统计学习元素:随机森林方法详解
需积分: 3 34 浏览量
更新于2024-08-02
收藏 821KB PDF 举报
《统计学习元素》(第二版,Trevor Hastie, 2008)是一本在过去的十年中随着信息技术爆炸式增长而诞生的重要著作。书中探讨了数据科学领域的新工具和发展,特别是在医学、生物学、金融和营销等领域的海量数据处理。作者们强调概念而非数学细节,通过丰富的例子和彩色图形来阐述这些领域中的关键思想,包括但不限于数据挖掘、机器学习和生物信息学。
该书的核心内容集中在第15章“随机森林”上,这是一种针对高方差低偏差预测模型(如决策树)的变种方法,即bagging或bootstrap aggregating(第8.7节)。bagging通过在训练数据的多个Bootstrap样本上多次训练同一种模型,并取平均结果来降低预测函数的方差。对于分类问题,它则采用了一组决策树投票的方式决定预测类别。
随机森林是bagging的进一步发展,由Breiman提出,它构建了一大批相互独立的决策树,然后取平均以提高性能。与boosting不同,随机森林的集成过程是静态的,而非动态调整弱学习器权重。尽管随机森林在许多问题上的表现接近boosting,但由于其训练和调参更为简单,因此更受欢迎,已被广泛应用于各种软件包中。
随机森林的定义包含以下几个要点:
1. **原理**:它利用了bagging的思想,通过构建大量互相独立的决策树,减少了单个树的过拟合风险。
2. **应用**:对于高方差任务,如回归和分类,随机森林表现出色,尤其适合减少预测模型的不稳定性。
3. **构建过程**:每一棵树是基于随机选择的特征子集和样例进行训练,这样可以确保不同的树之间具有较低的关联性。
4. **集成**:集成所有树的结果,通常是通过多数投票或者平均值来确定最终预测。
5. **优点**:易用、可扩展且性能稳定,使得随机森林成为了数据挖掘和机器学习中常用的工具。
《统计学习元素》的这一章节深入介绍了随机森林的理论基础、优势和应用,这对于任何对数据分析感兴趣的人来说都是一份宝贵的资源,无论是统计学家还是科学或工业界的数据挖掘实践者。它涵盖了从监督学习到无监督学习的广泛内容,包括神经网络、支持向量机、决策树和提升技术,为读者提供了一个统一的概念框架。
590 15. Random Forests
Random forests are popular. Leo Breiman’s
1
collaborator Adele Cutler
maintains a random forest website
2
where the software is freely available,
with more than 3000 downloads reported by 2002. There is a randomForest
package in R, maintained by Andy Liaw, available from the CRAN website.
The authors make grand claims about the success of random forests:
“most accurate,” “most interpretable,” and the like. In our experience ran-
dom forests do remarkably well, with very little tuning required. A ran-
dom forest classifier achieves 4.88% misclassification error on the
spam test
data, which compares well with all other methods, and is not significantly
worse than gradient boosting at 4.5%. Bagging achieves 5.4% which is
significantly worse than either (using the McNemar test outlined in Ex-
ercise 10.6), so it appears on this example the additional randomization
helps.
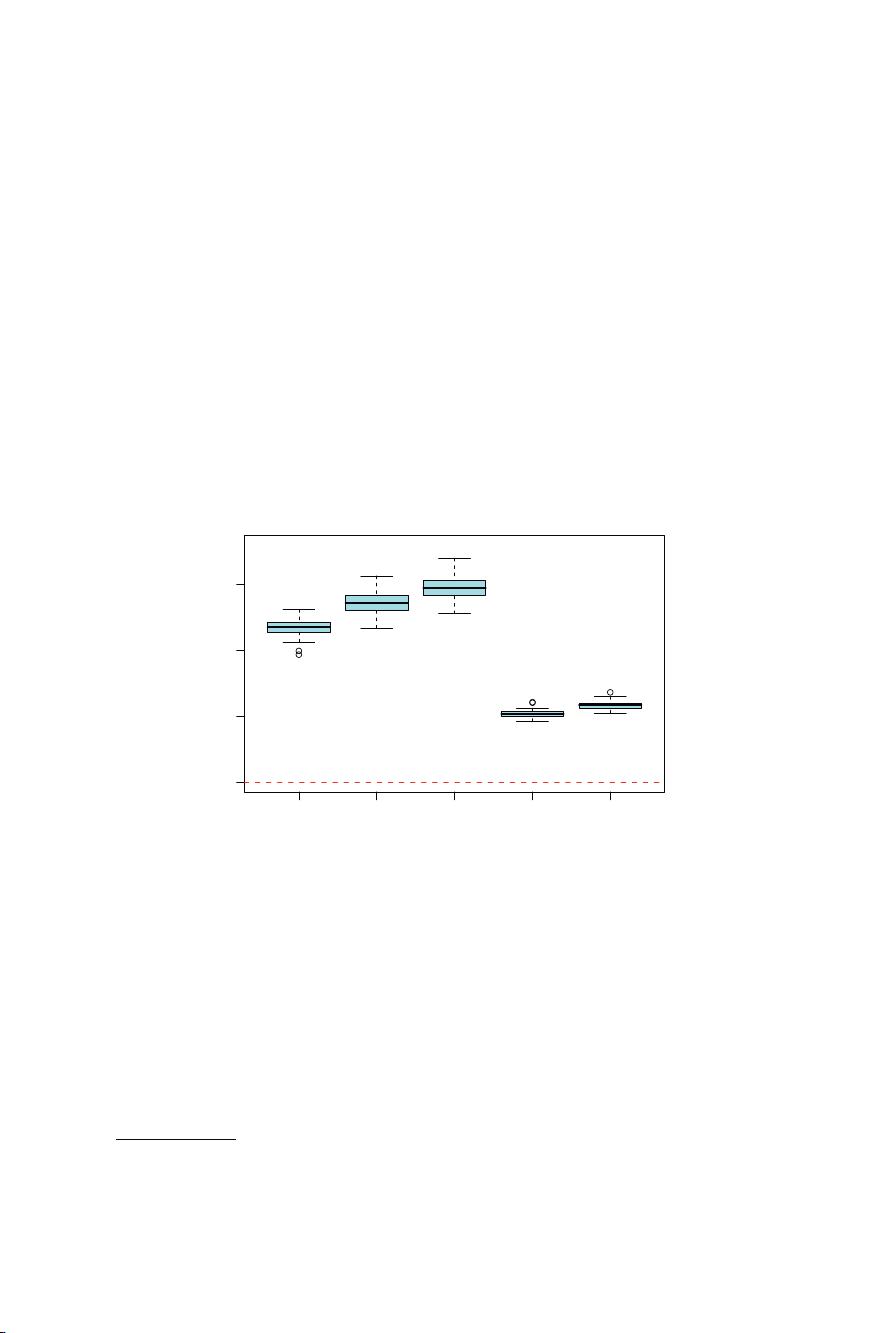
RF−1 RF−3 Bagging GBM−1 GBM−6
0.00 0.05 0.10 0.15
Nested Spheres
Test Misclassification Error
Bayes Error
FIGURE 15.2. The results of 50 simulations from the “nested spheres” model in
IR
10
. The Bayes decision boundary is the surface of a sphere (additive). “RF-3”
refers to a random forest with m =3, and “GBM-6” a gradient boosted model
with interaction order six; similarly for “RF-1” and “GBM-1.” The training sets
were of size 2000, and the test sets 10, 000.
Figure 15.1 shows the test-error progression on 2500 trees for the three
methods. In this case there is some evidence that gradient boosting has
started to overfit, although 10-fold cross-validation chose all 2500 trees.
1
Sadly, Leo Breiman died in July, 2005.
2
http://www.math.usu.edu/∼adele/forests/
剩余17页未读,继续阅读
235 浏览量
点击了解资源详情
点击了解资源详情
118 浏览量
132 浏览量
122 浏览量
2010-02-07 上传
2010-02-07 上传
106 浏览量

普通网友
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 华为编程规范与实践指南
- 电脑键盘快捷键全解析:速成操作指南
- 优化JFC/Swing数据模型:减少耦合与提高效率
- JavaServerPages基础教程 - 初学者入门
- Vim 7.2用户手册:实践为王,提升编辑技能
- 莱昂氏UNIX源代码分析 - 深入操作系统经典解读
- 提高单片机编程效率:C51编译器中文手册详解
- SEO魔法书:提升搜索引擎排名的秘籍
- Linux Video4Linux驱动详解:USB摄像头的内核支持与应用编程
- ArcIMS Java Connector二次开发指南
- Java实现汉诺塔算法详解
- ArcGISServer入门指南:打造企业级Web GIS
- 从零开始:探索计算机与系统开发的发现之旅
- 理解硬件描述语言(HDL):附录A
- ArcGIS开发指南:ArcObjects与AML基础编程
- 深入浅出Linux:RedHat命令手册解析
