Apache Kylin:大数据分析引擎的亚秒查询利器
需积分: 13 174 浏览量
更新于2024-07-16
收藏 9.11MB DOCX 举报
Apache Kylin是一款专为大数据分析而设计的开源分布式分析引擎,其核心目标是提供Hadoop和Spark环境下的高效SQL查询能力,支持大规模数据的多维分析(OLAP)。该引擎最初由电子商务巨头eBay开发,并在开源社区得到了广泛应用。Kylin的V1.0版本包含了一系列关键组件和特性。
1.1 Kylin定义:
Kylin作为一个分析平台,为开发者提供了SQL查询接口,使得非技术背景的用户也能方便地进行数据分析。它专注于处理海量数据,能够在亚秒级别内对Hive表进行查询,显著提高了数据查询的性能和响应速度。
1.2 Kylin架构详解:
- REST Server:是Kylin的核心接口,允许开发者通过RESTful API来执行各种操作,如查询、构建立方体、获取元数据和权限管理,便于集成到应用程序中。
- 查询引擎:负责解析用户的SQL查询,与元数据管理工具和其他组件协同工作,提供结果。
- 路由器:原设计中曾计划将不适合处理的查询转给Hive,但实际应用中发现这会导致性能不一致,因此路由功能在稳定版本中被移除,以保持一致的用户体验。
- 元数据管理工具:这是Kylin的核心组成部分,用于管理和维护存储在HBase中的元数据,包括立方体元数据,确保整个系统的正常运行。
- 任务引擎(CubeBuildEngine):专门负责离线任务的处理,如Shell脚本、Java API和MapReduce任务,确保任务的执行和故障恢复。
1.3 Kylin的主要特点:
- SQL接口:Kylin采用标准SQL,使得数据分析更加简洁易用。
- 大数据支持:Kylin以其出色的性能,早在2015年就支持了亿级记录的秒级查询,尤其是在移动场景下,能够处理千万甚至千亿级别的数据量。
- 高效响应:亚秒级的查询响应时间,极大地提升了数据探索和决策支持的效率。
Apache Kylin是大数据分析领域的重要工具,它的设计注重于性能优化和易用性,适用于处理大规模数据集的复杂查询,尤其适合需要快速响应的实时业务场景。通过其标准化的SQL接口和高度扩展性,Kylin为数据分析师和业务用户提供了强大且灵活的数据分析平台。
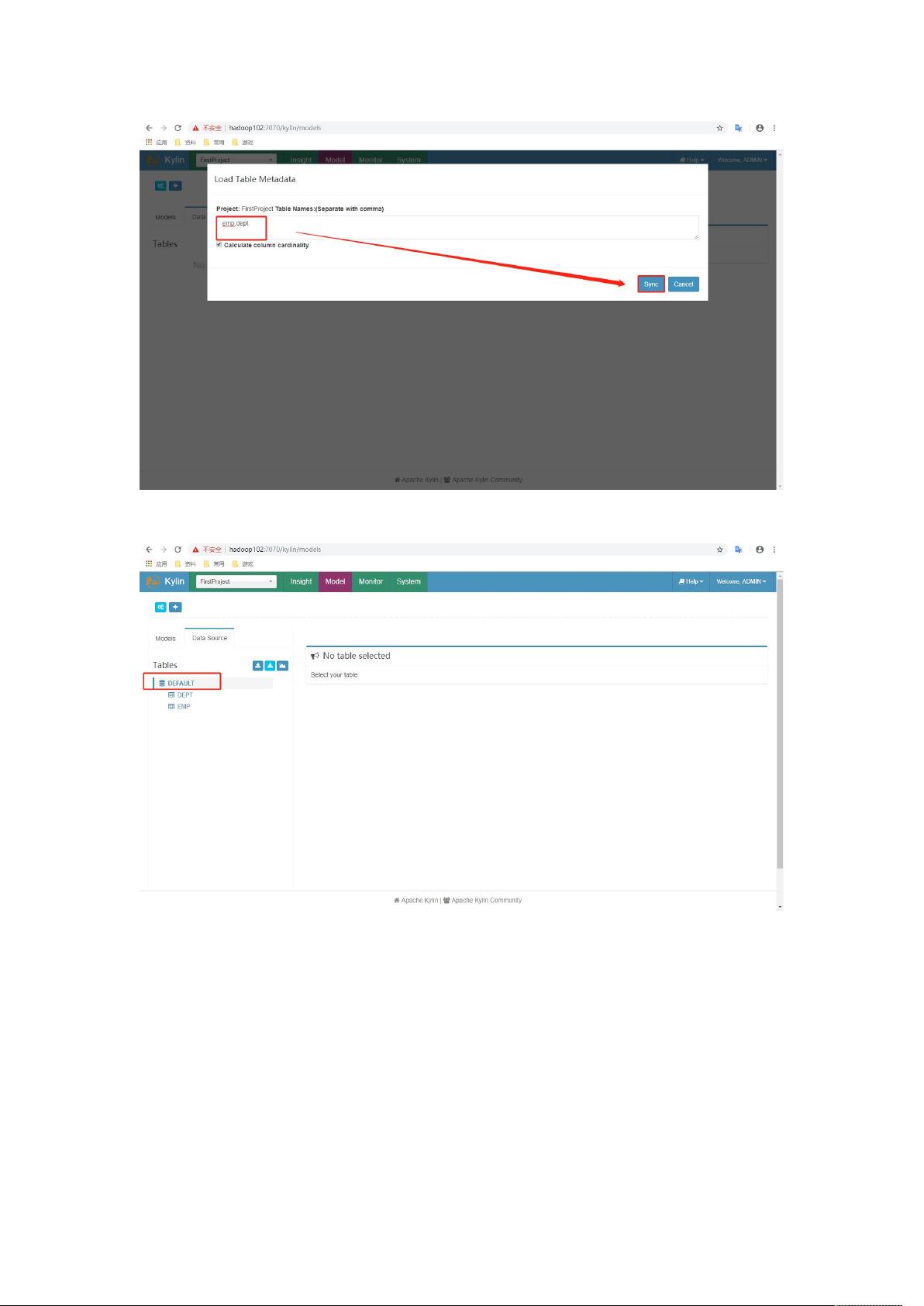
3)查看数据源
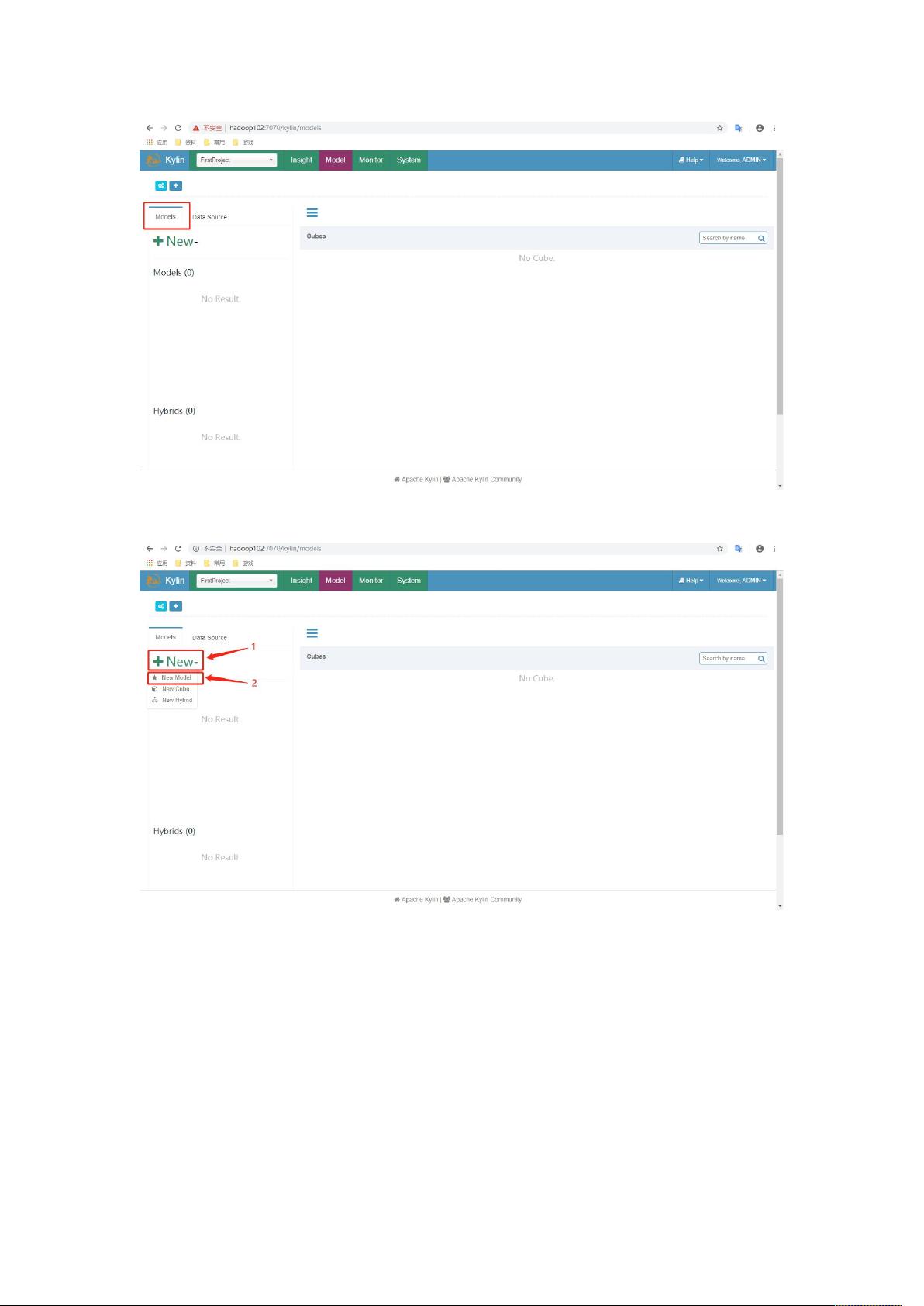
3.3 创建 Model
1)回到 Models 页面
剩余40页未读,继续阅读
2018-01-05 上传
2021-11-14 上传
2021-10-14 上传
2021-10-14 上传
2021-10-14 上传
2022-12-24 上传
2021-11-12 上传

feiyue_sparkle
- 粉丝: 0
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
