Spark技术解析:内存计算,快速通用的集群引擎
需积分: 5 110 浏览量
更新于2024-07-09
收藏 19.46MB DOCX 举报
"Spark学习文档概述了Spark的基本概念、历史、特点、通用性以及其可融合性,并介绍了Spark的核心组件——集群管理器。文档适用于初学者了解和掌握Spark的基础知识。"
Spark是一个由Apache维护的开源大数据处理框架,最初由UC Berkeley的AMP实验室在2009年开发,并于2010年开源。自那时起,Spark发展迅速,成为了Apache最活跃的项目之一,拥有众多贡献者。在2014年,Spark晋升为Apache的顶级项目,当前稳定版本为2.4.5。
Spark的主要特点是其快速的处理速度。相比Hadoop MapReduce,Spark通过内存计算提升了执行效率,速度可达到MapReduce的100倍,即使是基于硬盘的计算也比MapReduce快10倍以上。这得益于其DAG(有向无环图)执行引擎,它优化了数据流的处理。此外,Spark的易用性也是一个显著优点,支持Scala、Java、Python、R和SQL等多种编程语言,提供了80多种高性能算法,简化了并行应用的开发。Spark还拥有交互式的Python和Scala shell,便于快速原型开发。
Spark的通用性体现在它可以结合SQL、流处理、复杂分析等多种功能。其包含SQL和DataFrames库、机器学习库MLlib、图计算库GraphX以及实时流处理库Spark Streaming,允许开发者在一个应用中集成多种处理方式,降低了开发和运维的复杂度。
Spark的可融合性使其能很好地与其他开源工具配合,如使用Hadoop的YARN或Apache Mesos作为资源管理器,兼容HDFS、HBase等Hadoop生态中的数据存储系统,增强了其在大数据生态系统中的适应性。
在Spark架构中,集群管理器(ClusterManager)是一个关键组件,它负责资源分配和任务调度,使得Spark能够在多节点间弹性扩展,以适应不同规模的计算需求。Spark还支持不同的部署模式,包括本地模式、standalone模式、Hadoop YARN模式和Apache Mesos模式,这提供了更大的灵活性。
总结来说,Spark是一个强大且灵活的大数据处理框架,以其速度、易用性、通用性和可融合性赢得了广泛的应用。对于希望在大数据领域进行分析和处理的开发者,深入理解Spark的基本原理和操作将大有裨益。
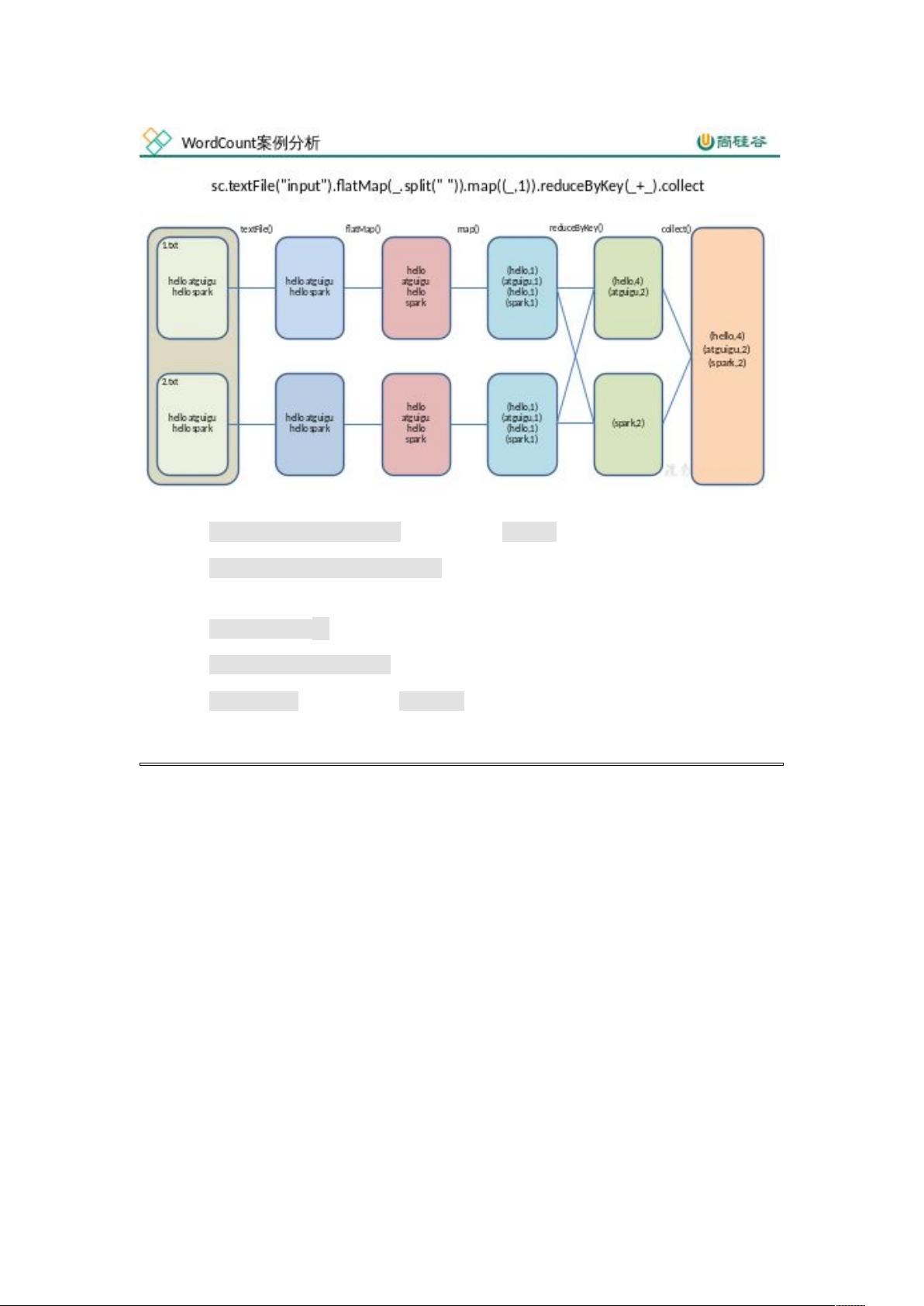
textFile("input"):读取本地文件 input 文件夹数据;
flatMap(_.split(" ")):压平操作,按照空格分割符将一行数据映射成
一个个单词;
2 map((_,1))
:
对每一个元素操作,将单词映射为元组;
7 reduceByKey(_+_):按照 将值进行聚合,相加;
8 collect:将数据收集到 Driver 端展示。
2.2 Spark 核心概念介绍
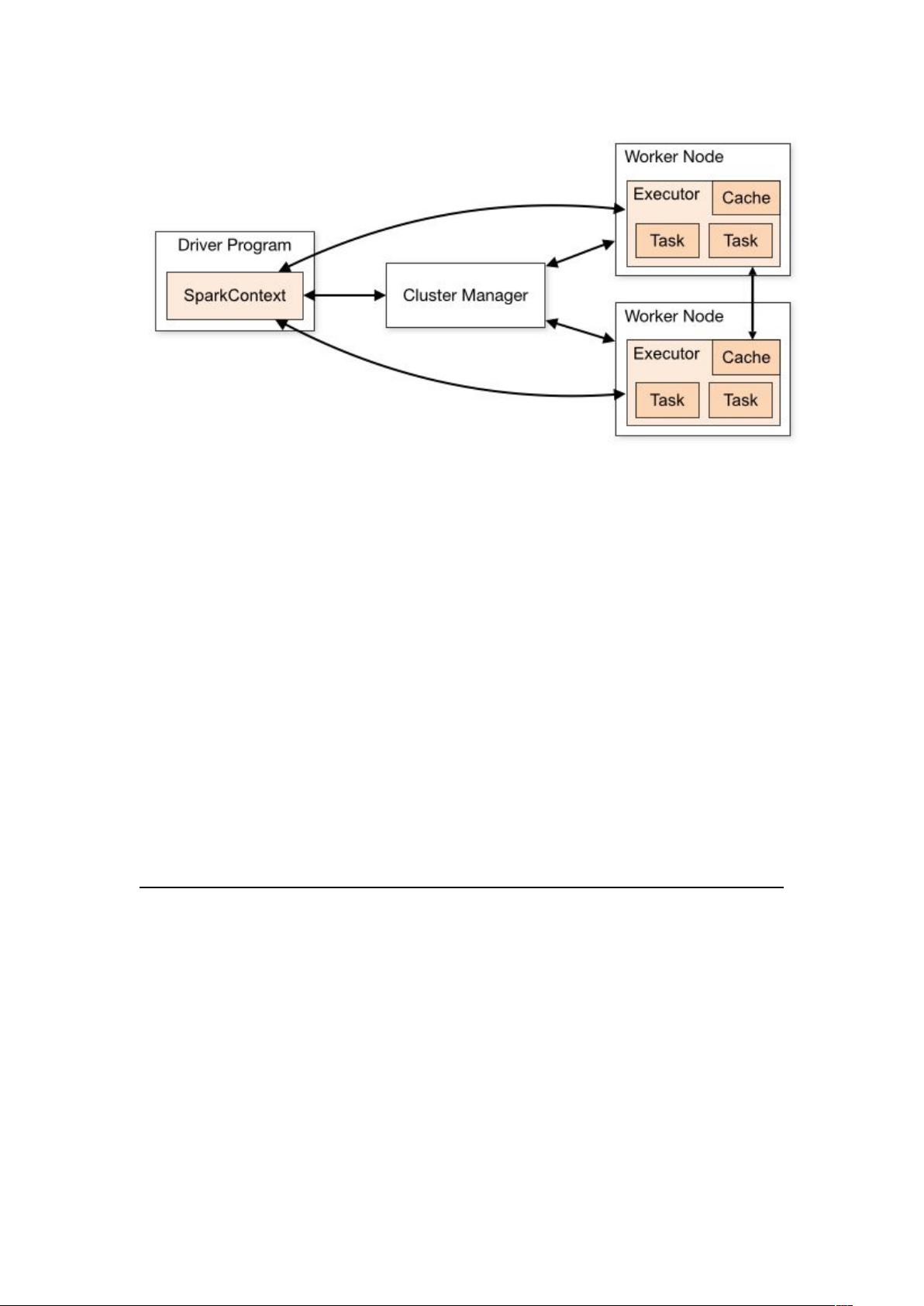
2.2.1 Master
特有资源调度系统的 ) 。掌管着整个集群的资源信息,类似于 .'框架中
的 !',主要功能:
1. 监听 Worker,看 Worker 是否正常工作;
2. Master 对 Worker、Application 等的管理(接收 Worker 的注册并管理所有的
Worker,接收 Client 提交的 Application,调度等待的 Application 并向
Worker 提交)。

剩余63页未读,继续阅读
2019-12-11 上传
2021-12-05 上传
2018-04-19 上传
2023-07-22 上传
2023-06-10 上传
2023-02-24 上传
2023-12-20 上传
2023-09-04 上传
2023-06-21 上传

AI小王子2022
- 粉丝: 119
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
