Spark技术解析:速度与整合优势
需积分: 12 49 浏览量
更新于2024-07-18
收藏 3.67MB PPTX 举报
"Spark技术分享,涵盖了Spark的基本概念、安装、SparkSQL以及SparkStreaming,强调了Spark在效率和多框架整合方面的优势。分享者为向静,内容来源于2018年的技术分享总结。"
Spark是分布式计算领域的一个重要工具,它在2009年由加州大学伯克利分校AMPLab实验室发起,现由Databricks公司维护。Spark的主要目标是在Hadoop MapReduce的基础上提供更高的计算效率,特别是在迭代算法和交互式查询方面。与MapReduce相比,Spark通过支持有向无环图(DAG)计算和中间结果缓存,显著减少了数据写磁盘的次数,从而提高了性能。此外,Spark使用多线程启动任务,任务启动速度快,理论上计算速度比Hadoop快10到100倍。
选择Spark的原因之一是其高效性。Spark的内存计算模型使得它在迭代计算和交互式查询中表现出色,例如在2014年的排序基准测试中,Spark创造了新的记录。另一个关键优点是它能够整合多个框架,如SparkCore用于批处理,SparkSQL用于结构化数据查询,SparkStreaming处理实时流数据,以及SparkMLlib支持机器学习算法。这样的整合消除了不同框架间的语言不一致,降低了大数据平台的复杂性和维护成本。
SparkSQL是Spark用于处理结构化数据的部分,它可以与Hive兼容,允许用户使用SQL查询数据,同时提供了DataFrame和DataSet接口,使得数据操作更加方便和高效。DataFrame是基于Spark的核心RDD(弹性分布式数据集)的抽象,提供了一种更高级别的、跨语言的数据操作API,而DataSet则进一步引入了类型安全和面向对象的概念。
SparkStreaming则是Spark处理实时数据流的模块,它将数据流分解为小的微批次(DStream),并利用SparkCore的并行处理能力来实现低延迟的流处理。这种方式既保持了Spark的高效率,又能够处理实时数据流的需求。
Spark以其高效的计算性能、多框架整合能力和对实时处理的支持,成为了大数据处理领域的重要工具。无论是进行批量分析、交互式查询还是实时流处理,Spark都能提供一套统一且强大的解决方案。
Spark 安装
Spark install
运行分为三种模式:
一、 ('( 模式 :集群资源由 $ 自己管理
二、 GH :集群资源交个 G( 管理
三、 IJ 模式:集群资源交给 (( 管理( 是 下的开源分布式资源管理框架)
下面 我们会讲到 ('( 和 G( 的模式的配置,以及如何搭建高可用的 集群。
是用 ' 语言开发的, ' 是运行在 <K 上面的。
准备: 安装 LD (不做讲解)
安装 ' :
:下载 ' (下载路径: M=>>FFF''())> ) - 我这里安装的是 ' 版本的
= 解压即安装
E :配置环境变量
9;BJIA>>''>9L>'
9/AN/=N;BJI>(
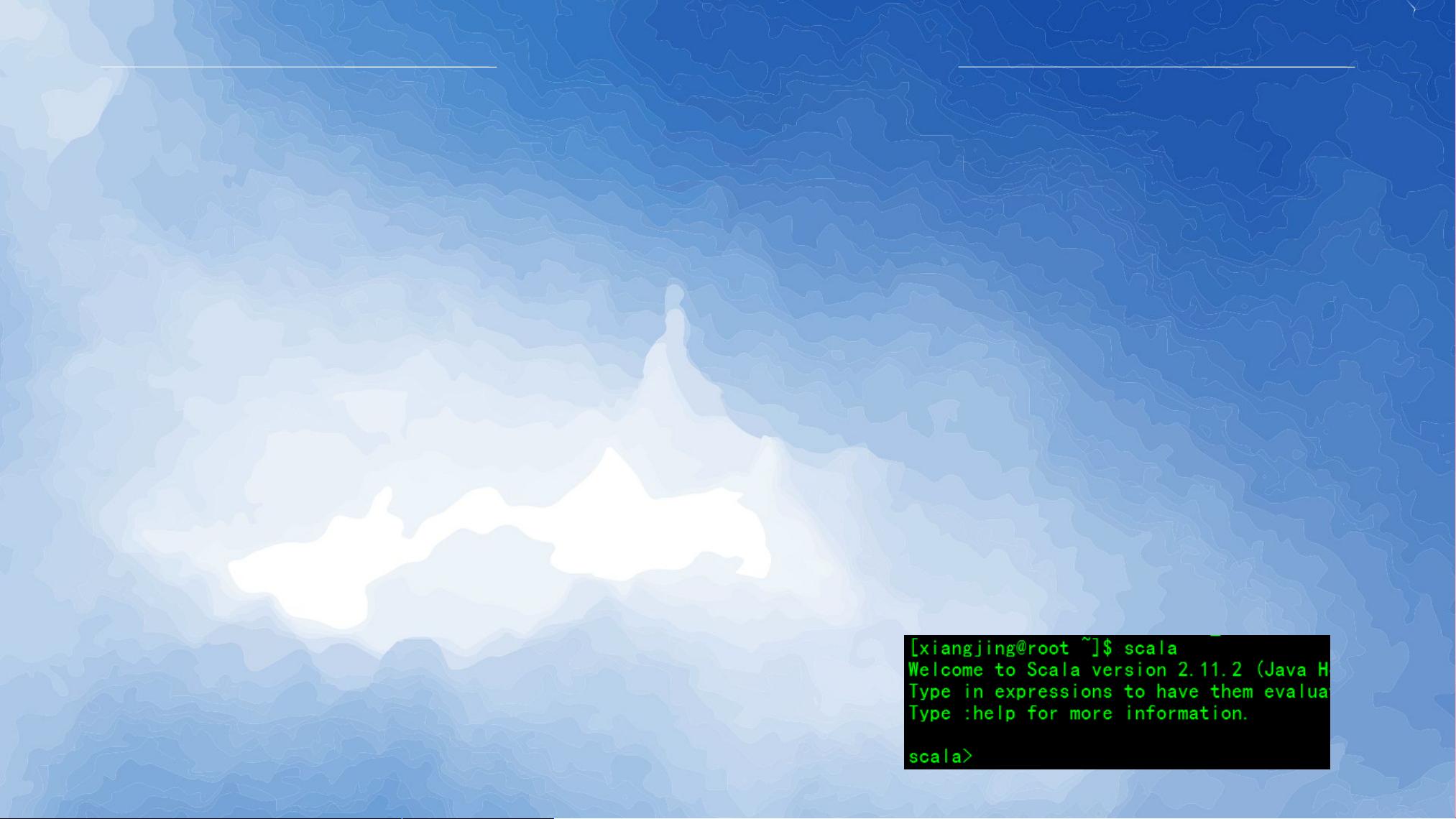
:测试:输入 ' ,显示 ' 版本信息,并且
进入 ' 的交互式窗口则成功,如右图
所示:


剩余61页未读,继续阅读
2021-02-26 上传
2023-06-28 上传
2023-08-27 上传
2023-03-16 上传
2023-12-12 上传
2023-05-26 上传
2023-03-24 上传

时光易逝111
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
