Hadoop大数据实战指南
需积分: 9 199 浏览量
更新于2024-07-20
收藏 3.12MB PDF 举报
"郭专老师的Hadoop大数据入门与实践课程,涵盖了从Hadoop的起源到实际应用的多个关键组件,如HDFS、MapReduce、Zookeeper、HBase和Hive等,还包括流式计算的Storm以及数据挖掘中的推荐系统。课程旨在帮助初学者快速掌握Hadoop生态系统,并提供实践经验,避免理论与实践的脱节。"
本文将详细阐述Hadoop入门与实践的相关知识点,包括Hadoop的版本衍化、生态圈,HDFS的特性和操作,MapReduce的编程模型和工作原理,Zookeeper的数据模型和应用场景,HBase的基础知识和架构,Hive的基础原理和操作,以及流式计算框架Storm的特性与实现,最后介绍数据挖掘中的推荐系统。
### 第一章 前言
课程目标是帮助新手迅速掌握大数据领域的核心技能,特别是Hadoop,强调实践性,避免只停留在理论层面。
### 第二章 Hadoop简介
1. **Hadoop版本衍化历史**:Hadoop从最初的0.1.x版本发展至今,经历了多次重大更新,形成了多个稳定版本,如Hadoop 1.x、2.x,每个版本都有其独特的功能增强和性能优化。
2. **Hadoop生态圈**:Hadoop生态包括HDFS、MapReduce、YARN、HBase、Hive、Zookeeper等众多组件,它们共同构建了大数据处理的完整框架。
### 第三章 安装Hadoop环境
这部分讲解如何在不同操作系统上搭建Hadoop运行环境,包括配置伪分布式和完全分布式模式。
### 第四章 HDFS文件系统
1. **HDFS特点**:高容错性、可扩展性、适合大规模数据存储。
2. **不适用于HDFS的场景**:小文件存储和低延迟读取需求。
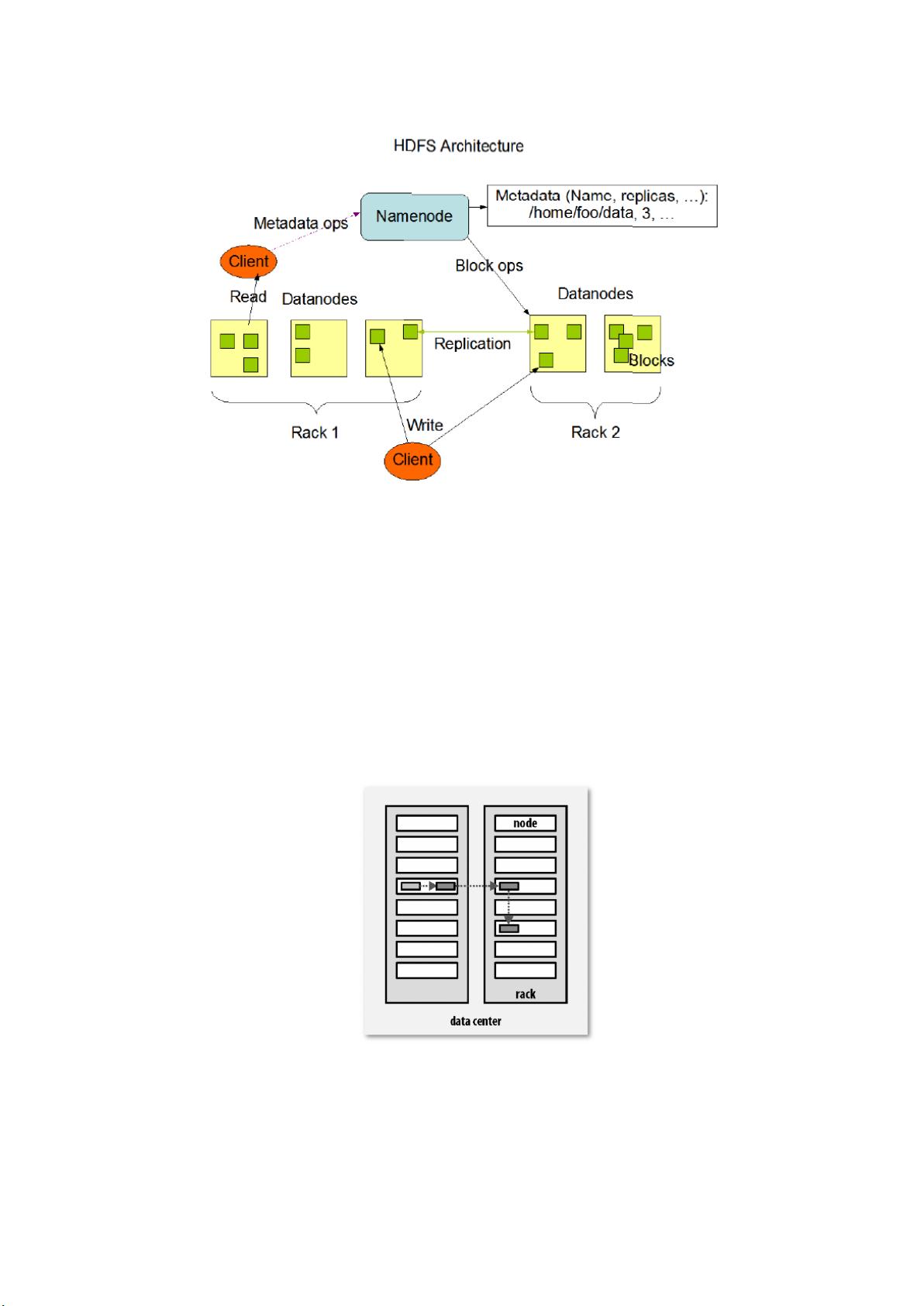
3. **HDFS体系架构**:包含NameNode、DataNode和Secondary NameNode等组件。
4. **HDFS数据块复制**:默认三副本策略,保证数据冗余和容错。
5. **HDFS读写流程**:描述数据的分块存储和读取过程。
6. **操作HDFS的基本命令**:如`hadoop fs -put`、`hadoop fs -get`等。
### 第五章 MapReduce计算框架
1. **MapReduce编程模型**:由Map和Reduce两个主要阶段组成。
2. **MapReduce执行流程**:输入切片、Map任务执行、Shuffle与Sort、Reduce任务执行。
3. **数据本地化**:提高效率,尽可能让数据计算在数据所在的节点上进行。
4. **MapReduce工作原理**:详细解释MapReduce的整个生命周期。
5. **错误处理机制**:如任务失败后的重试策略。
### 第六章 Zookeeper
1. **Zookeeper数据模型**:ZNode结构、路径命名规则和数据版本。
2. **Zookeeper访问控制**:提供权限控制,保障服务安全。
3. **Zookeeper应用场景**:如Hadoop集群管理、分布式锁、配置中心等。
### 第七章 HBase
1. **Hbase简介**:列式存储、实时查询的NoSQL数据库。
2. **Hbase数据模型**:行、列族、列和时间戳的概念。
3. **Hbase架构及基本组件**:RegionServer、Master、HLog等。
4. **Hbase容错与恢复**:Region分裂、故障转移机制。
5. **Hbase基础操作**:增删查改等操作。
### 第八章 Hive
1. **Hive基础原理**:基于Hadoop的SQL-like查询工具,用于离线数据分析。
2. **Hive基础操作**:创建表、加载数据、执行查询等。
### 第九章 Storm
1. **Storm特点**:实时处理、高吞吐、容错性强。
2. **Storm与Hadoop区别**:Hadoop侧重批处理,Storm专注于流处理。
3. **Storm基本概念**:Tuples、Spouts、Bolts等。
4. **Storm系统架构**:包括Nimbus、Supervisor、Worker等组件。
5. **Storm容错机制**:通过检查点和故障恢复确保数据不丢失。
6. **简单Storm实现**:演示一个基础的实时数据处理拓扑。
7. **Storm常用配置**:优化Storm性能的关键参数。
### 第十章 数据挖掘——推荐系统
1. **数据挖掘和机器学习概念**:作为推荐系统的基础。
2. **推荐领域**:机器学习在个性化推荐中的应用。
3. **基于内容的推荐方法**:通过分析用户历史行为和物品特征进行推荐。
4. **基于协同过滤的推荐方法**:利用用户之间的相似性进行预测。
以上内容全面介绍了Hadoop及其生态系统,从理论到实践,为学习者提供了丰富的学习资源,有助于快速理解和掌握大数据处理的关键技术。

如果一切正常,应当有如上的一些进程存在。
7) 测试系统
输入./hadoop fs –ls /
能正常显示文件系统。
如此,hadoop 系统搭建完成。否则,可以去/home/hadoop/hadoop-1.2.1/logs 目
录下,查看缺少的进程中,对应的出错日志。
第四章 HDFS 文件系统
Hadoop 附带了一个名为 HDFS(Hadoop 分布式文件系统)的分布式文件系统,专门
存储超大数据文件,为整个 Hadoop 生态圈提供了基础的存储服务。
本章内容:
1) HDFS 文件系统的特点,以及不适用的场景
2) HDFS 文件系统重点知识点:体系架构和数据读写流程
3) 关于操作 HDFS 文件系统的一些基本用户命令
1. HDFS 特点:
HDFS 专为解决大数据存储问题而产生的,其具备了以下特点:
1) HDFS 文件系统可存储超大文件
每个磁盘都有默认的数据块大小,这是磁盘在对数据进行读和写时要求的最小单位,


剩余83页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-05-17 上传
2014-07-03 上传
2019-07-23 上传
2009-11-24 上传
2014-03-01 上传

everysummer
- 粉丝: 4
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
