常用算法进行汇总。
1. 因子分析(FA)
因子分析是一种多元统计方法,将多个实测变量转换为少数几个不相关的综合指标。它通过研究众多变量之间的内部依赖关系,探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。假想变量是不可观测的潜在变量,称为因子。
假定这p个有相关关系的随机变量含有m个彼此独立的因子,可表示为:
或用矩阵表示为X=AF+ε
其中,F1,F2,…,Fm称为公共因子,是不可观测的变量,它们的系数称为因子载荷,A称为因子载荷矩阵。ε是特殊因子,是不能包含在公共因子的部分。
需要满足:
m≤p,即公共因子数不超过原变量个数
公共因子之间互不相关,且每个Fi方差为1,即F的协方差矩阵为I
公共因子和特殊因子之间彼此互不相关,即Cov(F,ε)=0
特殊因子之间彼此互不相关,但方差不一定相同,记εI的方差为
理想的情况是,对于每个原始变量而言,其在因子载荷矩阵中,在一个公共因子上的载荷较大,在其他的因子上载荷较小。可以通过因子旋转方法调整因子载荷矩阵。
2. 主成分分析(PCA)
主成分分析是一种常用的降维方法,试图在力保数据信息丢失最少的原则下,对多个变量进行最佳综合简化,即对高维变量空间进行降维处理。
假设原来有p个变量(或称指标),通常的做法是将原来p个变量(指标)作线性组合,以此新的综合变量(指标)代替原来p个指标进行统计分析。如果将选取的第一个线性组合,即第一个综合变量(指标),记为F1,则自然希望F1尽可能多地反映原有变量(指标)的信息。
如何衡量信息的含量,经典的做法就是采用“方差”来表示。F1的方差越大,F1所包含的信息就越多。这样,F1的选取方法是,在所有的原来p个变量(指标)的线性组合中,选取方差最大的线性组合作为F1,称为第一主成分。如第一主成分不足于代表原来p个变量(指标)的信息,则考虑选取第二主成分F2。为有效反映原信息,F1已有的信息不需要再现在F2中,即要求F1与F2的协方差为零,即Cov(F1,F2)=0。依此下去,我们可以构造出第三、第四、…、第p个主成分。在主成分之间,不仅不相关,而且方差依次递减。在实际经济工作中,我们往往选取前面几个较大的主成分。虽然损失一部分信息,但我们抓住了原来p个变量的大部分信息(一般要求超过85%),分析的结果应该是可靠的、可信的。
对所选主成分作经济解释:
主成分分析的关键在于能否给主成分赋予新的意义,给出合理的解释,这个解释是对主成分的经济解释。通过经济解释,可以更好地理解数据的含义,对数据进行更好的分析和应用。
其中{at}是白噪声序列,这个模型与简单线性回归模型有相同的形式,这个模型也叫做一阶自回归(AR)
模型,简称 AR(1)模型
从 AR(1)很容易推广到 AR(p)模型:
AR(p)模型的特征根及平稳性检验。
我们先假定序列是弱平稳的,则有;
因为{at}是白噪声序列,因此有:
所以有:
根据平稳性的性质,又有 E(rt) = E(rt-1)=...= u,从而:
对式 2.1,假定分母不为 0, 我们将下面的方程称为特征方程:
该方程所有解的倒数称为该模型的特征根,如果所有的特征根的模都小于 1,则该 AR(p)序列是平稳的。
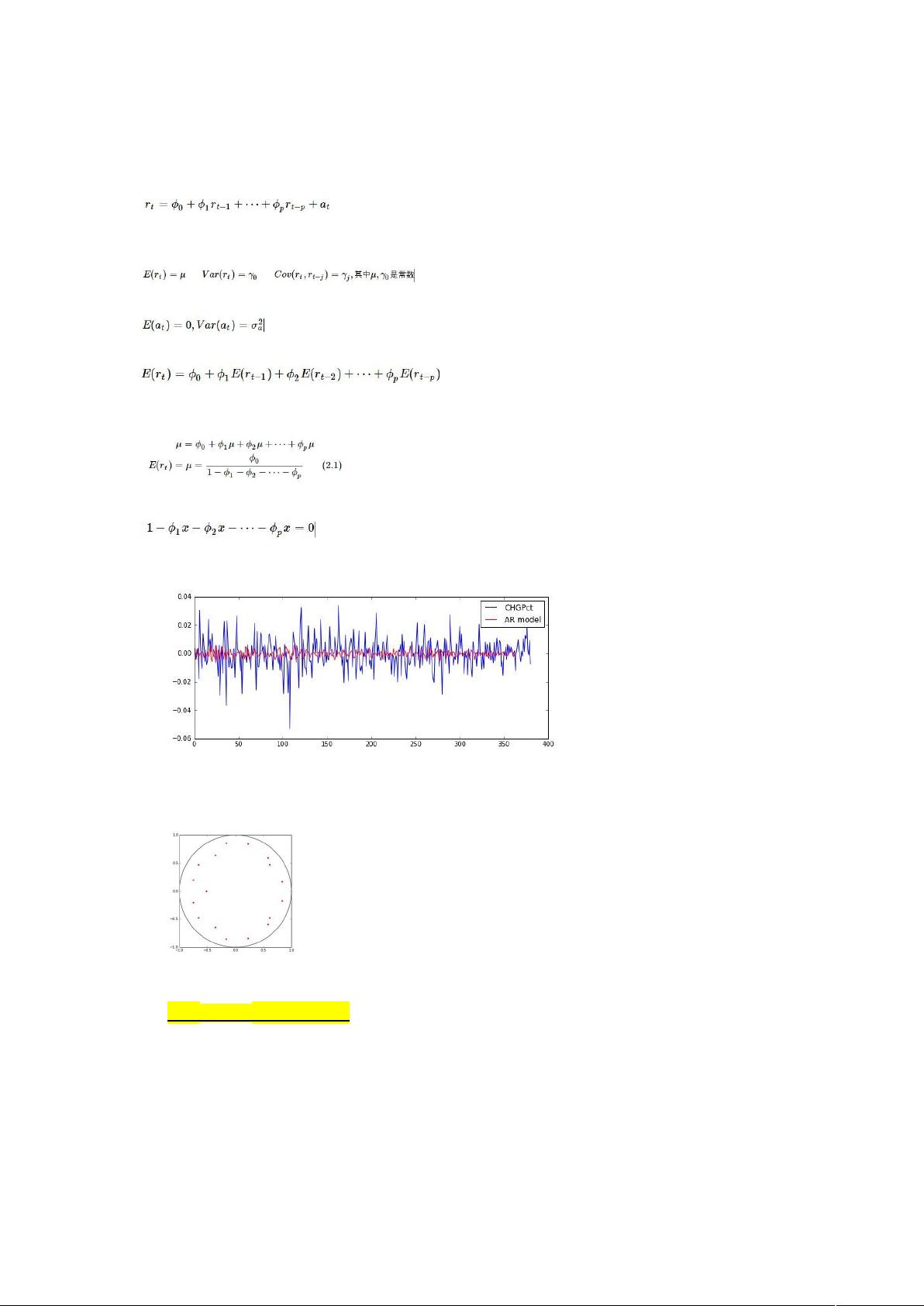
下面我们就用该方法,检验上证指数日收益率序列的平稳性。
我们可以看看模型有多少阶。
可以看出,自动生成的 AR 模型是 17 阶的。关于价次的讨论在下节内容,我们画出模型的特征根,来检
验平稳性。
可以看出,所有特征根都在单位圆内,则序列为平稳的!
二、 AR(p) 模型的定阶:
一般有两种方法来决定 p:
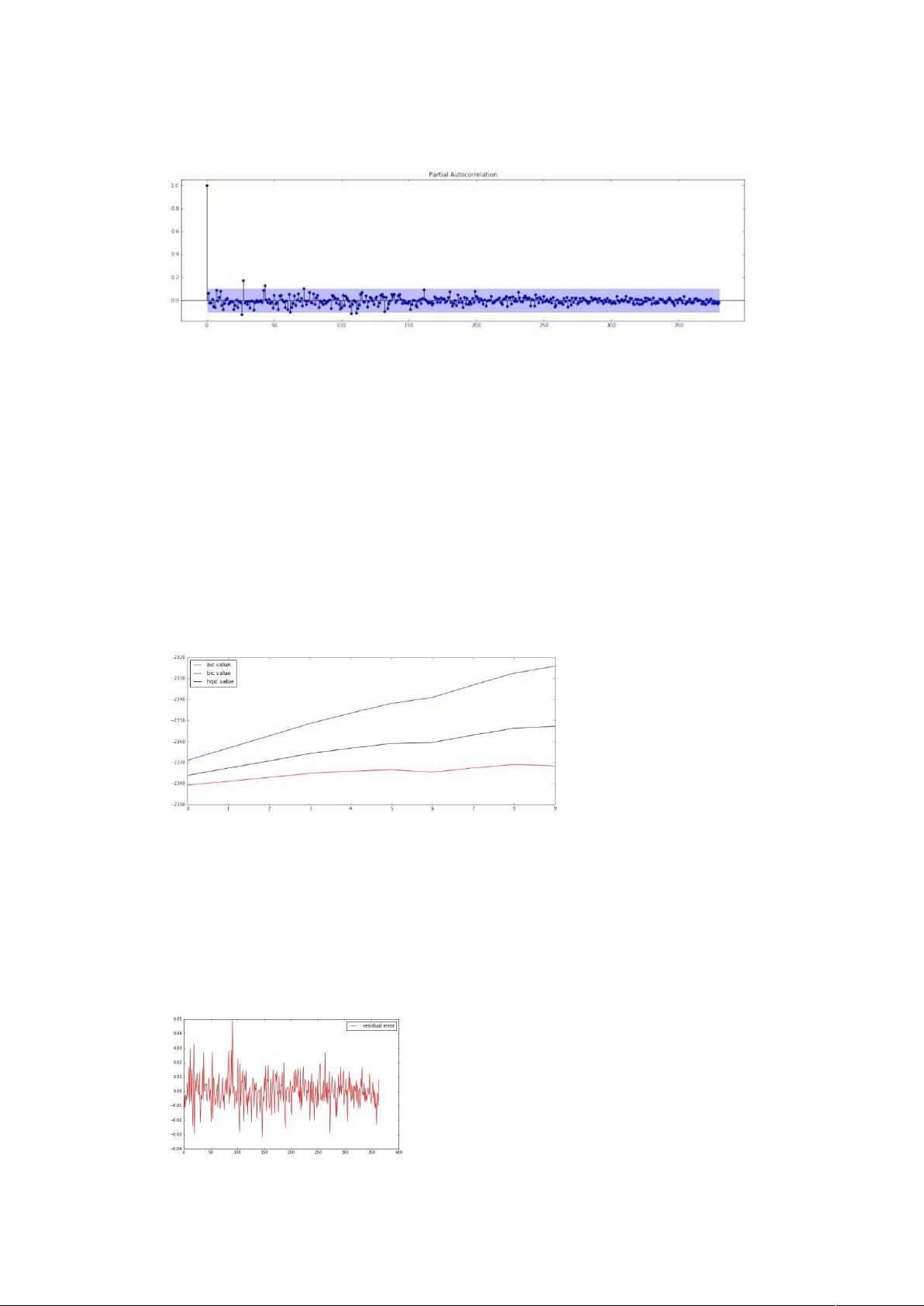
第一种:利用偏相关函数(Partial Auto Correlation Function,PACF)
第二种:利用信息准则函数
偏相关函数判断 p:
对于偏相关函数的介绍,这里不详细展开,重点介绍一个性质:
AR(p)序列的样本偏相关函数是 p 步截尾的。

剩余63页未读,继续阅读
171 浏览量
2021-04-30 上传
2024-05-08 上传
2024-04-23 上传
2018-01-16 上传
2022-06-15 上传
2022-06-14 上传
2021-01-21 上传

又见智能商业
- 粉丝: 1165
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
