Pandas入门:Series与DataFrame基础与文件操作
需积分: 0 181 浏览量
更新于2024-08-31
收藏 229KB PDF 举报
Pandas是Python编程中强大的数据分析库,它建立在Numpy库之上,提供了高级数据结构和工具,特别强调Series和DataFrame这两种核心数据结构。Series是一维的有序数据集合,类似于一维数组,每个元素都有唯一的标签(索引),支持重复索引。Series的主要组成部分包括值(values)、索引(index)、名称(name)和数据类型(dtype)。例如,可以通过`pd.Series()`函数创建一个随机浮点数Series,指定索引和名称。
DataFrame则是二维表格型数据结构,类似于电子表格或SQL表,包含多列数据,每列可以是不同的数据类型。DataFrame提供了丰富的数据操作功能,如合并、分组、过滤等。在Pandas中,文件读取和写入是常用操作,它支持CSV(`pd.read_csv()`)、TXT(`pd.read_table()`)和Excel(`pd.read_excel()`)等多种格式。数据存储时,可以使用`to_csv()`和`to_excel()`方法将DataFrame写入相应的文件,例如去除行索引或指定输出的工作表名称。
在基础数据操作中,除了文件I/O,还包括对Series和DataFrame的基本操作。比如,创建Series时,可以设置默认值、索引、名称和数据类型。访问Series属性时,可以直接通过`.`运算符获取,例如`s.index`获取索引,`s.name`获取名称等。
Pandas的版本管理也很重要,通过`import pandas as pd`导入模块后,可以使用`pd.__version__`来检查当前的Pandas版本,如1.0.1。学习Pandas时,熟悉这些基础知识并实践操作,能够帮助你快速上手数据分析任务。随着对Pandas的深入,你还将掌握更多的高级功能,如数据清洗、数据转换、统计分析和可视化等,这些都是在实际项目中非常实用的技能。
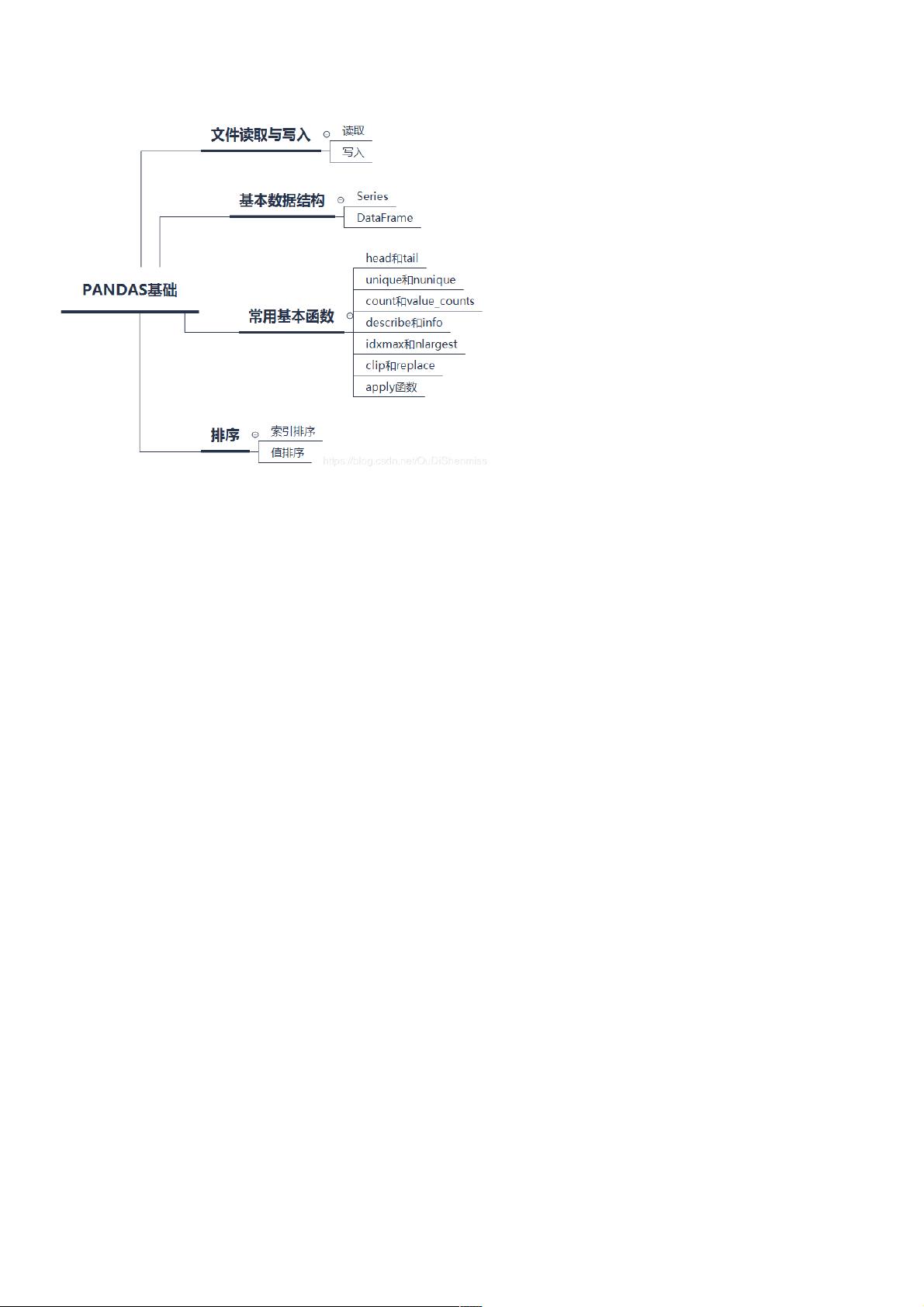
Pandas基础知识入门基础知识入门
Pandas是基于Numpy构建的含有更高级数据结构和工具的数据分析包。类似于Numpy的核心是ndarray,pandas 也是围绕着 Series 和 DataFrame两个核心数据结构展开的。Series
和 DataFrame 分别对应于一维的序列和二维的表结构。
Pandas官方教程User Guide ,查看当前版本:
>>> import pandas as pd
>>> import numpy as np
>>> print(pd.__version__)
1.0.1
文件读取与写入文件读取与写入
1、文件读取、文件读取
>>> df = pd.read_csv('data/table.csv') # csv格式
>>> df_txt = pd.read_table('data/table.txt') # txt格式
>>> df_excel = pd.read_excel('data/table.xlsx') #xls或xlsx格式,需要安装xlrd包
2、写入文件、写入文件
>>> df.to_csv('data/new_table.csv') # csv格式
>>> df.to_csv('data/new_table.csv', index=False) # 保存时除去行索引
>>> df.to_excel('data/new_table2.xlsx', sheet_name='Sheet1') # xls或xlsx格式,需要安装openpyxl
基本数据结构基本数据结构
1、、Series
一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。注意:Series中的索引值是
可以重复的。
A. 创建创建Series
对于一个Series,其中最常用的属性为值(values),索引(index),名字(name),类型(dtype)。
>>> s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'],name='Series Sample',dtype='float64')
>>> print(s)
a -0.509401
b -0.684058
c -0.759703
d 0.089692
e -0.114861
Name: Series Sample, dtype: float64
B. 访问访问Series属性属性
>>> s.values
array([-0.50940132, -0.68405815, -0.75970341, 0.08969204, -0.11486061])
>>> s.index
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
>>> s.name
'Series Sample'
>>> s.dtype
dtype('float64')
C. 索引元素索引元素
>>> s['a'] -0.5094013170899359
D. 调用方法调用方法
Series有相当多的方法可以调用:
>>> print([attr for attr in dir(s) if not attr.startswith('_')])
['T', 'a', 'abs', 'add', 'add_prefix', 'add_suffix', 'agg', 'aggregate', 'align', 'all', 'any', 'append', 'apply', 'argmax', 'argmin', 'argsort', 'array', 'asfreq', 'asof', 'astype', 'at', 'at_time', 'attrs', 'autocorr', 'axes', 'b', 'between',
'between_time', 'bfill', 'bool', 'c', 'clip', 'combine', 'combine_first', 'convert_dtypes', 'copy', 'corr', 'count', 'cov', 'cummax', 'cummin', 'cumprod', 'cumsum', 'd', 'describe', 'diff', 'div', 'divide', 'divmod', 'dot', 'drop', 'drop_duplicates',
'droplevel', 'dropna', 'dtype', 'dtypes', 'duplicated', 'e', 'empty', 'eq', 'equals', 'ewm', 'expanding', 'explode', 'factorize', 'ffill', 'fillna', 'filter', 'first', 'first_valid_index', 'floordiv', 'ge', 'get', 'groupby', 'gt', 'hasnans', 'head', 'hist', 'iat',
'idxmax', 'idxmin', 'iloc', 'index', 'infer_objects', 'interpolate', 'is_monotonic', 'is_monotonic_decreasing', 'is_monotonic_increasing', 'is_unique', 'isin', 'isna', 'isnull', 'item', 'items', 'iteritems', 'keys', 'kurt', 'kurtosis', 'last',
'last_valid_index', 'le', 'loc', 'lt', 'mad', 'map', 'mask', 'max', 'mean', 'median', 'memory_usage', 'min', 'mod', 'mode', 'mul', 'multiply', 'name', 'nbytes', 'ndim', 'ne', 'nlargest', 'notna', 'notnull', 'nsmallest', 'nunique', 'pct_change',
'pipe', 'plot', 'pop', 'pow', 'prod', 'product', 'quantile', 'radd', 'rank', 'ravel', 'rdiv', 'rdivmod', 'reindex', 'reindex_like', 'rename', 'rename_axis', 'reorder_levels', 'repeat', 'replace', 'resample', 'reset_index', 'rfloordiv', 'rmod', 'rmul',
'rolling', 'round', 'rpow', 'rsub', 'rtruediv', 'sample', 'searchsorted', 'sem', 'set_axis', 'shape', 'shift', 'size', 'skew', 'slice_shift', 'sort_index', 'sort_values', 'squeeze', 'std', 'sub', 'subtract', 'sum', 'swapaxes', 'swaplevel', 'tail', 'take',
'to_clipboard', 'to_csv', 'to_dict', 'to_excel', 'to_frame', 'to_hdf', 'to_json', 'to_latex', 'to_list', 'to_markdown', 'to_numpy', 'to_period', 'to_pickle', 'to_sql', 'to_string', 'to_timestamp', 'to_xarray', 'transform', 'transpose', 'truediv',
'truncate', 'tshift', 'tz_convert', 'tz_localize', 'unique', 'unstack', 'update', 'value_counts', 'values', 'var', 'view', 'where', 'xs']
>>> s.mean()
-0.3956662892383938
2、、DataFrame
一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
A. 创建创建DataFrame
>>> df = pd.DataFrame({'col1':list('abcde'),'col2':range(5,10),'col3':[1.3,2.5,3.6,4.6,5.8]},
index=list('一二三四五'))
>>> df
下载后可阅读完整内容,剩余4页未读,立即下载
8352 浏览量
353 浏览量
360 浏览量
299 浏览量
194 浏览量
点击了解资源详情
247 浏览量
点击了解资源详情
点击了解资源详情

weixin_38733414
- 粉丝: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- Oracle数据库常用函数全面汇总与解析
- STM32F系列USB虚拟串口VCP驱动在PC端的实现
- 降雨雷达时空匹配的Matlab代码实现及数据准确性验证
- 教学用渐开线画线器设计文档发布
- 前端图像压缩工具:实现无需服务器的图片优化
- Python 2.7.16 AMD64版本安装文件解析
- VC6.0平台下的高斯混合模型算法实现
- 拼音输入辅助工具suggest实现中文提示功能
- Log4jAPI应用详解与配置操作说明
- 官方下载:最新PX4飞控Pixhawk v5硬件原理图
- 楔铁装置设计文档:截断破碎钢筋砼桩、柱或地梁
- 使用PHP实现Alertmanager与SMS API集成的Webhook
- springboot最简项目搭建教程及文件结构解析
- 纯JS实现的数学表达式计算与解析源码
- C#实现二维码生成与摄像头扫描功能
- Hibernate入门实践教程
