搜狗信息流推荐算法详解:架构与NLP应用
版权申诉
107 浏览量
更新于2024-07-05
收藏 3.86MB PDF 举报
本文档《3-2+搜狗信息流推荐算法综述.pdf》深入探讨了搜狗信息流推荐算法的各个方面,旨在提供一个全面的系统架构概述。该算法在现代信息技术中扮演着核心角色,通过个性化的内容推送,为用户提供高效的信息导航服务。
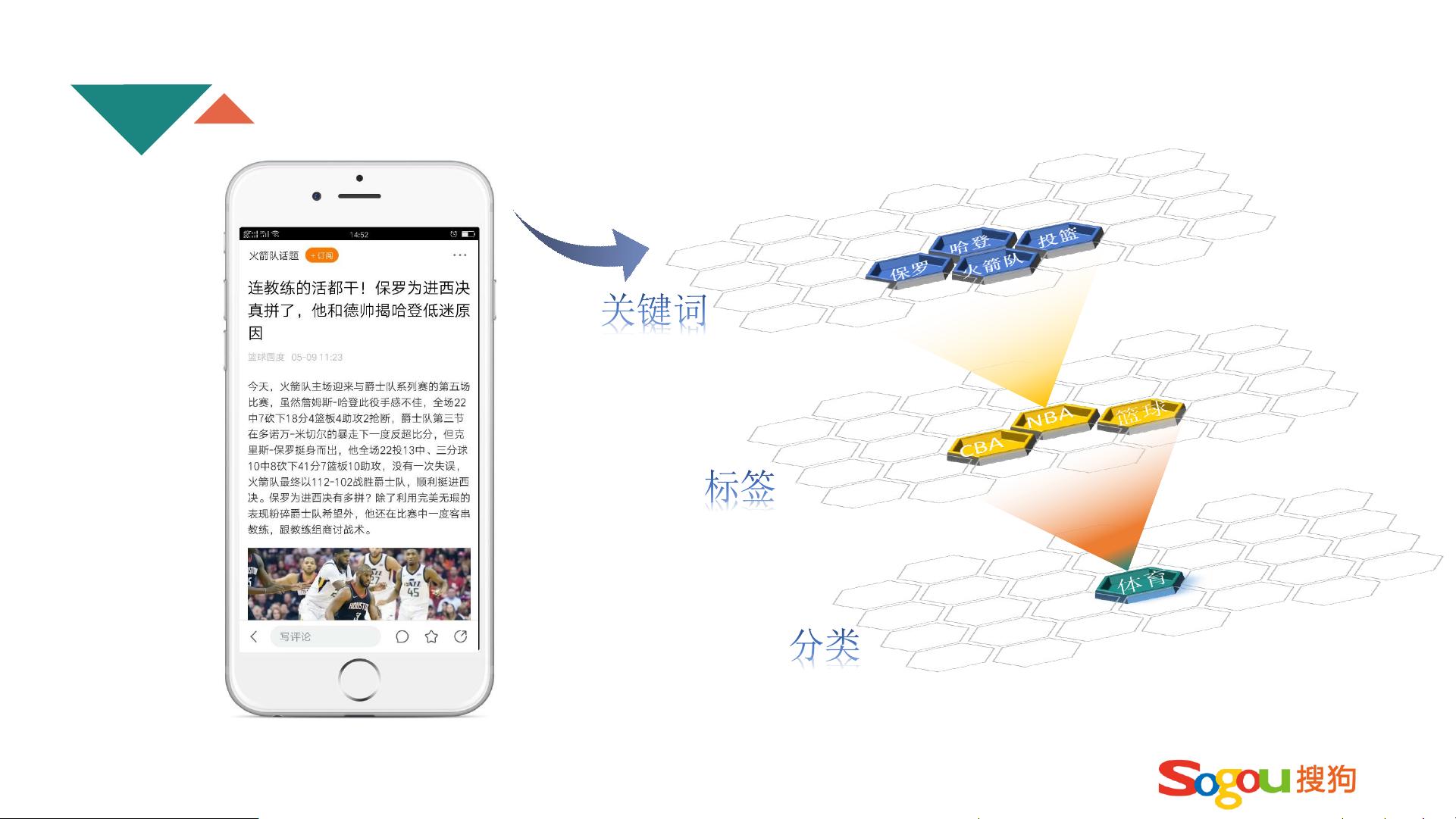
首先,文章着重于推荐系统的架构设计,包括了文章自然语言处理(NLP)的运用,这是理解用户需求的关键环节。通过NLP技术,算法能解析和理解用户的搜索查询,提取关键词和主题,从而进行内容的筛选和匹配。
接着,文章详细介绍了召回算法,区分了基于内容的召回(CB召回)和协同过滤召回(CF召回),两种方法分别依赖于用户的历史行为和相似用户的行为来预测潜在的兴趣。此外,还涵盖了其他可能采用的召回策略,如深度学习模型,以提高推荐的精准度。
个性化排序是推荐系统的核心功能,它通过考虑用户兴趣、行为历史、实时反馈等多个因素,对候选内容进行排序,确保最相关的信息优先呈现。算法可能会结合多种排序策略,如基于深度学习的排序模型,提升用户体验。
在数据展现处理部分,文中强调了用户画像的构建,通过收集和分析用户的个人信息、行为特征,形成用户独特的兴趣标签和偏好,以便更精准地推送定制化内容。内容的分类和标签管理是信息流的重要组成部分,文档列举了广泛的领域如娱乐、体育、财经等,并细化到子类别如电视剧、明星、赛事等,这有助于构建丰富且具有针对性的内容库。
模型训练方面,作者介绍了两种模型——FastText文本分类模型和TextCNN文本分类模型,这些模型旨在通过深度学习技术提高分类的准确性和效率。同时,模型融合也是一个亮点,通过将多个单一模型的准确率提升至96%,进一步优化了推荐效果。
这篇综述文档深入剖析了搜狗信息流推荐算法的各个方面,从推荐系统的基础结构到具体的算法策略,再到实际应用中的模型选择和优化,展示了其在满足用户个性化需求、提升用户体验方面的关键作用。这对于理解和研究推荐系统领域的专业人士来说,是一份极具价值的参考资料。
文章NLP
分类
标签
关键词
娱乐
体育
财经
港台
明星
综艺
NBA
足球
股票
房产
火箭队
乔丹
世界杯
英超
刘德华
周杰伦
跑男
吐槽
大会
顺鑫
控股
美股
房产
两限房
二手房
聚焦主要领域
为用户提供信息导航
描述比较精确,但又属于
抽象概念的语义
领域内热点人物、机构、
作品、产品等实体内容
剩余25页未读,继续阅读
2021-06-25 上传
2021-08-24 上传
2022-03-18 上传
2021-10-25 上传
2021-06-18 上传
2022-03-18 上传
2019-07-22 上传
2021-09-20 上传

普通网友
- 粉丝: 12w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
