构建实时大数据分析平台:Kafka+FlumeNG+Storm+HBase架构详解
需积分: 12 24 浏览量
更新于2024-07-20
收藏 1.04MB PPTX 举报
本文档探讨了一种基于Kafka、FlumeNG、Storm和HBase的大数据架构设计,该架构旨在实现实时处理大规模数据集并满足复杂查询的需求。这种架构被划分为三个主要层次:SpeedLayer、ServingLayer和BatchLayer。
首先,SpeedLayer负责实时的处理和转发数据流,它是架构的最底层,确保数据的实时到达。它能够处理大量并发请求,并通过Kafka作为消息队列,将数据快速分发到后续的处理层。
FlumeNG在这个体系中可能扮演数据收集的角色,它负责从各种数据源采集数据,并将其高效地传输到Kafka。FlumeNG的高效性和可靠性对于实时数据流的捕获至关重要。
BatchLayer则是处理复杂查询和预计算的核心层。由于每次查询都需要重新执行在完整数据集上,批处理层的任务是对原始数据执行预计算,生成称为BatchView的结果。BatchView不仅包含了处理后的数据,还需要建立索引以支持快速的随机查询。然而,传统的Hadoop MapReduce模型不适合实时随机访问,因此BatchView通常存储在HDFS上,而非直接支持快速查询。
ServingLayer作为中间层,它的主要任务是建立BatchView的索引,以提供高效的服务层访问。由于BatchLayer的更新频率(如每日),ServingLayer的BatchView会定期刷新,但可能导致最新数据的实时性问题。理想的解决方案是选择一个分布式数据库,它能支持批量导入BatchView,以及高效的索引构建和随机读取。然而,现有的系统可能无法满足这种实时更新的要求。
SpeedLayer的存在就是为了弥补现有系统的不足,提供一个能够快速响应查询并及时反映最新数据变化的服务层。通过优化数据处理流程,这个架构设计有助于提高整体数据处理性能和响应速度,适应大数据时代的复杂业务需求。
总结来说,本文讨论的是如何通过Kafka的实时数据传输、FlumeNG的数据收集、Storm的实时计算和HBase的批处理与存储,以及分布式数据库(可能是NoSQL或关系型数据库)的索引支持,构建一个能满足实时查询、高效处理和复杂数据分析的大数据架构。每个组件都扮演着关键角色,共同构建了一个完整的数据处理和分析生态系统。

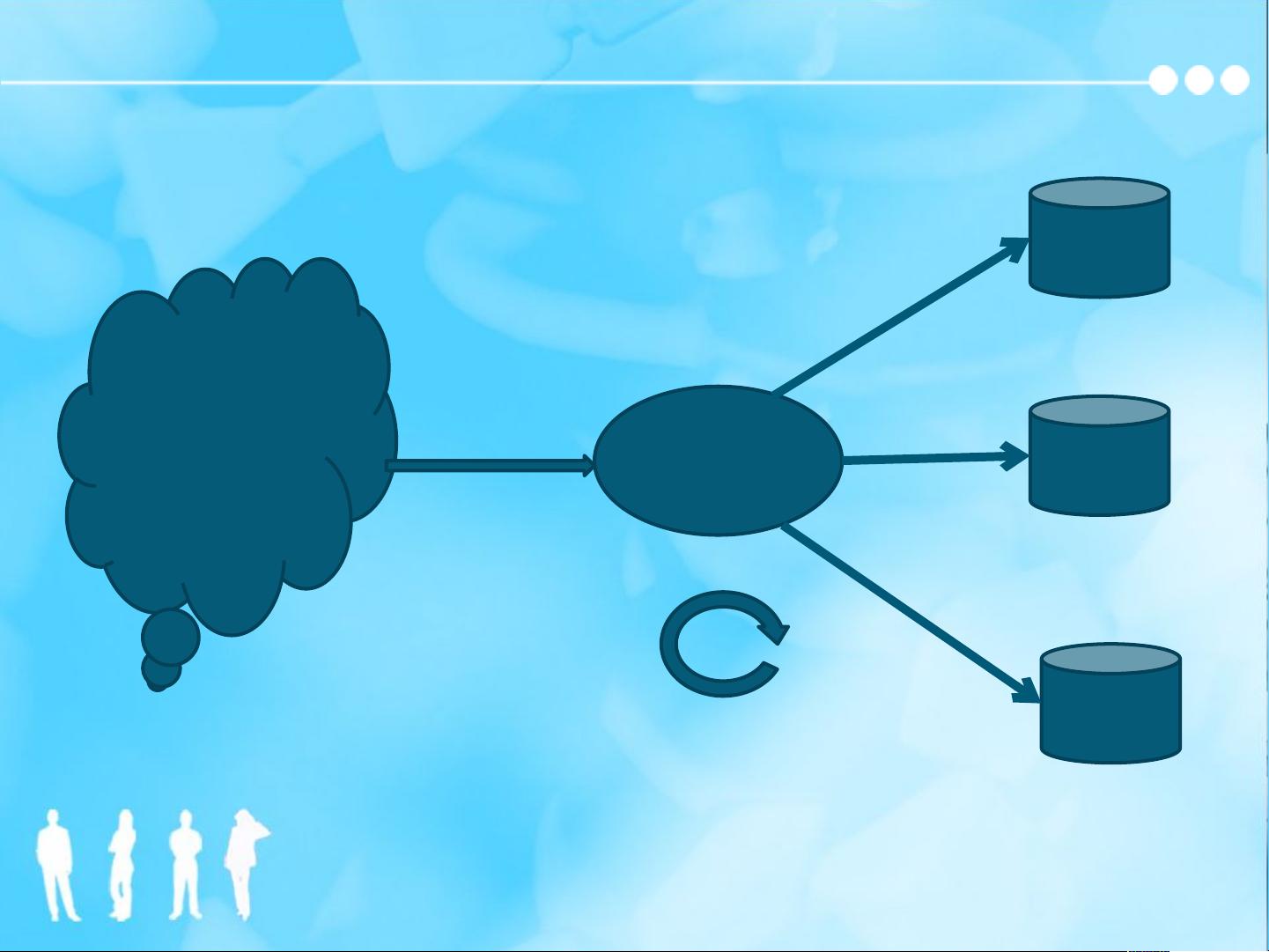
Batch Layer
批处理层的主要作用就是进行各种复杂的预计算,
预计算的结果称作 Batch View 。
再次查询时直接从 Batch View 中读取结果数据,为
了支持快速的随机的查询需求,需要对
Batch View 中的数据建立索引。
剩余39页未读,继续阅读
705 浏览量
点击了解资源详情
159 浏览量
187 浏览量
2024-03-04 上传
2939 浏览量

liuyang77886
- 粉丝: 24
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- 详细解析Java中抽象类和接口的区别
- ActionScript 3.0 Cookbook 中文完整版
- dwg文件说明文档(英文)
- c语言函数大全.pdf
- FLASH四宝贝之-使用ActionScript 3.0组件
- spring电子文档(官方)
- jstl电子文档。很有参考价值,我也找了很久跟大家分享
- JaVa课卷_ATM
- Linux初学者入门优秀教程
- ActionScript 3.0 Cookbook 中文完整版
- 中科大罗老师endnote讲义
- JavaMail 帮助 文档 pdf
- php5面向对象初步pdf格式
- 初学者必备 c语言实例50
- 让你不再害怕指针,详解指针的使用
- 嵌入式linux系统的设计与开发
