集成学习方法详解:从决策树到Ensemble Model
需积分: 9 138 浏览量
更新于2024-07-18
1
收藏 11.4MB PPTX 举报
"集成学习方法汇总讲稿,涵盖了集成学习的基本概念、常用算法以及应用场景,由李逸帆在2018年的认知智能部讲座中分享。内容包括决策树的基础知识,如分类与回归决策树,以及集成学习的三种经典方法:Bagging、Boosting和Stacking,并探讨了它们在降低模型误差和防止过拟合中的作用。"
集成学习是一种通过结合多个基础模型以创建更强大、更稳健的预测系统的机器学习技术。它主要目的是减少模型的偏差(Bias)和方差(Variance),从而提高整体预测性能并降低过拟合的风险。在当前的数据科学竞赛如Kaggle中,集成学习已经成为取得高分的关键策略。
决策树是集成学习中最常用的基础模型之一,分为分类决策树和回归决策树。分类决策树用于处理离散型数据,而回归决策树则适用于连续型数据。决策树的构建基于信息熵、基尼系数等标准,这些度量用于衡量数据的纯度和划分的合理性。
集成学习的经典算法主要包括:
1. Bagging(Bootstrap Aggregating):通过从原始数据集中抽样生成多个子集(带放回抽样),然后训练多个基础决策树模型。这些模型的预测结果通过投票或平均的方式组合,以减少模型的方差。
2. Boosting:以迭代方式训练模型,每次迭代中根据前一轮预测错误的情况调整样本权重,使得后续模型更加关注之前模型犯错的样本。常见的Boosting算法包括AdaBoost和Gradient Boosting,后者的性能通常优于Bagging,但更容易过拟合。
3. Stacking(Meta-Learning):先训练多个基学习器,然后使用它们的预测结果作为新的特征输入,再训练一个元模型(Meta-Classifier)。这种方法能够利用不同模型之间的互补性,进一步提高预测性能。
4. Blending:与Stacking类似,但它使用单独的验证集(Holdout Set)来获取基学习器的预测结果,而不是通过交叉验证(K-Fold CV)生成特征,这可以减少训练集之间的相关性。
集成学习的优势在于,通过组合多个模型的预测,可以捕获数据的不同方面,增加模型的泛化能力。同时,它允许使用各种类型的基模型,如决策树、线性模型、神经网络等,提供了极大的灵活性。然而,需要注意的是,集成学习可能会增加计算复杂度,且如果基模型过于相似,可能无法显著提升整体性能。因此,在实践中,选择合适的基模型和集成策略,以及优化模型参数,对于构建有效的集成学习系统至关重要。
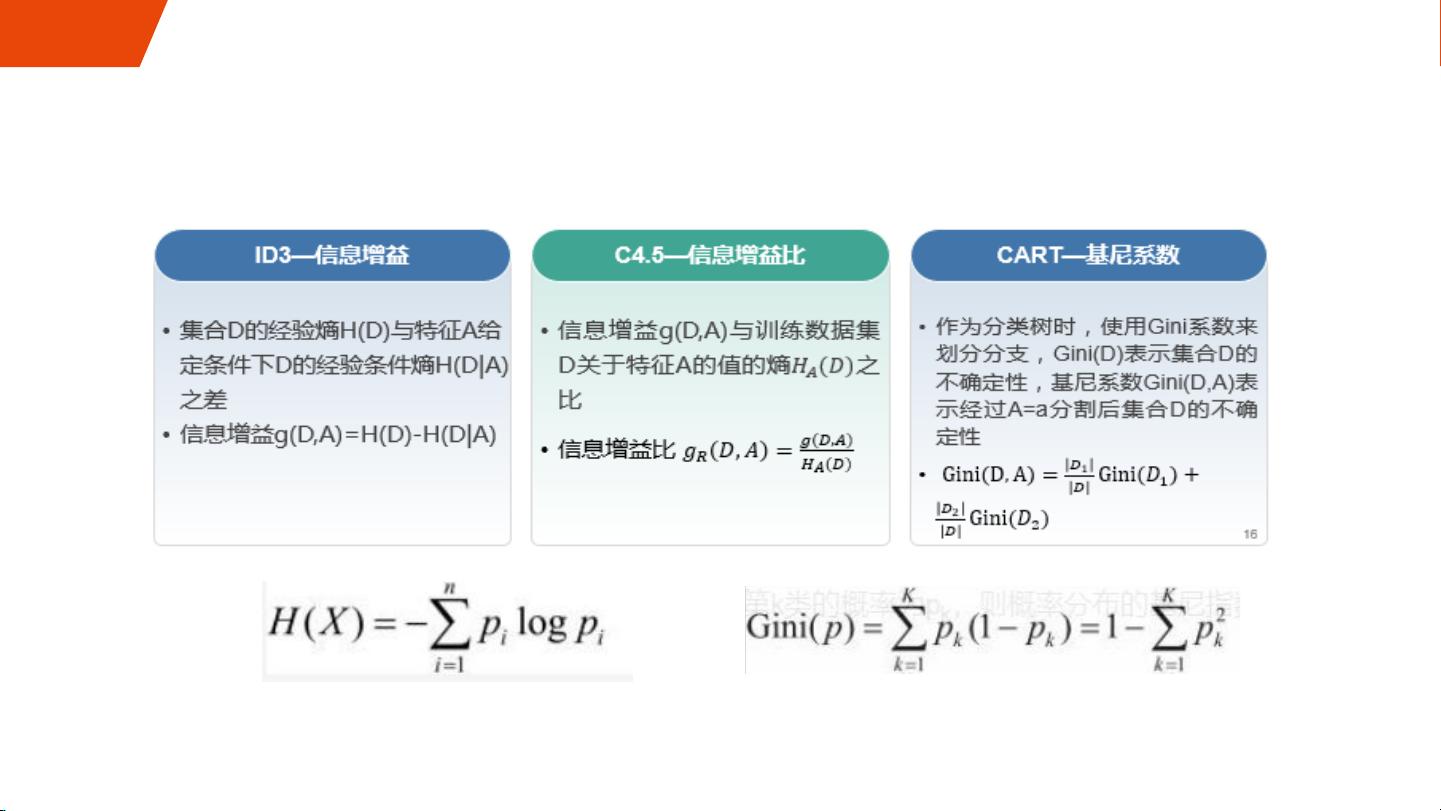
基本树形算法
常见分类决策树算法
信息熵
基尼系数

剩余25页未读,继续阅读
336 浏览量
2021-10-11 上传
148 浏览量
208 浏览量
144 浏览量
2010-03-29 上传
214 浏览量
2021-03-15 上传

Matrix-yang
- 粉丝: 157
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
