Spark内核解析:部署模式与Shuffle深度揭秘
需积分: 9 193 浏览量
更新于2024-07-16
收藏 3.44MB PDF 举报
"Spark大数据内核天机解密- to 丁立清.pdf"
该文档深入讲解了Apache Spark的大数据处理核心机制以及性能调优的方法,是Spark开发者和研究者的宝贵资料。书中详细介绍了Spark的不同部署模式,从基础的local模式到分布式部署的Spark Standalone、Spark on YARN等,对每个模式的配置、工作原理和内部消息机制进行了深入剖析。
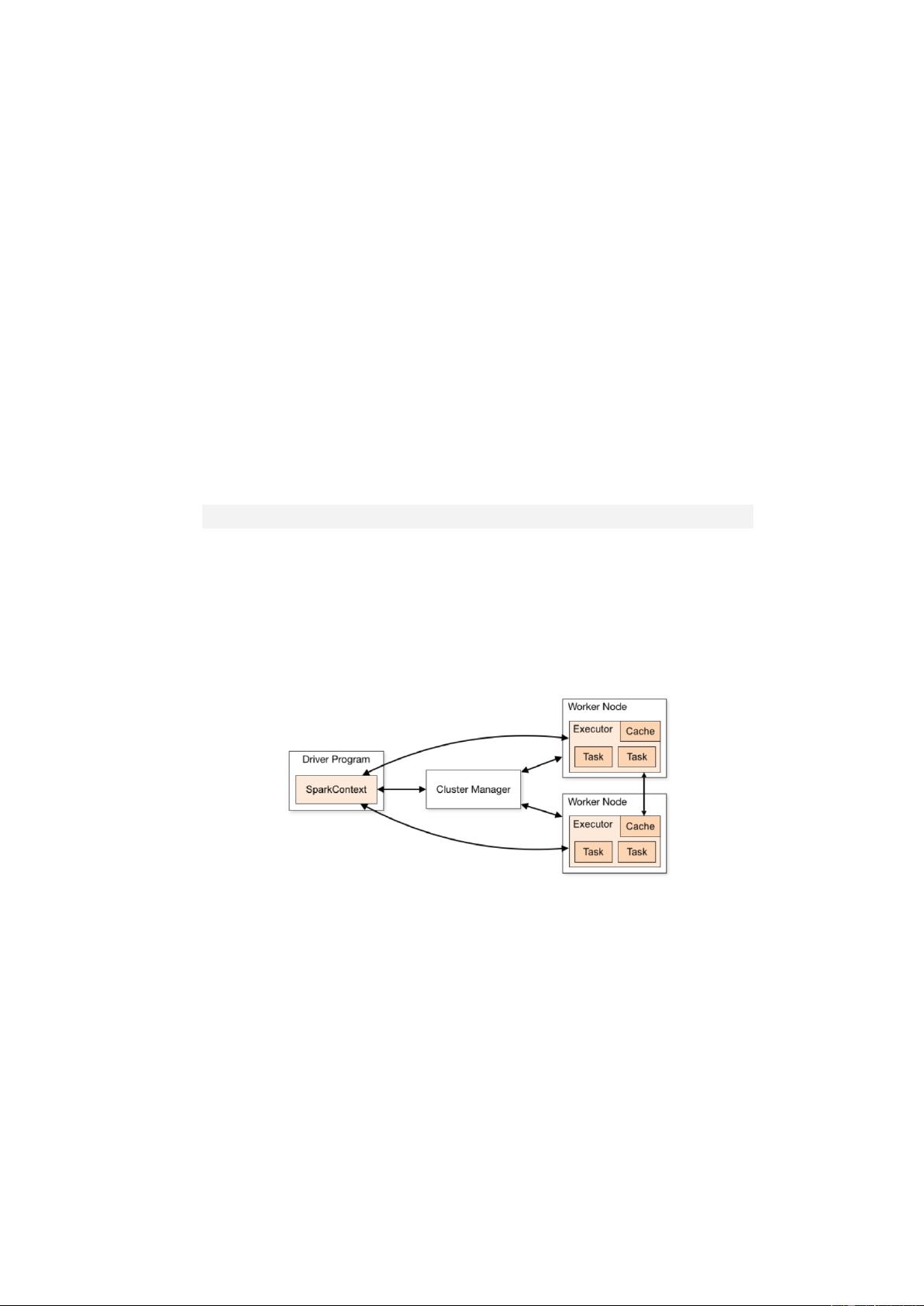
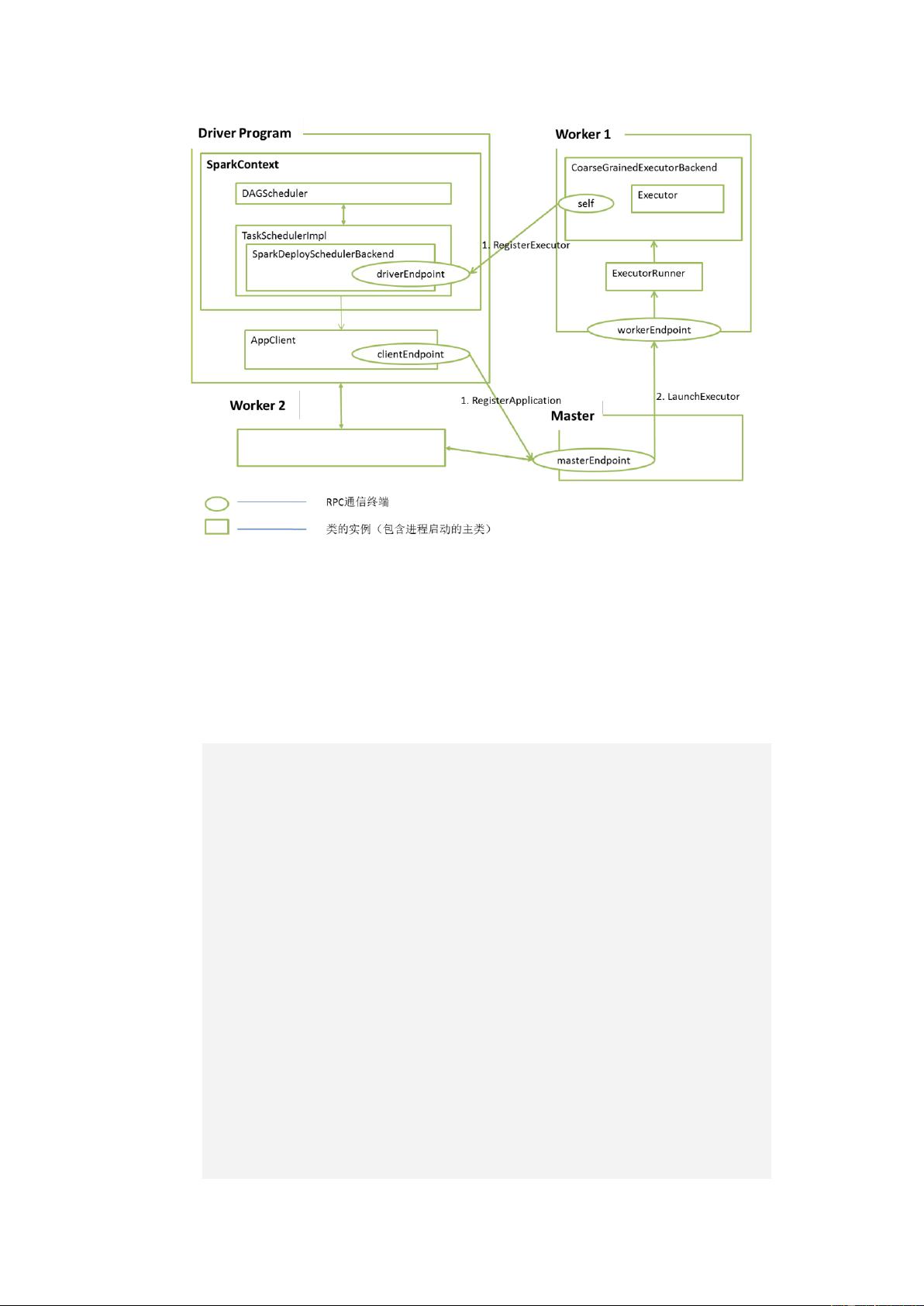
在部署模式部分,书中的第3章详细阐述了Spark应用程序的部署流程,包括脚本解析和源码分析。特别强调了local模式及其变体,如local[*]和local[N],这些模式在单机测试和小型实验中非常常见。接着,书中详细解读了local-cluster部署,介绍了如何配置executor的数量和内存,这对于理解和优化本地多线程测试环境至关重要。此外,还详述了Spark Standalone集群的部署,包括Master和Worker节点的设置,以及高可用性(HA)Master的部署,这些都是大规模生产环境中的关键步骤。
对于YARN(Hadoop的资源管理系统)上的Spark部署,书中也给出了详细的指导,包括YARN的部署架构和Spark应用程序在YARN上的运行方式,这对于那些已经拥有Hadoop集群的用户来说非常实用。
在Shuffle机制方面,书的第7章深入探讨了这一核心组件,它是Spark并行计算的关键环节。Shuffle过程涉及数据重排,确保数据能在正确的位置进行下一步计算。书中不仅介绍了Shuffle的演变历程和基本框架,还对不同类型的Shuffle,如HashBasedShuffle、SortedBasedShuffle以及TungstenSortedBasedShuffle的实现进行了源码级别的解析。这部分内容对于理解Spark的内部工作原理,尤其是数据流管理和效率优化至关重要。
这本书是Spark开发者深入理解系统内核、提升性能调优能力的必备参考,涵盖了从基础概念到高级技术的全面知识,有助于读者在实际工作中更好地利用Spark处理大数据任务。
11.
val totalCores: Int)
在此简单给出内部实现流程的解析,具体步骤如下所示:
1
)
对 应 的 初 始 化 代 码 在 前 面 提 到 的
SparkContext
类 中 的 主 要 流 程 的
createTaskScheduler
方法中, 构建
TaskScheduler
实例( 这 里 具 体 子 类 为
TaskSchedulerImpl
)后,在该实例的初始化时传入同时构建的
SchedulerBackend
实
例(这里具体子类为
LocalBackend
)。
2
)
构建出
TaskScheduler
实例后,会调用实例的
start
方法,在该方法中首先会调用
SchedulerBackend
的
start
方法。
3
)
在
SchedulerBackend
的
start
方法中,会构建出一个
LocalEndpoint
实例,在该实例
中就会实例化出一个
Executor
,
Executor
实例负责具体的任务执行。
4
)
之后就是
TaskScheduler
进行作业调度,调用
SchedulerBackend
的
reviveOffers()
方法,
然后由该方法向
LocalEndpoint
实例发送
ReviveOffers
消息。
5
)
最终在
LocalEndpoint
实例处理
ReviveOffers
消息时,启动
Task
,其他处理类似。
对应
Task
的启动代码如下:
1.
def reviveOffers() {
2.
val offers = Seq(new WorkerOffer(localExecutorId, localExecutorHostname, freeCores))
3.
for (task <- scheduler.resourceOffers(offers).flatten) {
4.
//
在
Executor
中会使用线程池的方式调度任务,而对应的作业调度是通过
5.
//
判断当前可用
Cores
个数是否符合每个任务(
Task
)所需的
Cores
个数。
6.
//
当符合该条件时更新当前可用
Cores
数
freeCores
,然后启动任务(
Task
)
7.
freeCores -= scheduler.CPUS_PER_TASK
8.
executor.launchTask(executorBackend, taskId = task.taskId, attemptNumber =
task.attemptNumber,
9.
task.name, task.serializedTask)
10.
}
11.
}
其中
Task
的调度控制代码参考
TaskSchedulerImpl
的
resourceOfferSingleTaskSet
方法,
其他调度的具体信息可以参考本书的调度章节。
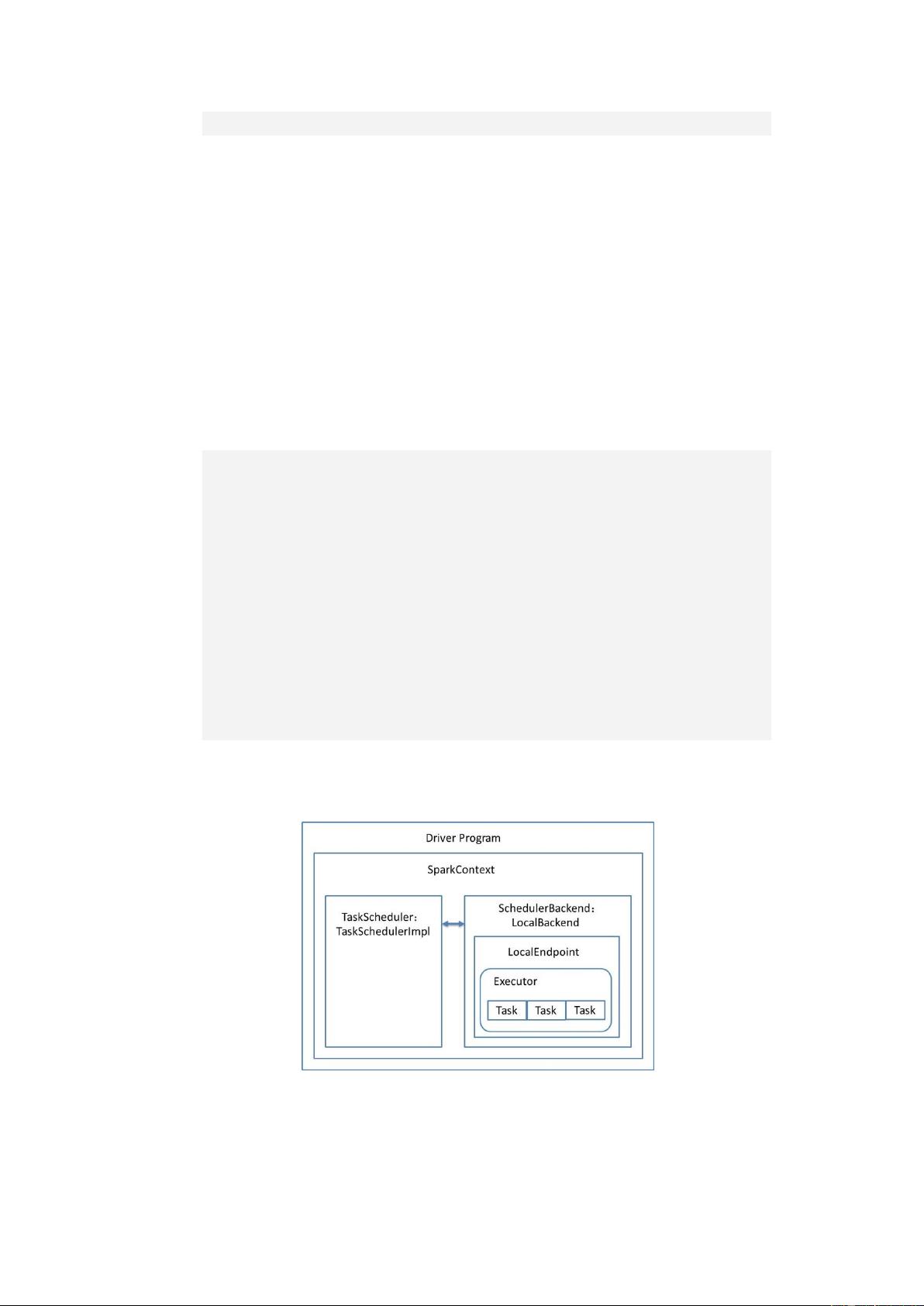
上述三种
local
的部署模式,可以通过图
3-1
来加深理解:
图
3-1
三种
local
的部署模式图
其中,
T
askScheduler
与
SchedulerBackend
的 具体子类的具体子类分为为
T
askSchedulerImpl
与
LocalBackend
,具体的
Task
仍然在
Executor
中执行。


剩余114页未读,继续阅读
494 浏览量
957 浏览量
3475 浏览量
150 浏览量
2025-03-13 上传

harli
- 粉丝: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android平台DoKV:小巧强大Key-Value管理框架介绍
- Java图书管理系统源码与MySQL的无缝结合
- C语言实现JSON与结构体间的互转功能
- 快速标签插件:将构建信息轻松嵌入Java应用
- kimsoft-jscalendar:多语言、兼容主流浏览器的日历控件
- RxJava实现Android多线程下载与断点续传工具
- 直观示例展示JQuery UI插件强大功能
- Visual Studio代码PPA在Ubuntu中的安装指南
- 电子通信毕业设计必备:元器件与芯片资料大全
- LCD1602显示模块编程入门教程
- MySQL5.5安装教程与界面展示软件下载
- React Redux SweetAlert集成指南:增强交互与API简化
- .NET 2.0实现JSON数据生成与解析教程
- 上海交通大学计算机体系结构精品课件
- VC++开发的屏幕键盘工具与源码解析
- Android高效多线程图片下载与缓存解决方案
