推荐引擎揭秘:工作原理与实现策略
需积分: 10 65 浏览量
更新于2024-07-27
收藏 400KB PDF 举报
"IBM-探索推荐引擎内部的秘密"
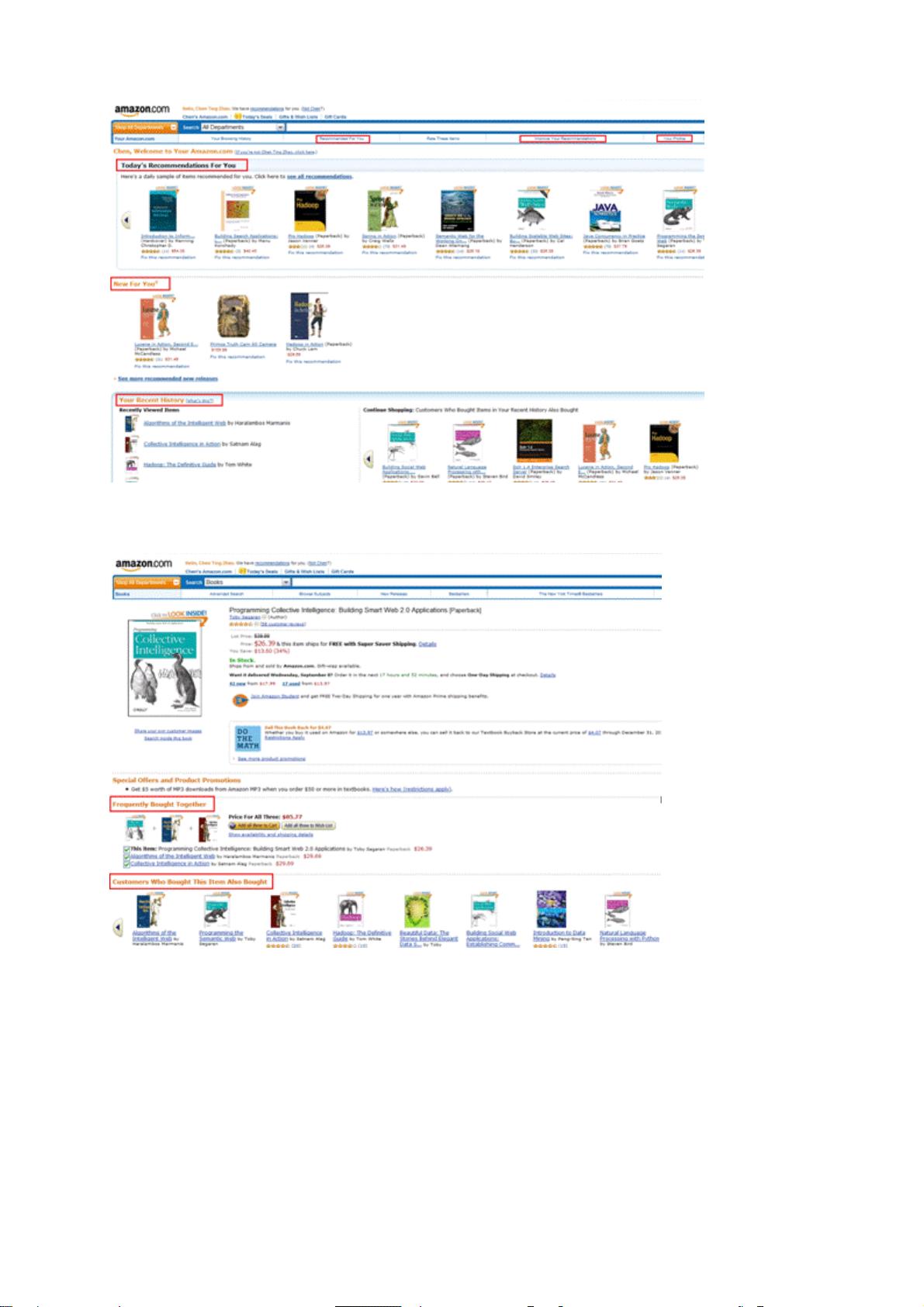
推荐引擎是一种智能的信息过滤系统,它通过分析用户的个人历史行为、兴趣偏好、社交网络等多维度数据,为用户提供个性化的内容推荐。推荐引擎的发展源于信息过载的问题,传统搜索引擎虽然在寻找具体目标信息方面表现出色,但在面对用户可能模糊不清或难以准确描述的需求时,往往力不从心。
推荐引擎的工作原理主要包括协同过滤、基于内容的推荐和混合推荐三种主要机制:
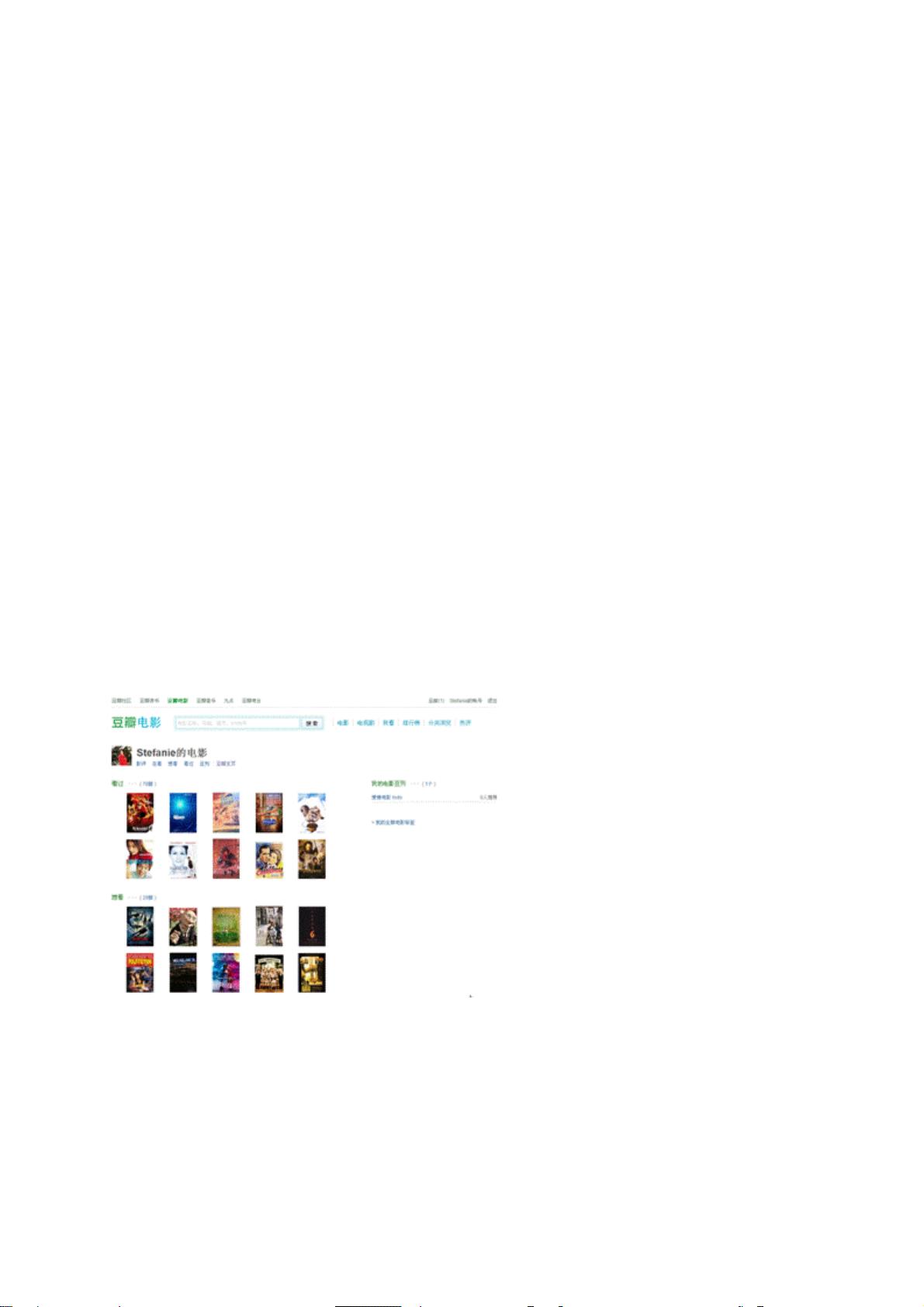
1. 协同过滤:这是最常见的推荐方法,分为用户-用户协同过滤和物品-物品协同过滤。用户-用户协同过滤基于用户历史行为的相似性,如果两个用户过去的行为模式相似,那么预测他们未来可能会对同一物品有相同的喜好。物品-物品协同过滤则侧重于物品之间的关联性,如果一个用户喜欢某物品,推荐引擎会推荐他可能喜欢的相似物品。
2. 基于内容的推荐:这种方法依赖于对物品的深入理解,通过分析用户过去的偏好,找出用户喜欢的特定属性或特征,然后推荐具有这些特性的其他物品。例如,如果用户喜欢看科幻电影,系统会推荐更多科幻类型的影片。
3. 混合推荐:结合了协同过滤和基于内容的推荐,以提高推荐的准确性和多样性。混合推荐可以克服单一方法的局限性,如协同过滤可能存在的冷启动问题(新用户或新物品缺乏行为数据),以及基于内容推荐可能的窄化推荐范围。
在实现推荐引擎时,通常会运用到机器学习和数据挖掘的技术,如聚类和分类算法。聚类用于将用户或物品分组,找出相似的群体;分类则帮助识别物品的类别,以便更好地匹配用户需求。Apache Mahout是一个流行的大数据机器学习框架,可用于实现这些推荐策略。在大规模数据上运行推荐算法,需要考虑效率和性能优化,以确保推荐系统的实时性和可扩展性。
推荐引擎不仅在电子商务领域发挥着关键作用,帮助用户在海量商品中找到可能感兴趣的产品,而且广泛应用于社交媒体、音乐、电影和图书分享平台,提供个性化的娱乐内容推荐。随着大数据和人工智能的进一步发展,推荐引擎将继续进化,提供更加精准和个性化的服务,满足用户多样化的需求。
•
•
剩余46页未读,继续阅读
2010-05-10 上传
2018-04-11 上传
2019-10-21 上传
2023-07-24 上传
2023-05-30 上传
2023-09-12 上传
2023-11-05 上传
2023-05-30 上传
2024-01-21 上传

lagron
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
