SVM支持向量机在手写数字识别中的应用
需积分: 12 52 浏览量
更新于2024-08-04
1
收藏 284KB DOC 举报
"该文档详细介绍了基于SVM(支持向量机)的手写数字识别系统的设计与实现。主要内容包括系统的工作描述、流程、硬件和软件环境、数据集、特征提取和分类过程,以及部分程序代码。"
在手写数字识别领域,支持向量机(Support Vector Machine, SVM)是一种广泛应用的机器学习算法。SVM通过构造最优分类超平面来实现分类,尤其适用于小样本和高维空间的数据。在这个系统中,研究者主要针对手写数字图像进行识别,这在许多应用场景中具有实际价值,比如银行支票自动处理、邮政编码识别等。
系统的工作流程大致分为以下几个步骤:
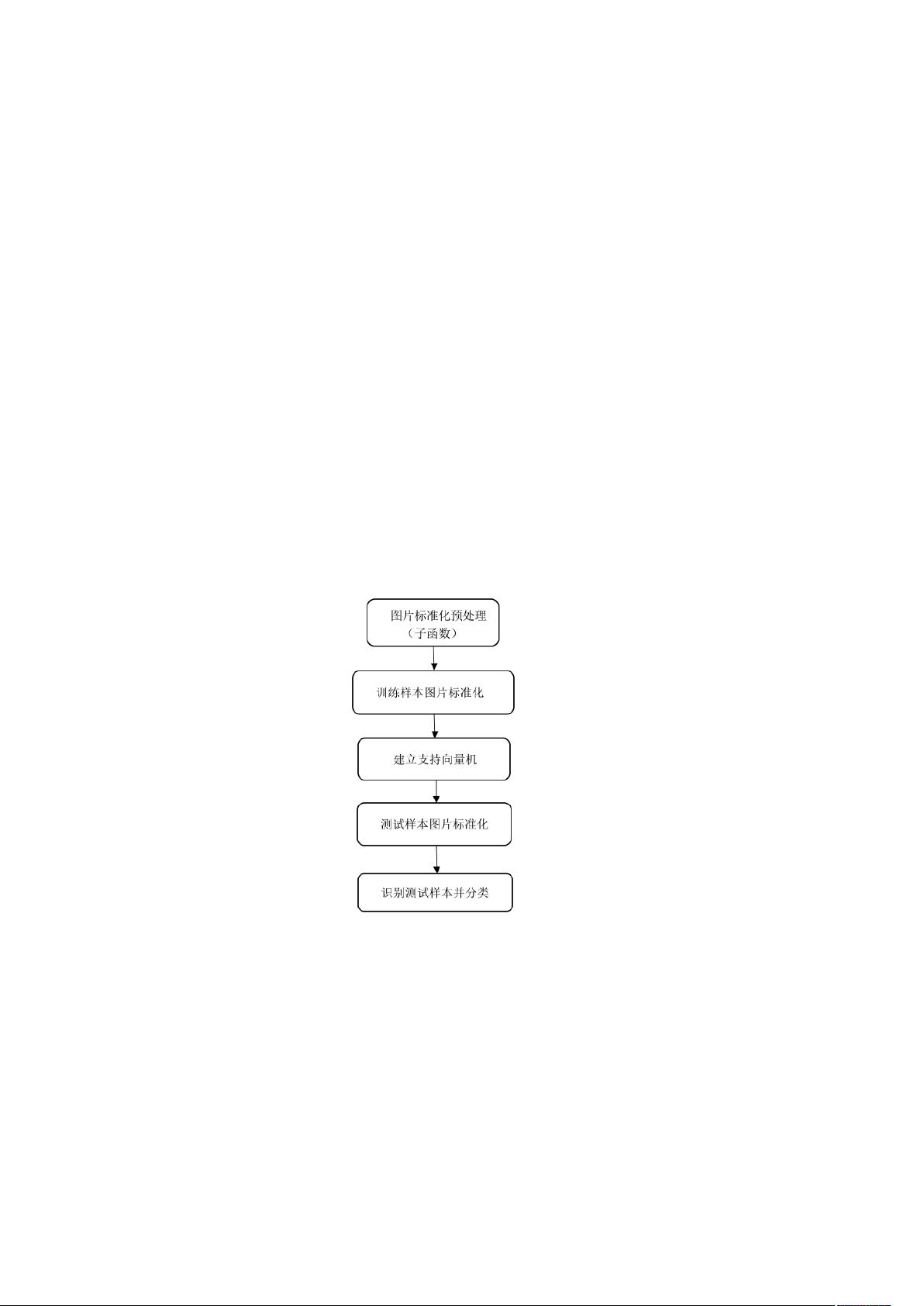
1. 预处理:首先,对手写数字图片进行标准化处理,包括反色、二值化以及截取包含完整数字的最小区域,将其转换为16*16像素的标准化图像。这个过程有助于减少噪声和增强数字特征的可识别性。
2. 特征提取:通过将标准化后的图像转化为16*16的二维数组,可以将每个像素看作一个特征,从而形成一个256维的特征向量。这种特征表示方式简化了原始图像的复杂度,便于后续的分类操作。
3. 训练模型:使用Matlab2016b环境,结合50张训练样本(每数字5张),构建SVM模型。这些训练样本被转换为50*256的训练样本矩阵,用于训练SVM分类器。训练过程中,通过调整阈值和核函数参数,寻找最优分类边界,以提高识别准确性。
4. 测试与分类:对30张测试样本(每数字3张)进行相同的预处理和特征提取,然后使用训练好的SVM模型进行识别分类。将测试样本的标准化图像转化为30*256的样本矩阵,输入到SVM中进行预测,得出对应的手写数字。
代码段`pic_preprocess`展示了预处理部分的关键操作,包括反色、二值化和最小区域截取,这些操作有效地提取了数字的核心特征,为后续的分类提供了基础。
这个基于SVM的手写数字识别系统展示了如何利用机器学习技术解决图像识别问题,特别是在有限的训练样本下,SVM能有效地构建模型并进行高精度的分类。然而,实际应用中可能需要更大的数据集和更复杂的特征工程,以应对更大范围的手写风格变化和提高整体识别性能。此外,还可以考虑集成其他机器学习算法或者深度学习模型,如卷积神经网络(CNN),以进一步提升识别效果。
基于 SVM 的手写数字识别系统的设计与实现
1.1 题目的主要研究内容
(1)工作的主要描述
手写数字识别是指给定一系列的手写数字图片以及对应的数字标签,构建
模型进行学习,目标是对于一张新的手写数字图片能够自动识别出对应的数字。
手写数字的识别在社会经济中的许多方面都有着广泛的应用,其识别方法也有许
多种,如神经网络,Bayes 判别法等。由于手写体人为因素随意性大,手写字体
识别的难度远高于印刷体的识别。本文主要基于 SVM(支持向量机),对手写数
字进行了识别分类
(2)系统流程图
┆
1.2 题目研究的工作基础或实验条件
(1)硬件环境主要为:戴尔笔记本,Intel(R) Core(TM) i5-7200U CPU
(2)软件环境主要为 Windows 操作系统,Matlab2016b。
1.3 数据集描述
训练样本为 50 张 0~9 的手写数字图片,每个数字均 5 张;
测试样本为 30 张 0~9 的手写数字图片,每个数字均 3 张。
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-10-19 上传
2022-10-19 上传
2023-09-16 上传
2022-10-19 上传
2022-10-19 上传
点击了解资源详情

李逍遥敲代码
- 粉丝: 2995
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







最新资源
- DS1302中文资料
- STC89C52RC 中文数据手册
- Oracle权限管理
- swing 官方网 教程
- FckEditor帮助文档
- i2c协议(中文版).pdf
- ubuntu完美应用
- Packt.Publishing.Smarty.PHP.Template.Programming.and.Applications.Mar.2006.pdf
- ColdFusion_Security
- 配送中心建设的若干问题研究
- thinking in java 中文版
- 字节对齐详解,真的很有用地啊
- DLL(动态链接库)专题
- Dynamips+使用手册+V1.00
- Windows藍屏死機代碼完全解析
- ☆精品资料大放送☆.pdf
