Ceph PG状态机与创建流程详解
需积分: 9 199 浏览量
更新于2024-09-07
收藏 386KB PDF 举报
"这篇文档详细介绍了Ceph中的PG(Placement Group)状态机及其状态变迁,以及PG的创建流程。文章基于Boost库实现的状态机模型,阐述了PG如何处理不同状态间的转换,并深入解析了PG的创建和peering过程。"
在Ceph分布式存储系统中,Placement Group(PG)是数据分片和故障恢复的基本单位。PG状态机是用于管理PG状态变化的核心机制,它基于Boost库的状态机实现,确保高效、准确地处理多个PG状态之间的转换。状态机由一系列状态构成,每个状态可能有其特定的子状态,同时能够对特定事件做出响应,触发状态迁移。
状态机的组成部分包括:
1. **状态(State)**:对象在生命周期中的不同阶段,例如,一个PG可能处于干净(clean)、不一致(inconsistent)或在恢复(recovering)等状态。
2. **事件(Event)**:触发状态迁移的条件,比如新的数据写入、故障检测或恢复操作等。
3. **状态变迁(State Transition)**:当状态遇到事件时,根据预定义的规则进行状态转移。
例如,在Boost状态机中,`simple_state`结构体用来定义状态,`transition`关键字用来指定事件发生时的状态转换规则。一个状态可以对多个事件做出反应,使用`mpl::list`来定义多事件的反应规则。
PG的创建流程涉及以下步骤:
1. 用户通过Ceph命令创建一个新的Pool,指定PG的数量。
2. Ceph客户端(librados)封装一个`MSG_MON_COMMAND`消息,发送给Monitor节点。
3. Monitor接收到请求后,处理Pool创建的逻辑,包括分配PGID等。
4. Monitor将创建PG的任务分发给OSD(Object Storage Daemon),负责实际的数据存储。
5. OSD上的PGMonitor组件负责执行PG的创建,包括初始化数据结构,设置初始状态等。
6. 在PG创建过程中,还会涉及peering流程,即PG在多个OSD间建立通信和同步关系,确保数据的一致性和高可用性。
理解PG状态机和创建流程对于优化Ceph集群性能和确保数据可靠性至关重要。通过监控和调整PG的状态,管理员可以有效地应对数据增长、故障恢复和负载平衡等问题。
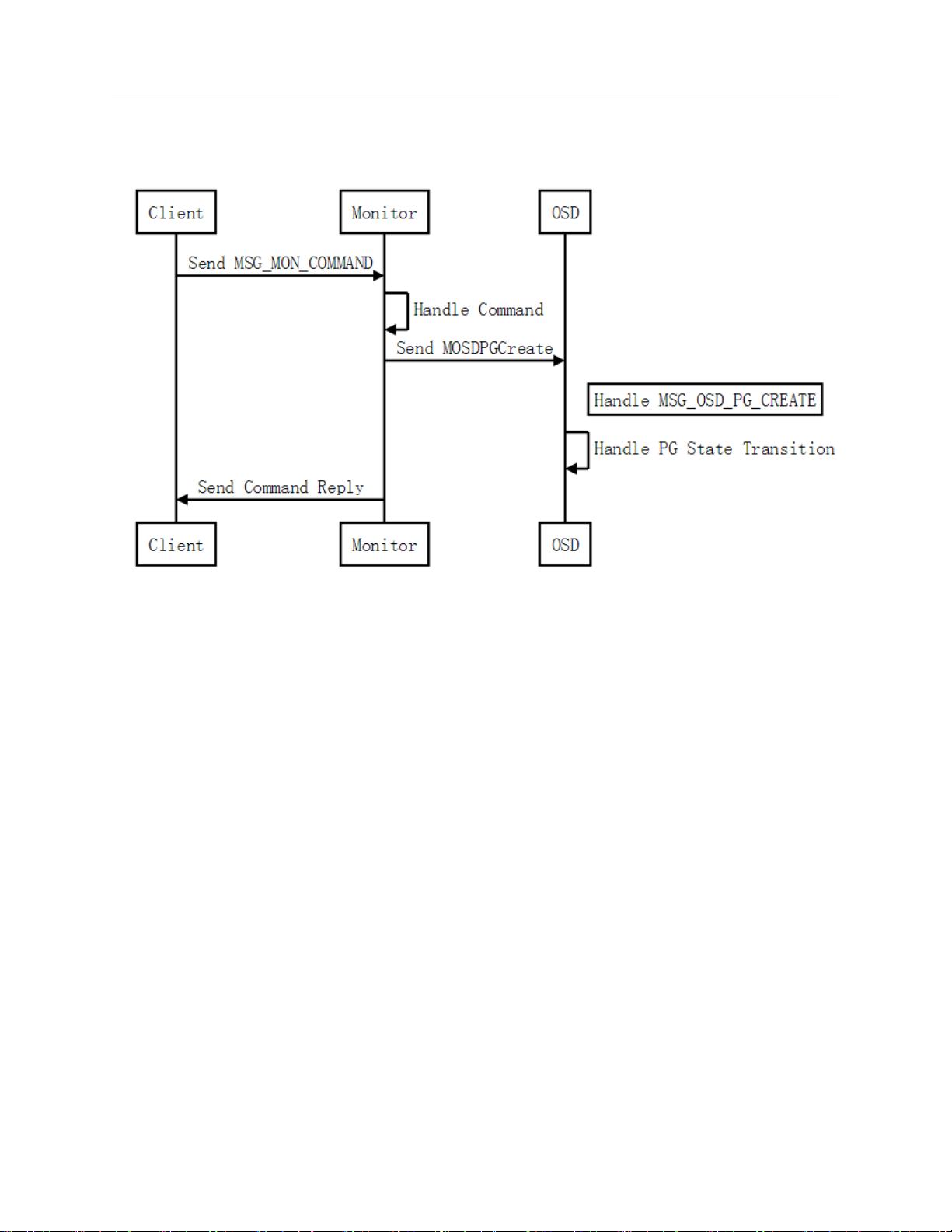
二、PG 创建流程 CEPH PG 状态机及状态变迁
二、PG 创建流程
如上图所示,当使用 Ceph 命令创建 pool 的时候,会指定 pg 的数量。Ceph 命令调用 librados,封装
MSG_MON_COMMAND 消息并发送给 Monitor 进行处理。最后,由 PGMonitor 完成处理并发送消息
MOSDPGCreate 给 OSD 进行处理
在 OSD 端接收到 PG 创建请求后,进入到 PG 的状态机中进行处理,由最初的 Initial 状态,经过
Creating,Creating+peering,Creating+Activing 等状态,最终达到 Active+Clean 状态。
3
剩余10页未读,继续阅读
2021-02-06 上传
2021-11-04 上传
2019-10-20 上传
2023-09-09 上传
2021-10-11 上传
2023-09-09 上传
2021-09-14 上传
2023-09-04 上传
2021-09-05 上传

shibinw
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索AVL树算法:以Faculdade Senac Porto Alegre实践为例
- 小学语文教学新工具:创新黑板设计解析
- Minecraft服务器管理新插件ServerForms发布
- MATLAB基因网络模型代码实现及开源分享
- 全方位技术项目源码合集:***报名系统
- Phalcon框架实战案例分析
- MATLAB与Python结合实现短期电力负荷预测的DAT300项目解析
- 市场营销教学专用查询装置设计方案
- 随身WiFi高通210 MS8909设备的Root引导文件破解攻略
- 实现服务器端级联:modella与leveldb适配器的应用
- Oracle Linux安装必备依赖包清单与步骤
- Shyer项目:寻找喜欢的聊天伙伴
- MEAN堆栈入门项目: postings-app
- 在线WPS办公功能全接触及应用示例
- 新型带储订盒订书机设计文档
- VB多媒体教学演示系统源代码及技术项目资源大全
