




OPPO的LLM与RAG技术探索:从缺陷到codeLLM创新
需积分: 5 4 浏览量
更新于2024-06-14
收藏 2.71MB PDF 举报
"OPPO的AI中心大模型算法部首席算法架构师郑志彤在DataFunCon2024上分享了codeLLM和RAG技术在OPPO的探索,探讨了LLM(大型语言模型)的缺陷、领域知识的重要性以及codeLLM和dataLLM的技术创新,并展望了LLM与符号化推理的结合可能性。"
本文首先介绍了LLM(Large Language Models)存在的主要问题。LLM的幻觉是由于训练数据的共现偏置、精调过程中的上下文限制以及不适当的prompt导致的推理错误。由于LLM是基于上下文的token概率进行预测,即使训练数据无偏,也无法捕捉到罕见但重要的事件。为了缓解这一问题,RAG(Reinforcement Learning from Generated Examples)技术被提出,作为一种关键的解决方案。
接着,文章讨论了LLM的推理鲁棒性。Transformer模型的内在注意力机制(Intra-Clause Logic, ICL)能力和推理的顺序性是其基础,但仍然需要通过数据增强和优化的ICL网络架构来提升推理的鲁棒性。
领域知识在LLM的应用中起着至关重要的作用,分为非结构化和结构化两种类型。非结构化知识如实时信息文本和操作规范,而结构化知识包括数据库、知识图谱和QA对等。专家系统则是一种具有完整正确推理能力的知识库,对于增强LLM的性能非常有价值。
在codeLLM和dataLLM的技术创新部分,郑志彤强调了基模型选择的需求,即选择在代码生成、补全、注释、单元测试和bug检测等方面表现优秀的模型。选取的标准是模型应同时具备强大的code/data处理能力和NLP能力,且有较大的对齐提升潜力。他列举了一些基准模型,如starcoderBase、codeLLAMA和deepSeekCoder,这些模型拥有不同规模的参数量,以适应不同复杂度的任务需求。
此外,他还提到了针对非结构化和结构化领域知识的调优策略,这可能涉及到将这些知识有效地融入到LLM中,以提升模型在特定领域的表现。通过这样的优化,LLM可以更好地理解和处理与特定业务场景相关的任务。
最后,演讲者展望了未来LLM与符号化推理的结合,暗示了将LLM的自然语言处理能力与传统推理系统的精确性相结合的可能性,这可能会进一步推动AI在软件开发和数据分析等领域的应用。通过这种方式,LLM可以不仅限于文本理解,还能实现更复杂的逻辑推理,从而提高工作效率和准确性。
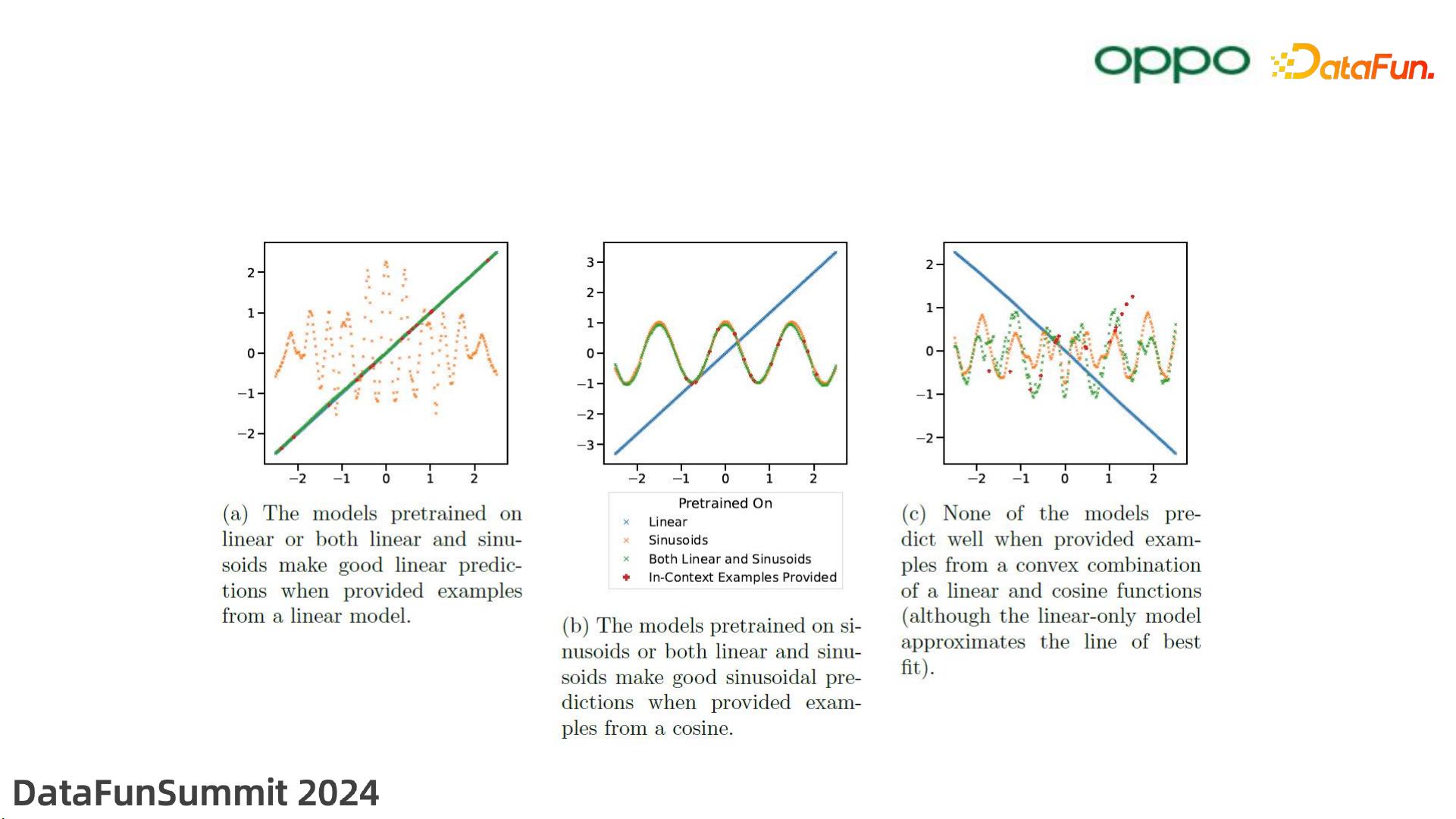
1.2 LLM的推理鲁棒性
• Transformer的ICL能力。

剩余43页未读,继续阅读
307 浏览量
102 浏览量
132 浏览量
2023-04-22 上传

FrontScience
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- USB转串口驱动下载:简化连接操作
- Eglot-grammarly:Emacs中的Grammarly语法检查集成
- Element-UI官方组件库文档深度解析
- Goridge: 高性能PHP与Golang间RPC编码解码库
- Instagram标签数据分析:从抓取到生成Word2Vec和TF-IDF模型
- 掌握JavaScript:制作交互式简历的学习之旅
- Creo 3.0中文版工程图创建与编辑视频教程
- 掌握OpenCV+Python,第三版案例研究
- 优化后的Unity电子书插件支持快速异步加载图片
- JavaScript项目实践:js-temp-project探索
- timesince.js:让时间显示更友好,生成易读的时间描述
- Word2vec管道:自然语言处理的全栈实施指南
- PPT文字倒影特效模板下载
- Creo参数化齿轮设计视频教程下载
- 邮件服务器存档配置指南与mailserver-config
- monkeylearn包使用教程:R语言中的文本分析工具





















