需求分析与概念模型在IT数据管理中的应用
需积分: 10 151 浏览量
更新于2024-07-09
收藏 749KB PDF 举报
"需求分析与概念模型 - IT及Data.pdf"
在进行需求分析和概念模型设计时,首要步骤是深入理解企业的需求和环境。这包括多个关键任务,旨在确保数据库设计的有效性和适应性。
1. 了解企业商业模式:这是理解企业运作方式的基础,包括其收入来源、市场定位和竞争优势,这些都会直接影响到数据处理和存储的需求。
2. 了解企业的IT战略与数据战略期待:IT战略关乎技术选择、平台整合和未来规划,而数据战略则涉及如何利用数据作为核心资产,为企业决策提供支持。
3. 评估可重用信息资产:识别和评估现有的数据资源,如数据库、报告和元数据,以便在新设计中重复利用,减少开发成本并提高效率。
4. 了解组织架构:明确各部门的角色和职责,有助于确定数据流和权限控制的设计。
5. 了解IT/Data人员结构:了解团队的技术能力、技能分布和工作流程,以优化系统的用户友好性和可维护性。
6. 了解IT合规:确保数据库设计符合法规要求,避免法律风险。
7. 了解KPI信息:通过关键绩效指标了解业务表现,以确保数据库能准确反映和支撑这些指标的计算。
8. 沟通计划:设定清晰的沟通路径和材料,确保所有相关人员对项目的进展有共同的理解。
9. 收集业务流程图和报表:这些文档提供业务操作的详细视图,帮助设计师理解数据的生成和使用过程。
10. 组织面谈会:通过面对面交流,收集关键利益相关者的期望和需求。
11. 确立主题域:识别业务的关键领域,为后续的概念模型划分基础。
12. 通用功能调研:研究跨部门或跨系统的共性需求,为通用模块设计提供依据。
13. 源系统分析:评估现有系统的数据质量和结构,为数据迁移或整合做准备。
14. 基础架构确立:确定硬件、软件和网络等基础设施需求。
15. 绘制系统蓝图:概览整个系统的结构和交互,包括系统上下文图和数据流图。
16. 功能性需求确定:明确系统必须实现的功能,如查询、报表生成、数据导入导出等。
17. 非功能性需求确定:包括性能、安全、可用性等非业务特性,对系统整体质量有重要影响。
18. 概念模型蓝图:创建ER图或类图,表示实体、关系和属性,是数据库设计的初步模型。
IT策略方面,选择合适的软件包、系统集成商和服务合同都至关重要:
- 深度合作、人员配置和标准化确保了IT服务的稳定性和一致性。
- 方法论、配合工具和专业水平是评估系统集成商的关键因素。
- 产品支持、升级和许可证管理是供应商评估的重点。
- 明确项目范围、人员配备、交付物、周期和服务价格有助于避免后期纠纷。
数据策略涵盖数据的全生命周期管理:
- 数据定义与描述确保数据的清晰性和一致性。
- 数据供给与分享涉及数据的获取和共享机制。
- 存储策略关乎数据的安全性和访问速度。
- 集成和转移处理数据在不同系统间的流动。
- 管理策略包括数据质量控制和更新规则。
- 数据安全是防止数据泄露和保护隐私的重要措施。
在需求分析阶段,以上任务的优先级不同,但都是确保成功构建概念模型的关键组成部分。通过这些步骤,可以构建出符合业务需求、技术可行且合规的数据模型,为后续的数据库设计和实施奠定坚实基础。
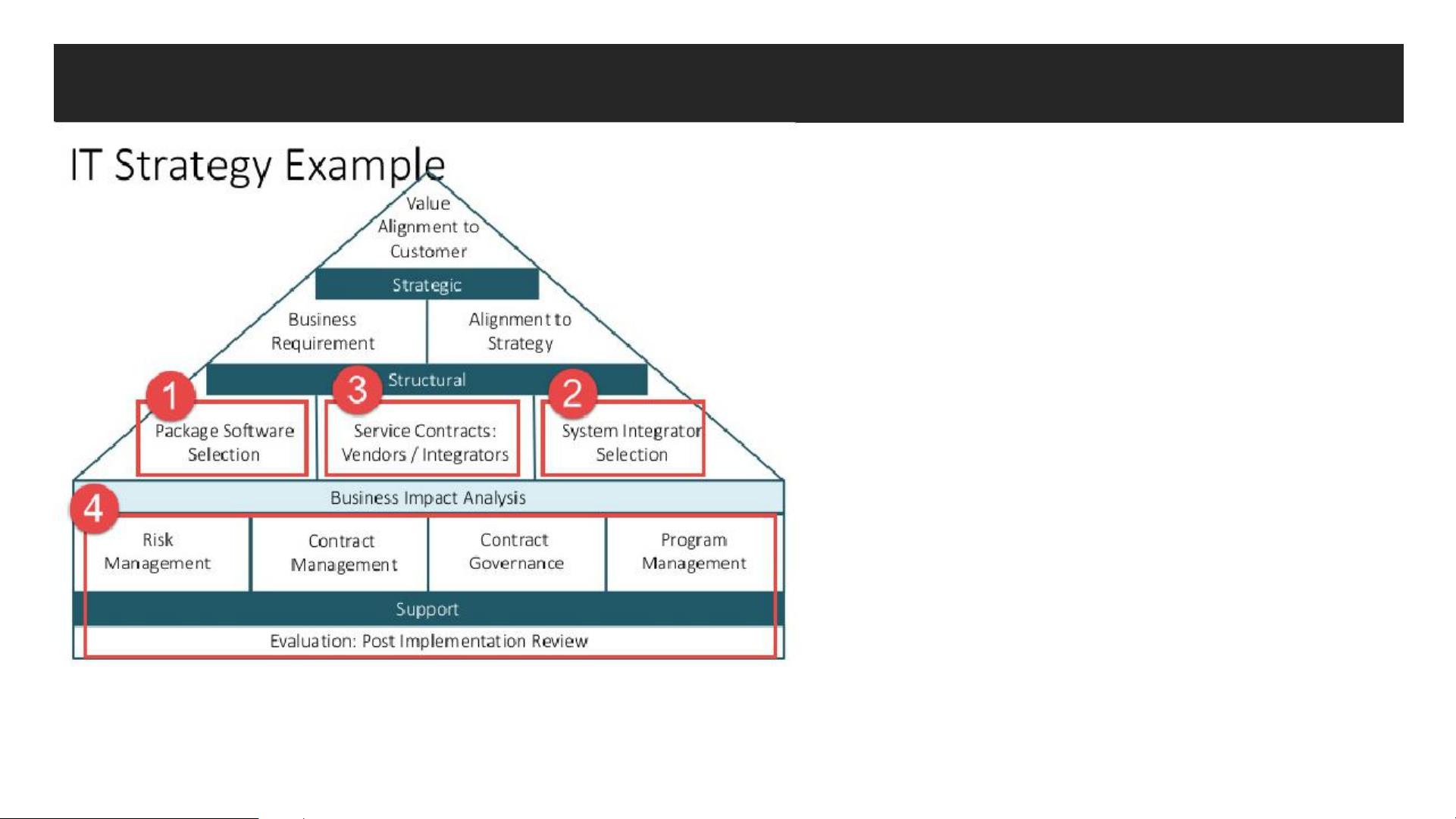
IT 策略 – Package Software Selection
1. 深度合作
2. 人员配置
3. 标准化
4. 知识管理
剩余16页未读,继续阅读
178 浏览量
134 浏览量
288 浏览量
2013-02-28 上传
167 浏览量
122 浏览量
132 浏览量
319 浏览量
207 浏览量

小松
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 安卓动画库Persei:Yalantis开源动画的Java实现
- 掌握整流电路原理及应用的免费学习教程
- 意法半导体STM32F2xx固件库使用详解
- IC卡数据读写工具 - M1卡扇区信息获取
- Luban压缩算法:图片优化的未来之星
- Maya动画练习:16个动物角色模型绑定指南
- C#代码挑战解决方案集锦
- Python工厂操作系统开发教程
- SSMA环境搭建指南:从安装到使用
- 蓝宙双电机编码器检测程序功能详解
- Opencart VQMOD扩展实现多文件上传功能
- 新Twitter界面的极简主义主题设计
- 掌握C语言实现经典密码算法教程
- Angular开发环境搭建与代码脚手架使用指南
- 如何将Excel文件转换为TXT格式
- 使用JavaScript实现coinflip翻硬币效果
