华为云学院MapReduce服务详解
需积分: 9 171 浏览量
更新于2024-07-18
收藏 1.36MB PDF 举报
“1.1 MapReduce服务课程资料涵盖了华为云学院关于MapReduce的详细学习内容,包括大数据背景、Hadoop生态系统、HDFS和MapReduce的原理及特点。”
MapReduce是大数据处理领域的一个重要概念,主要服务于大规模数据集的并行运算。在1.1 MapReduce服务课程中,重点介绍了MapReduce在华为云学院的学习资源,提供了详细的视频讲解链接,旨在帮助学员深入理解这一技术。
首先,课程提到了大数据所带来的挑战,包括数据量的急剧增长、数据类型的多样化以及数据生成速度的加快。为应对这些挑战,Hadoop作为一个开源解决方案应运而生。Hadoop源于2005年的Apache开源项目,它提供了一个强大且不断发展的生态系统,包括YARN(资源管理系统)、内存计算框架如Spark、SQL支持、Hive用于数据分析、NoSQL数据库如HBase,以及批处理工具MapReduce和HDFS文件系统,还有流处理技术如Kafka、Storm和Flume。
Hadoop分布式文件系统(HDFS)是Hadoop的核心组成部分,它是基于Google的GFS(Google File System)论文设计的,能在普通硬件上实现高容错性和高吞吐量的数据存储。HDFS的特点包括对硬件故障的高容忍度(通过数据备份实现),以及对大规模数据访问的高吞吐支持。系统中有三个关键角色:NameNode负责存储元数据,DataNode存储实际数据并定期向NameNode报告,而Client则作为业务访问接口,从NameNode和DataNode获取数据。
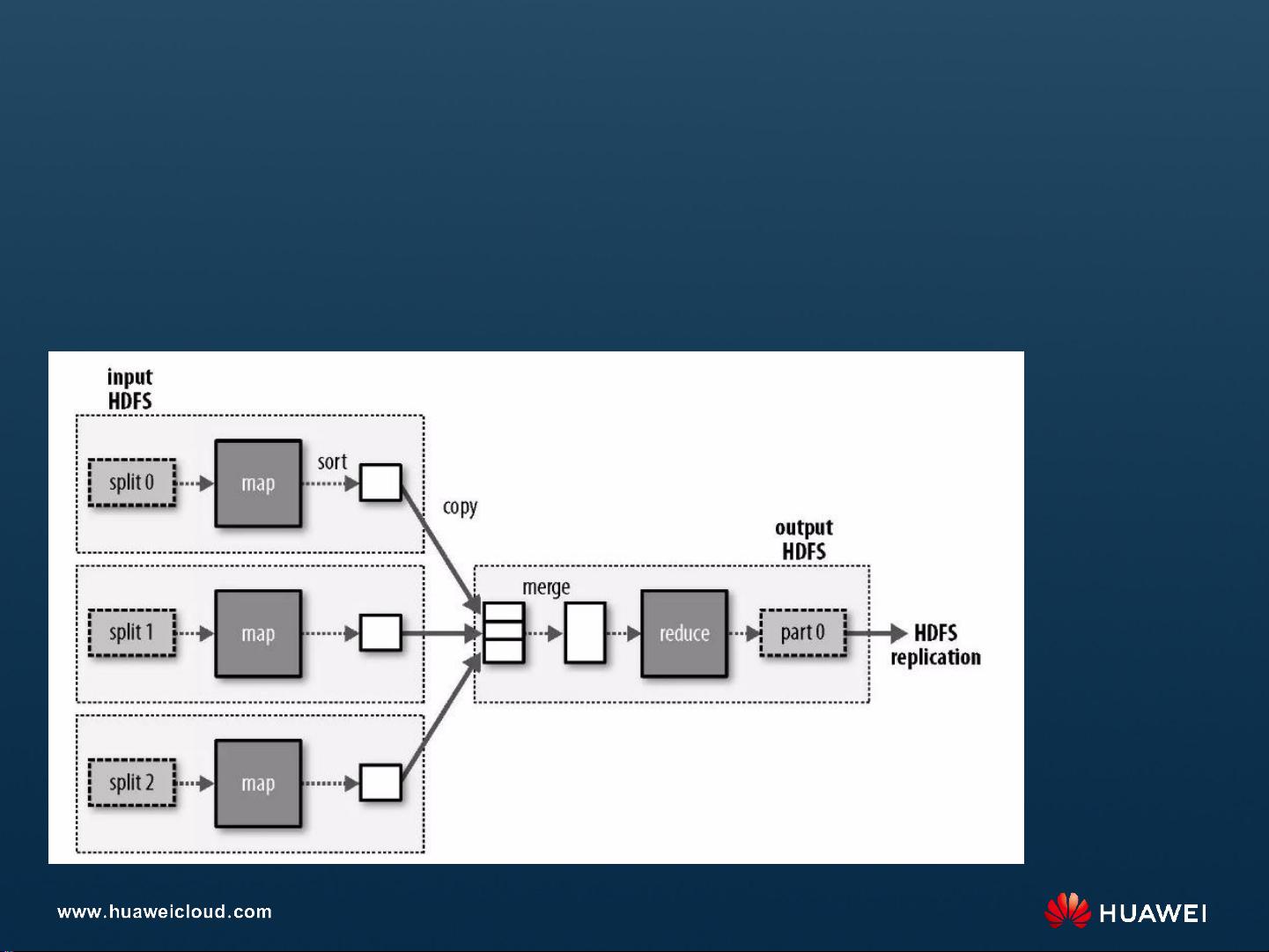
MapReduce是Hadoop中处理大数据的关键计算框架,它简化了编程模型,允许开发者只需定义“做什么”,而系统会自动处理“怎么做”的细节。Map阶段将数据分解为键值对,Reduce阶段则对这些键值对进行聚合,从而实现数据的并行处理。这种分而治之的策略使得处理海量数据变得高效。
此外,YARN(Yet Another Resource Negotiator)作为Hadoop 2.0引入的资源管理系统,超越了MapReduce的范围,成为一个通用的资源调度平台,能够支持多种计算框架,例如Spark和Storm,增强了Hadoop的灵活性和扩展性。
1.1 MapReduce服务课程资料不仅覆盖了MapReduce的基本概念和工作原理,还涉及到Hadoop生态系统中的其他重要组件,为学习者提供了一套全面的大数据处理知识框架。通过深入学习,学员能够掌握如何在实际场景中应用MapReduce进行大数据分析和处理。
6
Hadoop:大数据的开源解决方案
MapReduce
• MapReduce基于Google发布的分布式计算框架Map/Reduce论文设计开发,用于大规
模数据集的并行运算,特点如下:
易于编程:程序员仅需描述做什么,具体怎么做交由系统的执行框架处理。
剩余26页未读,继续阅读
2017-06-06 上传
2022-02-27 上传
2021-05-02 上传
2022-05-23 上传
2023-06-25 上传
2010-07-25 上传
2022-08-04 上传
点击了解资源详情
点击了解资源详情

caoxiaoping
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
