
一步一步打造一步一步打造MySQL高可用平台高可用平台
一 、引子
笔者刚开始进入公司的时候,主要是忙于分布式MySQL系统----MyShard的构建,公司使用了大量的IDC机房,基于这种网络
特点,MyShard设计当初完全是为了是一套支持Multi-Master操作的高可用性的分布式数据库,可以在多个机房中部署的业务
上提供快速的写操作,实现了分布式高可用存储能力。
在业务增长期,MyShard解决了公司的很多大型的数据库存储业务,随着公司业务逐渐稳定下来,分布式存储需求越来越少。
而公司却有大量的小业务以及不断尝试的各种新业务,需要越来越多的小数据量的数据库存储。
所以这时候发现,之前的工作方向一直集中在公司的10%不到的业务上,而公司的90%以上的存储需求是MySQL的需求,目
前有好上千套的MySQL在给不同的业务提供服务。而在当时,不管是MySQL的交付还是管理都比较原始,极端情况下,我们
需要业务申请方自己提供服务器来部署MySQL,所以交付的周期也很长。而在高可用方面,都是需要业务方自己去处理主从
切换等等问题,出现主数据库故障的时候,往往需要业务方自己去修改配置文件,重启进程,增加了服务的中断时间。
二、为什么没有采用开源的高可用方案
业界比较流行的MySQL的高可用方案主要有:MMM和MHA两种,对这个方案的分析网上有很多,MHA是优先选取的方案。
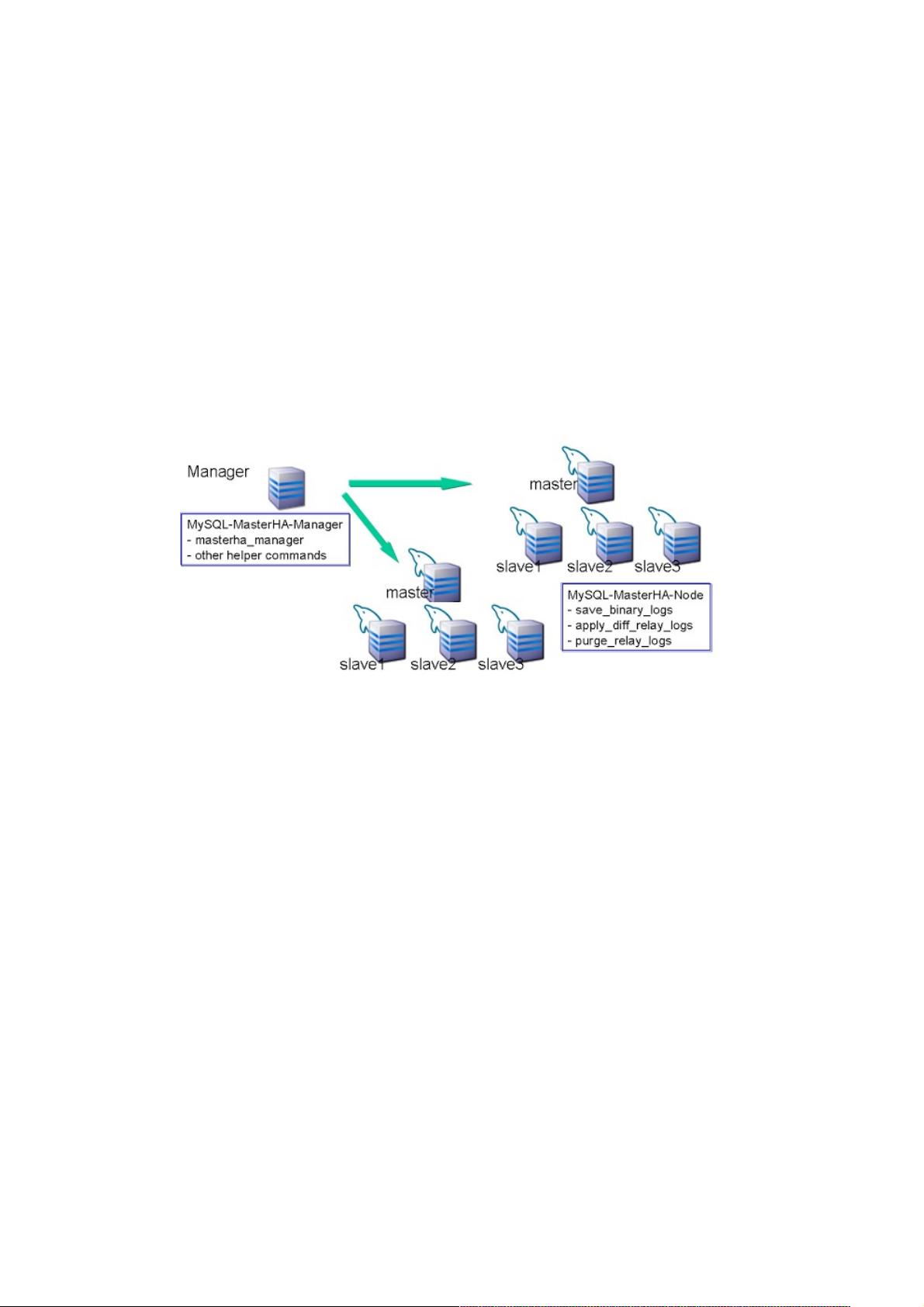
MHA的工作原理:
clipboard.png
当master出现故障时,通过对比slave之间I/O线程读取master binlog的位置,选取最接近的slave做为latestslave。其它slave
通过与latest slave对比生成差异中继日志。在latest slave上应用从master保存的binlog,同时将latest slave提升为master。最
后在其它slave上应用相应的差异中继日志并开始从新的master开始复制。
在MHA实现Master故障切换过程中,MHA Node会试图访问故障的master(通过SSH),如果可以访问(不是硬件故障,比
如InnoDB数据文件损坏等),会保存二进制文件,以最大程度保证数据不丢失。MHA和半同步复制一起使用会大大降低数据
丢失的危险。
MHA的优点
MHA提供了一个通用的框架,我们可以自定义判断和切换操作的步骤;而且,MHA的代码开源,我们甚至可以进行二次开
发,这都为高可用系统提供了很好的扩展 能力。
MHA的缺点
需要在各个节点间打通ssh信任,这对某些公司安全制度来说是个挑战,因为如果某个节点被黑客攻破的话,其他节点也会跟
着遭殃;
自带提供的脚本还需要进一步补充完善,当然了,一般的使用还是够用的。
虽然一个MHA Manger可以管理多个集群,但是没有大规模集群的经验。
高可用依赖于vip的方案,譬如采用keepalive来达到vip的切换,但是keepalive会限制切换的主机必须在一个网段,对于跨机房
不在一个网段的服务器来说,就无法支持了。在大规模为每个MySQL集群安排一个vip也是难以实现的。keepalive在一个网段
内,部署多套也会互相影响。
为什么不采用
我们公司的数据库的特点:
数据库多机房部署
下载后可阅读完整内容,剩余3页未读,立即下载

weixin_38666697
- 粉丝: 4
- 资源: 895
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入理解23种设计模式
- 制作与调试:声控开关电路详解
- 腾讯2008年软件开发笔试题解析
- WebService开发指南:从入门到精通
- 栈数据结构实现的密码设置算法
- 提升逻辑与英语能力:揭秘IBM笔试核心词汇及题型
- SOPC技术探索:理论与实践
- 计算图中节点介数中心性的函数
- 电子元器件详解:电阻、电容、电感与传感器
- MIT经典:统计自然语言处理基础
- CMD命令大全详解与实用指南
- 数据结构复习重点:逻辑结构与存储结构
- ACM算法必读书籍推荐:权威指南与实战解析
- Ubuntu命令行与终端:从Shell到rxvt-unicode
- 深入理解VC_MFC编程:窗口、类、消息处理与绘图
- AT89S52单片机实现的温湿度智能检测与控制系统
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


