Heritrix网络爬虫详解与配置指南
"Heritrix是一个基于Java的开源网络爬虫,主要特点是高度可扩展,允许开发者自定义抓取逻辑。这款工具源自www.archive.org,主要用于从互联网上抓取数据。本文档将深入探讨Heritrix的使用和高级开发应用。
10.1 Heritrix的使用入门
启动Heritrix涉及多个步骤,包括下载、配置和运行。Heritrix的最新版本为1.10,可以从其官方网站或SourceForge下载。下载后,解压缩到本地目录,并注意其目录结构,特别是包含工具库的`lib`目录和包含配置文件的`conf`目录。
10.1.1 下载和运行
Heritrix的核心文件是`heritrix-1.10.1.jar`,而`conf/heritrix.properties`文件至关重要,因为它包含了Heritrix运行时的关键参数。初次运行时,需要在该文件中设置WebUI的登录凭据,这是通过在文件中添加用户名和密码(用冒号分隔)来完成的。
10.1.2 配置和启动
配置完成后,可以选择不同的启动方式。一种常见的方式是通过WebUI启动,这需要确保已设置了WebUI的登录信息。Heritrix还可以通过CrawlController以编程方式后台启动一个抓取任务。
10.1.3 WebUI启动
WebUI提供了图形化的界面,便于监控和控制爬虫的运行状态。启动WebUI后,用户可以登录,然后创建和管理爬取作业,定制抓取策略,设置种子URL,以及配置其他高级特性,如robots.txt遵守规则、爬取深度限制、下载速率限制等。
10.2 高级开发应用
Heritrix的可扩展性体现在其模块化设计上,开发者可以通过扩展各个组件,如爬取策略、链接过滤器、内容处理器等,实现定制化的网络抓取功能。例如,可以编写自定义的Bean来处理特定类型的网页内容,或者实现特定的链接发现算法。
10.2.1 扩展组件
Heritrix支持通过JavaBeans来扩展其功能。开发者可以创建新的Bean,实现特定接口,然后在配置文件中注册这些Bean,使其在爬取过程中被调用。这样,Heritrix就能按照开发者的需求处理网页,提取或存储所需信息。
10.2.2 自定义策略
Heritrix的策略组件允许开发者定义如何选择要抓取的URL,何时以及如何处理内容,以及如何保存抓取的数据。通过自定义这些策略,可以构建出针对特定网站或数据类型的高度定制化爬虫。
10.2.3 日志和调试
Heritrix提供了丰富的日志功能,可以帮助开发者跟踪爬虫的运行情况,定位和解决问题。通过调整日志配置,可以在不同级别收集信息,从基本的运行状况到详细的调试信息。
总结:
Heritrix是一个强大且灵活的网络爬虫工具,通过深入理解其配置和组件机制,开发者可以构建出满足各种需求的爬取解决方案。无论你是要抓取特定类型的网页数据,还是想要研究大规模的网页结构,Heritrix都能提供必要的工具和支持。通过不断学习和实践,你将能够充分利用Heritrix的高级功能,实现高效的网络数据采集。"

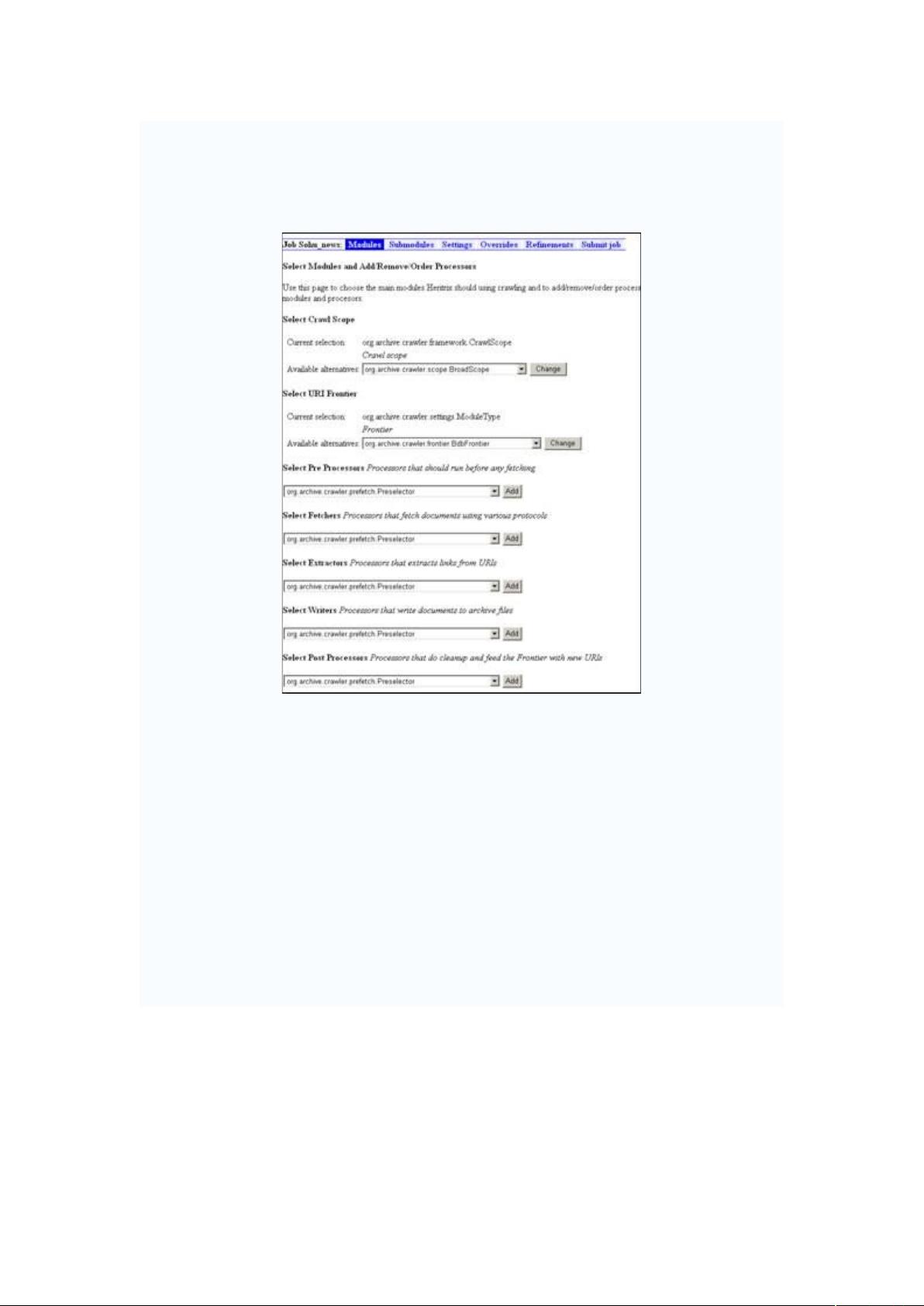
在 中,一个任务对应一个描述文件。这个描述文件的默认的名称为
。每次创建一个新任务时,都相当于生成了一个 的文件。
文件中详细记录了 在运行时需要的所有信息。例如,它包括该用户所
选择的 3 类、 类、 类、抓取时线程的最大数量、连
接超时的最大等待时间等信息。上面所说的 ) 种创建抓取任务的方式,其实都
是在生成一个 文件。其中,第 ) 种 !#,则是直接拷贝
默认的 文件。在所创建的 * 工程或是命令行启动的
下载包中,该默认的 文件均是放于 G+# 目录下的。
关于 的细节,在此还不必深究。因为它里面所有的内容,都会在
%& 上看到。
(')单击 !# 链接,创建一个新的抓取任务,如图 $ 所示。
图 $ !新的抓取任务
())在新建任务的名称上,填入“I>,表示该抓取任务将抓取搜狐
的新闻信息。在 ? 中随意填入字符,然后再在 框中,填入搜
狐新闻的网址。
这里需要解释一下 的含义。所谓 ,其实指的是抓取任务的起始点。
每次的抓取,总是需要从一个起始点开始,在得到这个起始点网页上的信息后,
分析出新的地址加入抓取队列中,然后循环抓取,重复这样的过程,直到所有
链接都分析完毕。
(8)在图 $ 中,设置了搜狐新闻的首页为种子页面,以此做为起始点。
用户在使用时,也可以同时输入多个种子,每个 %/; 地址单独写在一行上,如
图 $ 所示。
图 $ !多个种子的情况
当然,凭着目前的设置,还没法开始抓取网页,还需要对这个任务进行详细的
设置。
剩余54页未读,继续阅读
2016-05-17 上传
2009-10-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-10-22 上传
2024-10-22 上传
2024-10-22 上传

pengdingstudy
- 粉丝: 1
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
