掌握K-Means聚类算法:原理、过程与应用
需积分: 3 38 浏览量
更新于2024-09-09
收藏 2.21MB PPT 举报
K-means算法是一种广泛应用在数据挖掘中的无监督学习方法,其核心目标是根据数据对象之间的相似性进行聚类,将数据划分为预定义数量的类别,通常用于了解数据分布情况或作为其他复杂分析的前置步骤。该算法以划分法为基础,具有简单高效的特点。
算法的基本原理如下:
1. **定义与功能**:
- K-means是基于划分的聚类算法,它假设每个数据对象属于一个且仅属于一个聚类。
- 它的主要功能包括:分析数据集的结构,提供数据的直观表示,以及作为特征提取和分类任务的预处理手段。
2. **工作流程**:
- K-means过程分为两个主要步骤:
- 初始化阶段:随机选择k个数据对象作为初始聚类中心(或质心)。
- 分配和更新阶段:循环进行以下操作:(a) 计算每个数据点到所有聚类中心的距离,并将其归入最近的聚类;(b) 更新每个聚类的质心,即新成员的平均值。
- 直到目标函数(如标准方差之和)停止变化,或者达到预定的最大迭代次数,算法终止。
3. **聚类结果的不确定性**:
- K-means的结果依赖于初始聚类中心的选择,不同的初始化可能导致不同的聚类结果。这是该算法的一个缺点,因为它可能陷入局部最优解,而不是全局最优。
4. **分类方法的多样性**:
- 虽然以K-means为代表,但聚类算法还有其他类型,如层次聚类(自底向上或自顶向下),基于密度的DBSCAN,基于网格的划分(如K-d树),以及基于模型的方法(如高斯混合模型)等。
5. **应用局限**:
- K-means对异常值敏感,不适用于非球形分布的数据,而且对于类别间的大小差异也很敏感。因此,对于非理想的数据集,可能需要其他方法进行调整或组合使用。
总结来说,K-means算法是一种基础但强大的聚类工具,尤其适用于大规模数据集的简单分群。理解其工作原理和局限性,有助于更好地应用到实际数据分析项目中。同时,结合其他聚类方法,可以提高聚类结果的稳定性和有效性。
Your company slogan
Your company slogan
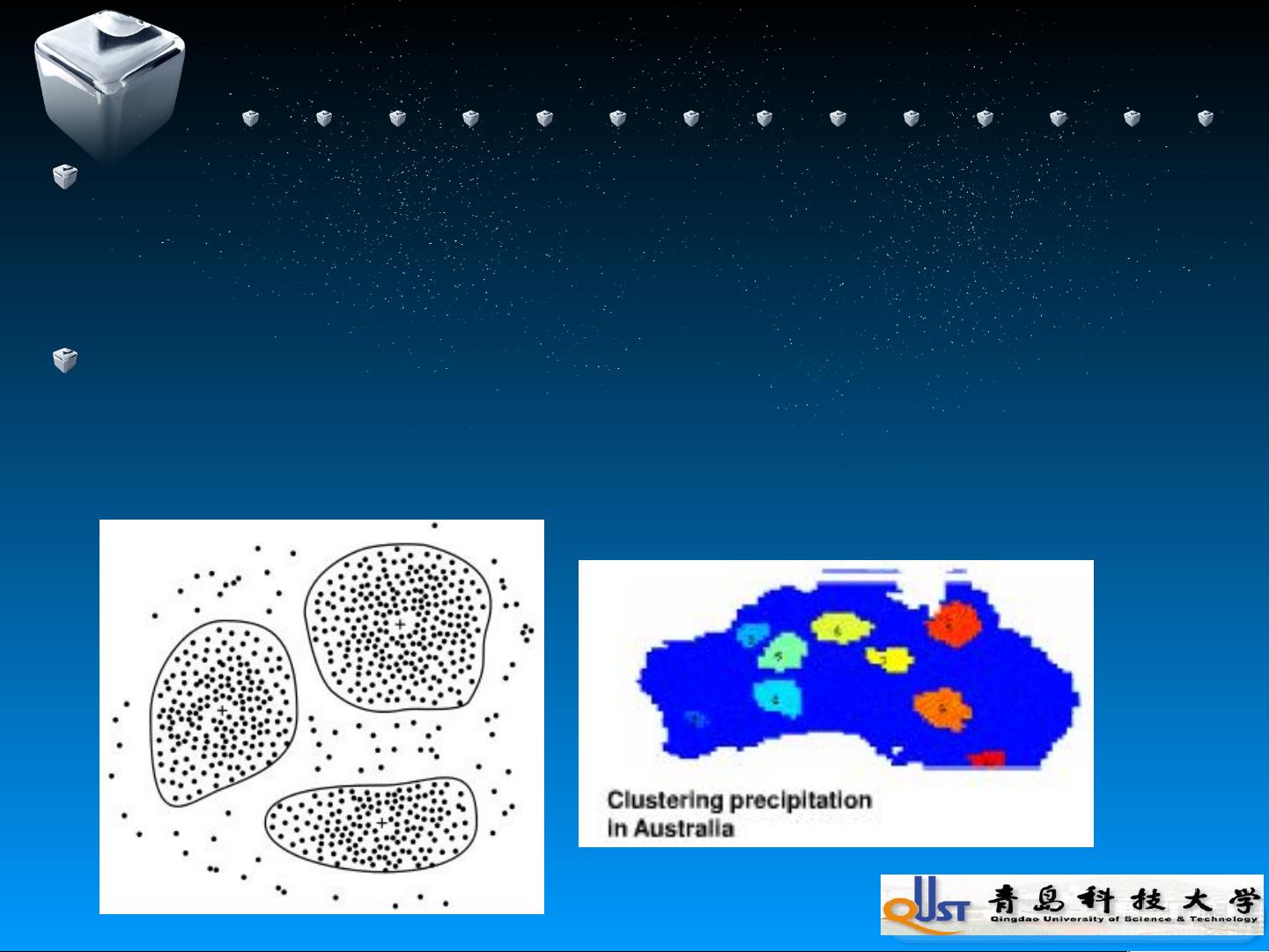
聚类
聚类
定义
按照事物间的相似性进行区分和分类的过程,是无监督的分
类(没有预定义的类编号)。
功能
作为一个独立的工具来获得数据分布情况
作为其他算法(如:特征和分类)的预处理步骤
下载后可阅读完整内容,剩余7页未读,立即下载
181 浏览量
9702 浏览量
181 浏览量
1464 浏览量
2023-10-22 上传
117 浏览量
156 浏览量
2025-01-06 上传

巴啦啦小魔怪
- 粉丝: 2
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- HackUconn2021
- Extension Serial Gramera-crx插件
- 图像变换之小波变换.rar
- 现场监测员:Projeto desenvolvido durante o curso de Go da alura
- java笔试题算法-ARACNe-AP:通过互信息的AP推理进行网络逆向工程
- enas_model:使用ENAS自动构建深度学习模型
- Goldmine-crx插件
- 食品、百货部员工标准化服务及考核细则
- 荣誉
- 易语言源码易语言使用汇编调用子程序.rar
- laravel-wordful:只是Laravel的一个简单博客包
- Traffic-Signs-and-Object-Detection:这是我们的SIH 2018项目,可检测与交通相关的物体,例如交通标志,车辆等
- 初级java笔试题-cs-material:cs-材料
- Blogr-Landing-Page:前端导师的挑战
- 西点面包店长工作手册
- obs-studio.rar
