PaddleDetection VOC版训练教程:从设置到模型生成
需积分: 0 104 浏览量
更新于2024-08-04
收藏 1.07MB DOCX 举报
本篇教程是关于如何使用PaddleDetection进行物体检测的详细指南,主要针对VOC数据集。以下是关键步骤和配置:
1. **配置训练集**:
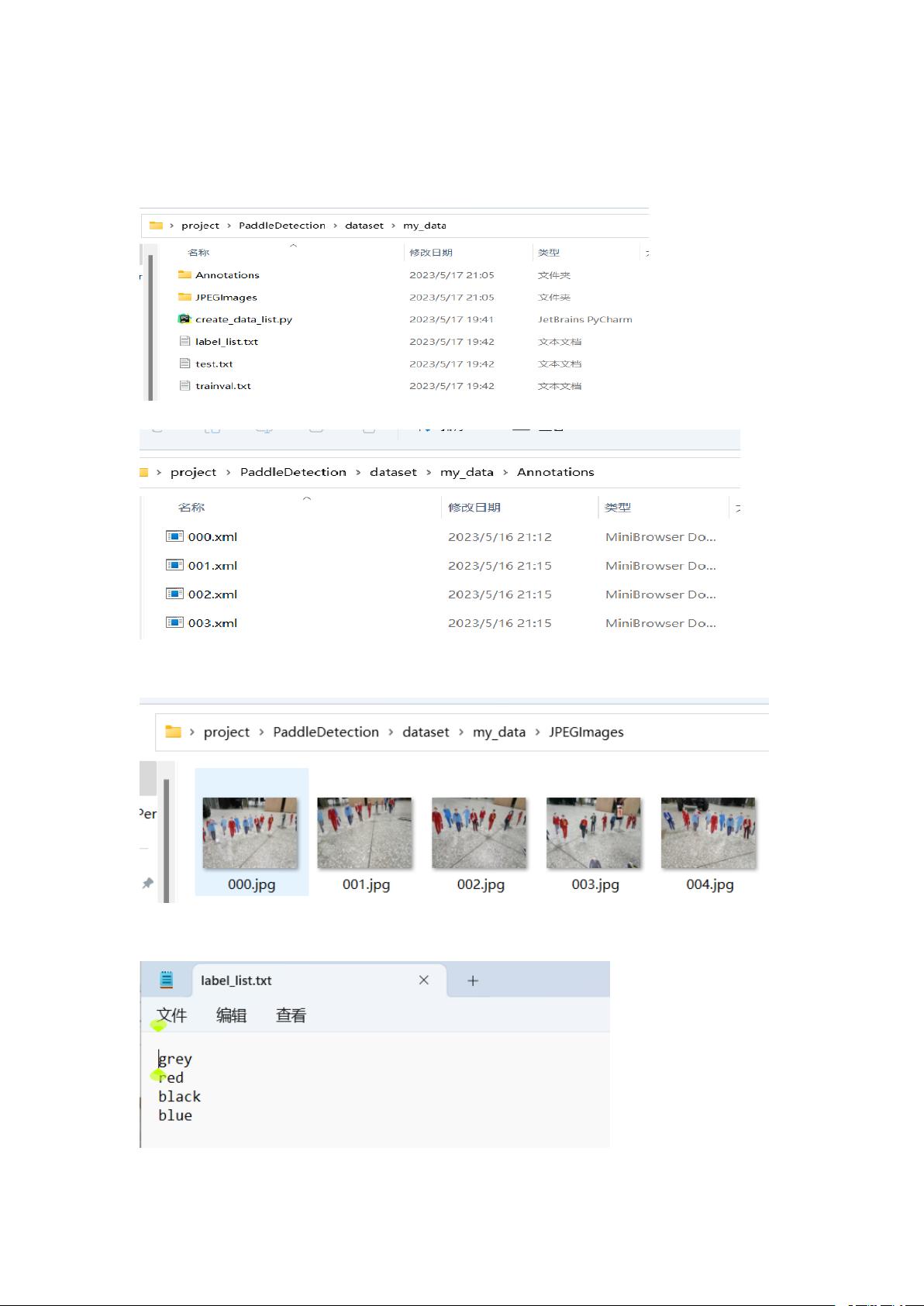
- 创建一个名为`my_data`的文件夹在`paddledetection`目录下,用于存放数据集结构,包括Annotations(XML格式的标注)、JPEGImages(图片)和label_list.txt(图片类别列表)。
- 使用`create_data_list.py`脚本生成trainval.txt和test.txt文件,虽然测试集可以为空,但训练集必须遵循特定格式。
2. **修改配置文件**:
- `voc.yml`文件位于`PaddleDetection/configs/yolov3`目录,用于指定模型的参数,如数据集路径和类别数量。你需要更新该文件中与label_list.txt对应的类目数量,并调整`num_classes`。
- `yolov3_reader.yml`在`PaddleDetection/configs/yolov3/_base_/yolov3_reader.yml`,用于设置训练时的批处理大小,根据你的GPU性能(如3050Ti),可能需要调整`batch_size`。
3. **开始训练**:
- 在搭建好的环境中执行`pythontools/train.py -c configs/yolov3/yolov3_mobilenet_v1_270e_voc.yml`命令。如果训练过程卡在权重加载提示,可能意味着`batch_size`过大,需要减小。
- 训练完成后,会在`paddledetection/output`目录下生成`model_final.pdparams`模型权重文件。
4. **使用训练集进行预测**:
- 将待分类的图片放在`paddledetection/demo`目录中,然后运行`pythontools/infer.py`脚本进行物体检测。注意这里的指令应该包含具体的图片路径。
通过这个教程,你可以了解到如何设置和训练PaddleDetection模型,以及如何使用预训练的模型对新的图片进行物体检测。整个流程包括数据准备、配置文件调整、模型训练和部署到实际应用场景。如果你遇到任何问题,可以根据文档提供的信息进行调试,或者查阅PaddleDetection的官方文档获取更深入的帮助。
Paddledetection 使用教程 VOC 版
一、配置训练集文件:
1、在 paddledetection 文件夹下的 dataset 创建 my_data 文件夹
2、按图示创建对应的 Annotations(存放标注后的 xml)
3、JPEGImages 存放照片
4、label_list.txt 照片分类的种类
下载后可阅读完整内容,剩余4页未读,立即下载
411 浏览量
1315 浏览量
220 浏览量
2025-01-22 上传
2025-01-22 上传
110 浏览量
2022-12-16 上传
221 浏览量
266 浏览量

Moyukok
- 粉丝: 126
 我的内容管理
展开
我的内容管理
展开







最新资源
- Javaweb与ASP项目源码及论文合集
- 龙邱蓝牙参数修正上位机V1.02管理员身份运行指南
- Laravel模板开发教程与实践指南
- Notepad++ 6.5.4发布,新增FTP插件简化Linux远程编辑
- tiny+cdx防跳V1.4正式版发布
- STC89C51单片机CAN总线通讯C语言程序开发
- JavaScript框架Captain-Falcon深入解析
- 伟福icexplorerw/T仿真器绝版驱动发布
- JLink_V686a驱动程序发布,支持国产MCU烧录
- Huntress: PHP开发者的多功能机器人框架
- 深入探索Flash版Logo语言999的编程奥秘
- C# ASP.net实现文件夹压缩下载功能
- 开源WEB开发项目sarticle_html的快速安装与功能扩展指南
- MATLAB开发案例:实现C均值聚类算法
- Uroboros:GNU/Linux单进程监控分析工具介绍
- Destiny 2蓝品自动拆解工具Blue Dismantler
