YOLO系列详解:从YOLOv1到YOLOv2
需积分: 50 96 浏览量
更新于2024-07-18
3
收藏 4.99MB PPTX 举报
"YOLO系列PPT详细解读YOLOv1和YOLOv2的物体检测技术"
YOLO,全称为"You Only Look Once",是由Joseph Redmon等人提出的一种实时物体检测系统。它以其高效、实时性以及端到端的训练方式在计算机视觉领域引起了广泛关注。YOLO的主要思想是将图像分割成多个小的网格(grid cells),每个网格负责预测出可能存在的物体及其位置。相比于早期的基于区域提议(如RCNN系列)的方法,YOLO简化了流程,避免了多步处理,从而大大提高了检测速度。
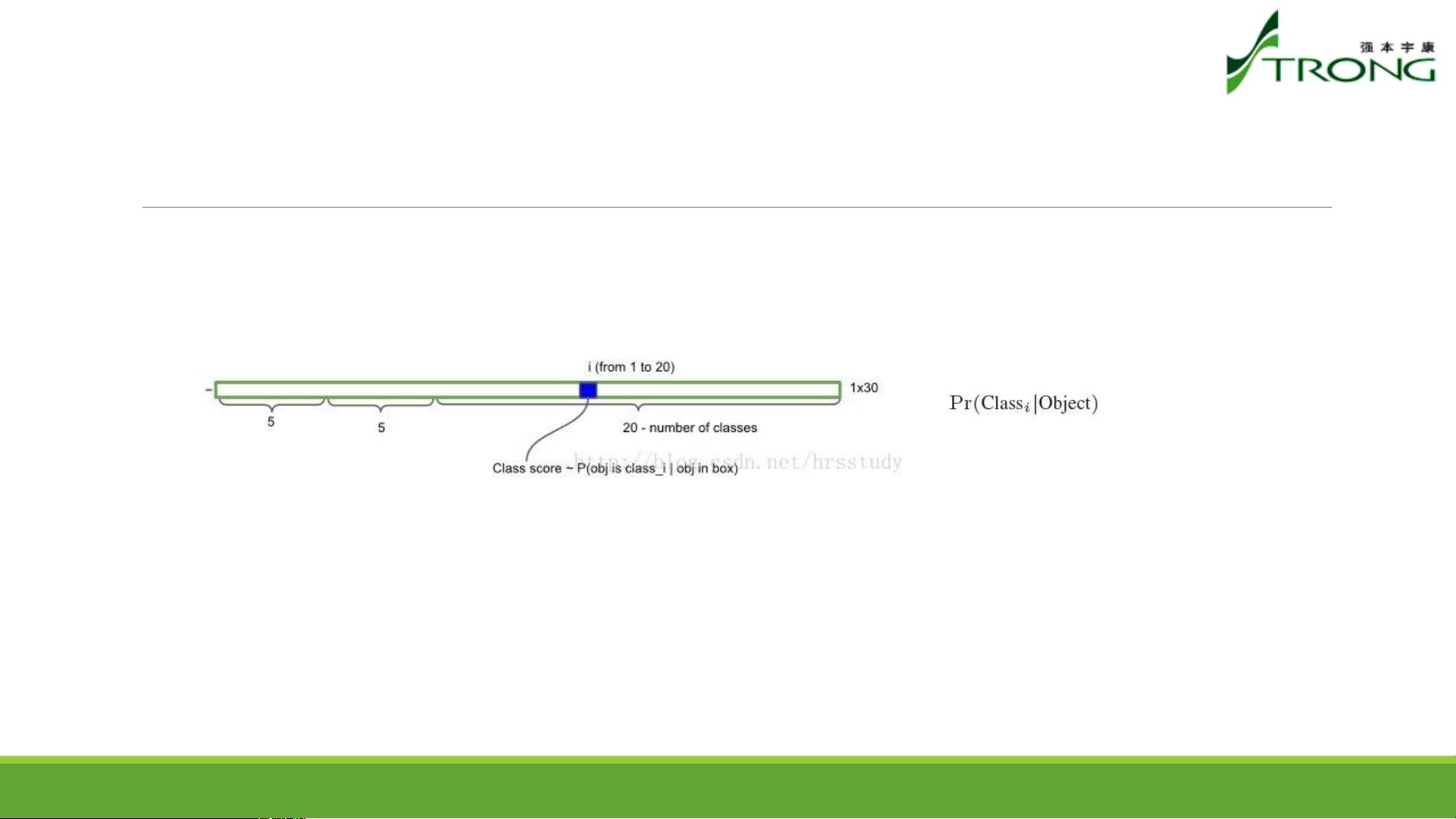
YOLOv1的核心在于其简洁的设计。首先,输入图像会被调整至固定尺寸,如448*448。接着,图像通过神经网络进行处理,输出包括边界框坐标、置信度和类别的概率。每个网格会预测B个边界框,其中每个框由5个参数表示:中心点相对网格的坐标(x, y),宽度(w)和高度(h)的比例,以及一个置信度分数。置信度分数不仅表达了框内存在物体的可能性,还反映了框预测的准确性,即与真实边界框的IOU(Intersection over Union)。
测试阶段,每个网格的条件类别概率与每个边界框的置信度相乘,得到每个类别的得分。然后,针对每个类别,设定阈值过滤低分边框,进行非极大值抑制去除重复检测,最后确定每个框的归属类别,生成最终的检测结果。
YOLOv2在此基础上进行了优化,引入了更多的卷积层、批归一化、多尺度训练等技术,提高了检测精度,同时保持了较快的检测速度。例如,使用预训练的ImageNet分类模型初始化卷积层,有助于模型更快收敛。此外,YOLOv2引入了锚点(anchor boxes),以更好地适应不同尺度和比例的物体,减少了对固定大小边界框的依赖。
YOLO系列模型通过其独特的设计,实现了高效的实时物体检测,成为计算机视觉领域的重要里程碑。其后续版本如YOLOv3、YOLOv4等继续优化了架构,进一步提升了检测性能,尤其是在处理小物体和提高精度方面取得了显著进步。

测试过程
对每个 有 个 : $$%$&$ condence
坐标 $ 代表了预测的 的中心与栅格边界的相对值。D
坐标 %$& 代表了预测的 的 %& 、 && 相对于整幅图像
%&$&& 的比例。
condence 就是预测的 bounding box 和 ground truth box 的 IOU 值。D
剩余32页未读,继续阅读
375 浏览量
149 浏览量
1765 浏览量
348 浏览量
174 浏览量
325 浏览量

y6239810y
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页自动刷新工具 v1.1 - 自定义时间间隔与关机
- pt-1.4协程源码深度解析
- EP4CE6E22C8芯片三相正弦波发生器设计与实现
- 高效处理超大XML文件的查看工具介绍
- 64K极限挑战:国际程序设计大赛优秀3D作品展
- ENVI软件全面应用教程指南
- 学生档案管理系统设计与开发
- 网络伪书:社区驱动的在线音乐制图平台
- Lettuce 5.0.3中文API文档完整包下载指南
- 雅虎通Yahoo! Messenger v0.8.115即时聊天功能详解
- 将Android手机转变为IP监控摄像机
- PLSQL入门教程:变量声明与程序交互
- 掌握.NET三层架构:实例学习与源码解析
- WPF中Devexpress GridControl分组功能实例分析
- H3Viewer: VS2010专用高效帮助文档查看工具
- STM32CubeMX LED与按键初始化及外部中断处理教程
