"深度学习基础:神经网络、网络操作与计算、超参数、激活函数详解"
需积分: 0 194 浏览量
更新于2024-01-17
收藏 15.33MB PDF 举报
本文主要是介绍了深度学习基础的内容。文章首先介绍了神经网络的组成和常见的模型结构,包括基本概念和神经网络的常用模型结构。然后介绍了如何选择深度学习开发平台以及为什么使用深层表示和深层神经网络难以训练的原因。接着介绍了网络操作与计算,包括前向传播与反向传播的过程,并且给出了计算神经网络输出、计算卷积神经网络输出值和计算Pooling层输出值的方法。然后介绍了超参数的概念,以及如何寻找超参数的最优值和超参数搜索的一般过程。最后介绍了激活函数的作用和常见的激活函数及其导数计算的方法,以及激活函数的性质。
在深度学习基础部分,文章主要介绍了神经网络的基本概念和常用模型结构。神经网络是由一些神经元相互连接而成的网络,每个神经元对应一个输入和多个输出。常见的神经网络模型包括前馈神经网络、卷积神经网络、循环神经网络等。这些模型通过不同的结构和参数来实现不同的学习任务。
在选择深度学习开发平台部分,文章介绍了如何选择合适的深度学习开发平台,包括考虑因素如功能、性能、易用性和社区支持等。根据自己的需求和实际情况选择一个适合自己的平台。
在深层表示和深层神经网络难以训练的部分,文章解释了为什么要使用深层表示和深层神经网络以及深层神经网络难以训练的原因。深层表示可以帮助提取更丰富的特征信息,但深层神经网络训练困难是因为梯度消失和梯度爆炸等问题。
在网络操作与计算部分,文章介绍了前向传播和反向传播的过程,以及如何计算神经网络的输出值、卷积神经网络的输出值和Pooling层的输出值。前向传播是将输入通过神经网络进行推理得到输出的过程,而反向传播则是通过计算损失函数的导数来更新网络参数。
在超参数部分,文章介绍了什么是超参数,以及如何寻找超参数的最优值和超参数搜索的一般过程。超参数是指在训练神经网络中设置的除了网络参数外的其他参数,如学习率、批量大小、正则化参数等。寻找超参数的最优值可以通过网格搜索、随机搜索等方法来实现。
最后,在激活函数部分,文章介绍了为什么需要非线性激活函数以及常见的激活函数及其导数计算的方法。激活函数可以引入非线性变换,帮助神经网络学习更复杂的函数关系。常见的激活函数包括Sigmoid函数、ReLU函数、Leaky ReLU函数等。激活函数的导数计算主要用于反向传播过程中的参数更新。
总之,本文全面介绍了深度学习基础的内容,包括神经网络的组成和常见模型结构、选择深度学习开发平台的方法、深层表示和深层神经网络难以训练的原因、网络操作与计算的过程、超参数的概念和寻找最优值的方法,以及激活函数的作用和常见的激活函数及其导数计算的方法。这些基础知识对于理解和应用深度学习具有重要的意义。

深度学习在不同应⽤场景的数据量是不⼀样的,这也就导致我们可能需要考虑分布式计算、多GPU计算的问题。例如,对计
算机图像处理研究的⼈员往往需要将图像⽂件和计算任务分部到多台计算机节点上进⾏执⾏。当下每个深度学习平台都在快
速发展,每个平台对分布式计算等场景的⽀持也在不断演进。
参考参考4 :深度学习平台的成熟程度:深度学习平台的成熟程度
成熟程度的考量是⼀个⽐较主观的考量因素,这些因素可包括:社区的活跃程度;是否容易和开发⼈员进⾏交流;当前应⽤
的势头。
参考参考5:平台利⽤是否多样性?:平台利⽤是否多样性?
有些平台是专门为深度学习研究和应⽤进⾏开发的,有些平台对分布式计算、GPU 等构架都有强⼤的优化,能否⽤这些平
台/软件做其他事情?⽐如有些深度学习软件是可以⽤来求解⼆次型优化;有些深度学习平台很容易被扩展,被运⽤在强化学
习的应⽤中。
3.1.4 为什么使⽤深层表⽰?
1. 深度神经⽹络是⼀种特征递进式的学习算法,浅层的神经元直接从输⼊数据中学习⼀些低层次的简单特征,例如边缘、
纹理等。⽽深层的特征则基于已学习到的浅层特征继续学习更⾼级的特征,从计算机的⾓度学习深层的语义信息。
2. 深层的⽹络隐藏单元数量相对较少,隐藏层数⽬较多,如果浅层的⽹络想要达到同样的计算结果则需要指数级增长的单
元数量才能达到。
3.1.5 为什么深层神经⽹络难以训练?
1. 梯度消失
梯度消失是指通过隐藏层从后向前看,梯度会变的越来越⼩,说明前⾯层的学习会显著慢于后⾯层的学习,所以学习会
卡住,除⾮梯度变⼤。
梯度消失的原因受到多种因素影响,例如学习率的⼤⼩,⽹络参数的初始化,激活函数的边缘效应等。在深层神经⽹络
中,每⼀个神经元计算得到的梯度都会传递给前⼀层,较浅层的神经元接收到的梯度受到之前所有层梯度的影响。如果
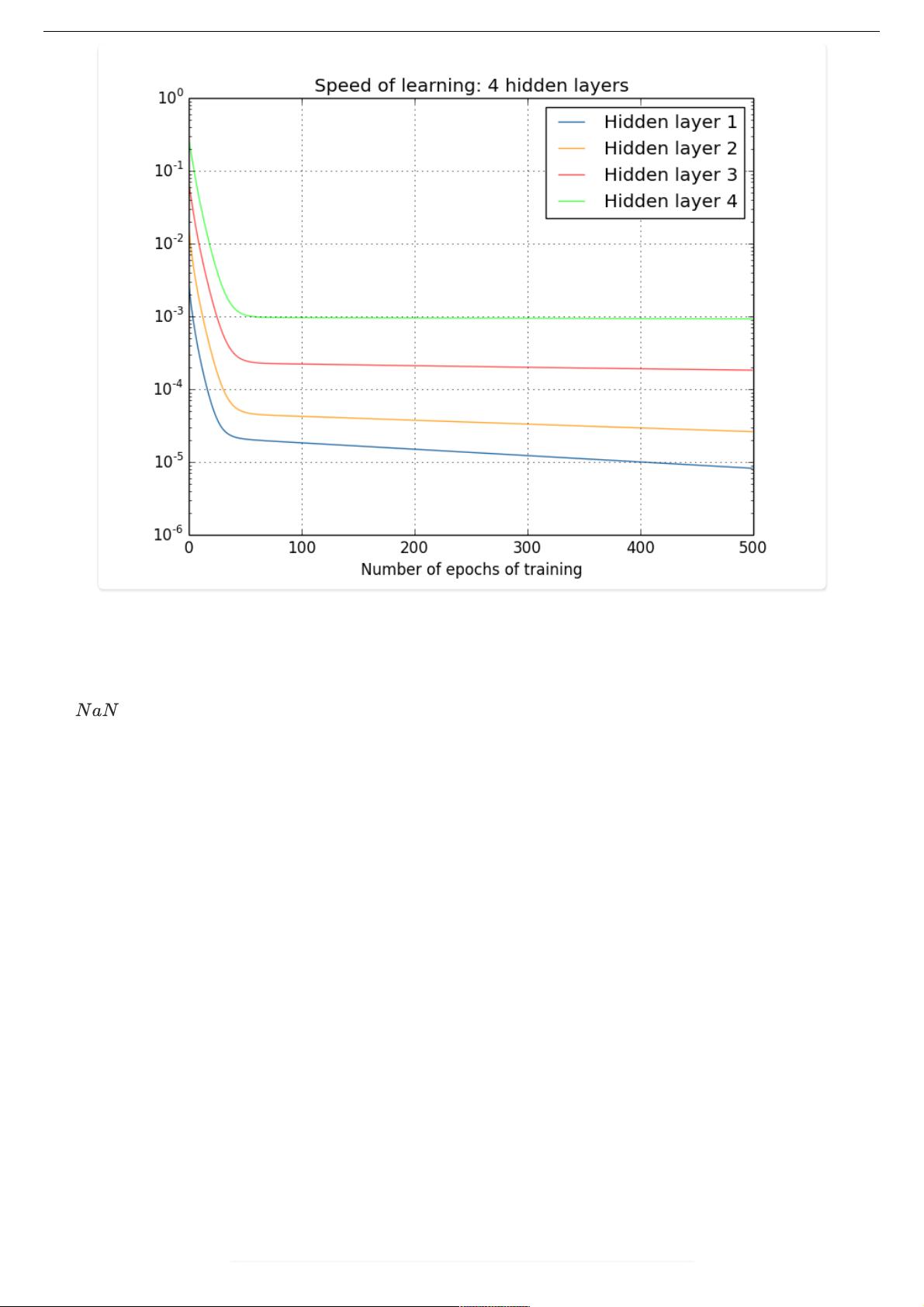
计算得到的梯度值⾮常⼩,随着层数增多,求出的梯度更新信息将会以指数形式衰减,就会发⽣梯度消失。下图是不同
隐含层的学习速率:
第三章 深度学习基础
7/52
剩余54页未读,继续阅读
2022-08-03 上传
143 浏览量
168 浏览量
184 浏览量
2021-10-04 上传
2023-08-23 上传
115 浏览量
106 浏览量

两斤香菜
- 粉丝: 22
- 资源: 297
 我的内容管理
展开
我的内容管理
展开







最新资源
- formidable.css:一个CSS库,具有漂亮,可访问和可自定义的形式
- TobiasHall:我的个人资料库
- RTN(Visio图标)
- FRC2012Drive-roboRIO:Turtle Bot 的代码,2012 年与 roboRIO 相连的动力传动系统
- python爬虫demo
- Apple USB Ethernet Adapter(苹果USB网卡驱动.zip
- IPGeoLocation:检索IP地理位置信息
- PlayerBlockTracker:跟踪播放器放置的块
- 易语言-使用窗口_模糊遍历窗口() 取出本地已登录QQ帐号
- node-ble:用纯Node.js编写的蓝牙低功耗(BLE)库(无绑定)-Bluez通过DBus烘焙
- 延迟平衡器:用于平衡器Web ui的Nginx
- Fairy Tail HD Wallpapers Anime New Tab Theme-crx插件
- fortran个人上手练习项目
- 模块生成器
- here-vector-tile-examples:带有各种第三方网络地图渲染器的HERE Vector Tile API的示例
- 易语言-易语言编写一个音速启动
