音频编码详解:感知编码器原理与主流技术解析
需积分: 9 148 浏览量
更新于2024-07-18
收藏 5.52MB PDF 举报
音频编码,由高泽华于2007年12月18日探讨,是将音频信号转换成数字信号以便于存储、传输和处理的技术。本文主要分为三个部分:基本原理、主流标准和技术分析。
第一部分:基本原理
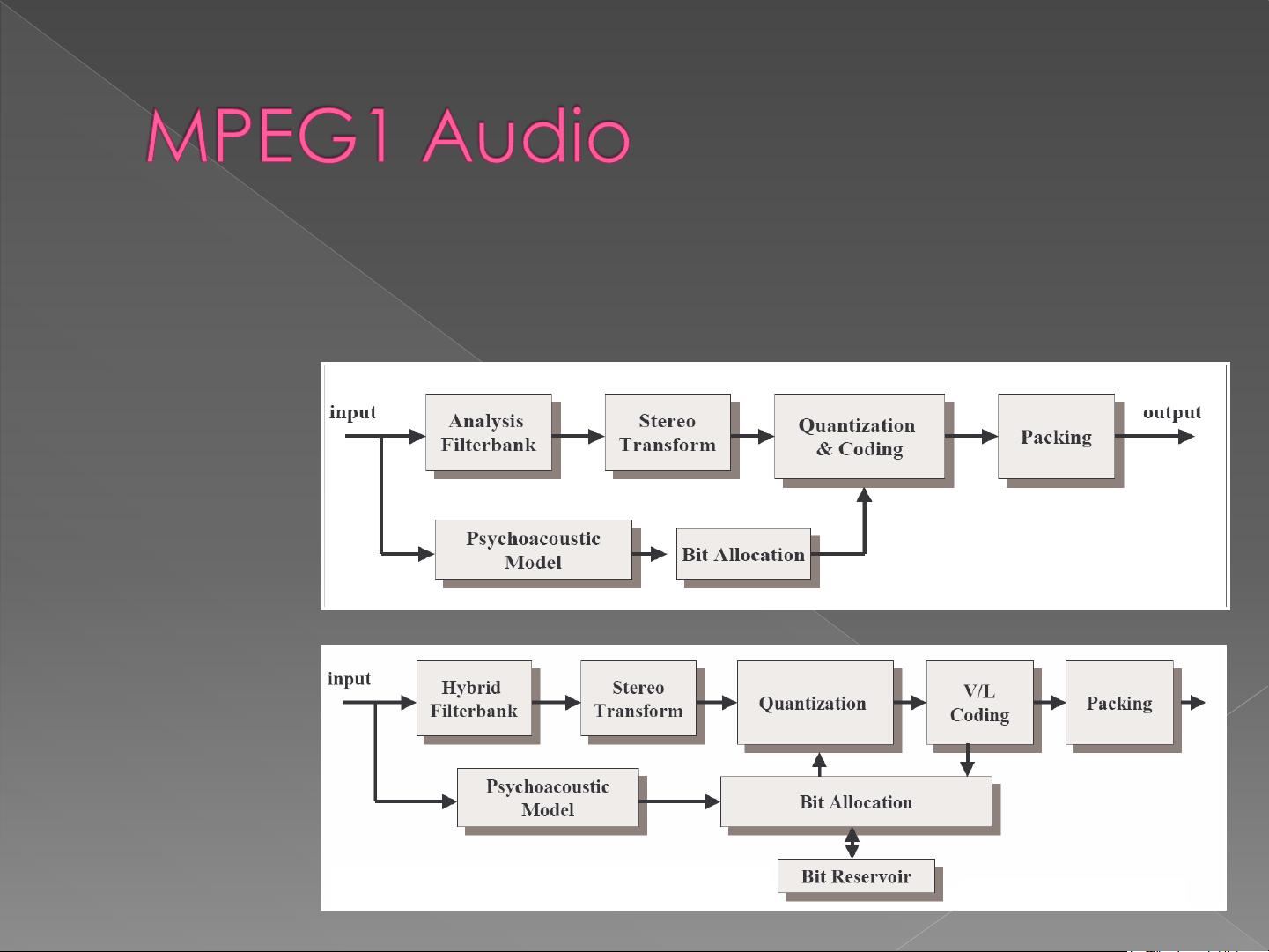
音频编码根据采样率和编码方法进行分类。其中,语音编码通常低于8kHz,如ADPCM(Adaptive Differential Pulse Code Modulation)系列,如G.721、G.722和G.726,它们基于简单的预测编码,利用人耳对声音变化的敏感度进行压缩。而音频编码则针对高于8kHz的声音,如MP2、AAC(Advanced Audio Coding)、WMA(Windows Media Audio)等,这些采用感知编码器,基于人耳的生理特性,如频率响应、掩蔽效应等进行编码,核心内核包括T+SQ变换。
感知编码器的特点是模拟人耳的感知能力,通过对音频信号的频率和时间特性进行分析,优化数据表示,以达到更高的压缩效率。例如,AAC和AC3就是这类编码的代表,它们在高保真音频编码中广泛应用。
第二部分:主流标准
参数编码器主要用于语音编码,如G.723.1、G.729、G.728、CELP(Coded Excited Linear Prediction)、AMR(Adaptive Multi-Rate)和EVRC(Enhanced Variable Rate Coding),这些编码器基于人类语言和声音特征的统计模型,采用预测编码策略,如P+VQ(Predictive plus Vector Quantization)。
第三部分:技术分析
文章深入剖析了人耳模型,包括声压级(SPL)、绝对听阈(Absolute Threshold of Hearing)、听觉带宽(Critical Bands)、同步和非同步掩蔽效应,以及巴克谱( Bark scale),这是一种心理声学模型,通过模拟人耳的频率响应来计算编码的精确度。在编码过程中,先进行快速傅立叶变换(FFT Analysis),然后确定声压水平,考虑静默背景下的阈值,分离和量化声调和非声调成分,最后进行细化处理,以最小化信息损失。
音频编码涉及复杂的信号处理技术,旨在通过模拟人耳的感知特性来实现高效的数据压缩,同时保持音频质量。不同类型的编码器针对不同的应用场景,如语音通信和高质量音乐播放,各有其独特的优势和适用范围。理解这些编码原理对于音频处理和相关领域的专业人士至关重要。




183 浏览量
111 浏览量
2014-03-06 上传
266 浏览量









