系统学习NLP:从基础到深度探索
下载需积分: 10 | DOC格式 | 876KB |
更新于2024-08-29
| 193 浏览量 | 举报
"自然语言处理学习宝典涵盖了从基础到深度学习的全面NLP知识,包括概率统计、机器学习、文本挖掘、词嵌入、序列标注、语言模型、分布式表征和各种NLP任务。"
在系统地学习自然语言处理(NLP)时,首先需要建立坚实的基础。基础部分包括对概率统计的理解,这是所有数据分析和机器学习的基石。深入学习概率论和统计学,如概率分布、假设检验和最大似然估计等,将为后续的NLP学习打下稳固的基础。
接着,进入机器学习领域,学习线性回归、逻辑回归、正则化等基本模型,这些都是构建预测模型的基础。非概率方法如支持向量机(SVM)和决策树也应有所了解。同时,了解聚类算法(如K-means、DBSCAN)和降维技术(如PCA、t-SNE)有助于数据预处理和特征提取。训练技巧,如梯度下降、随机梯度下降及其变种,对于优化模型参数至关重要。
文本挖掘是NLP中的重要环节,用于从大量文本中抽取有价值的信息。基本流程涉及文本预处理、信息提取和情感分析等。图论在NLP中用于表示语义关系,文档分析关注文本结构和内容理解,而词嵌入则通过向量化表示词语,实现语义相似性的计算。
序列标注是NLP中的另一关键任务,如命名实体识别(NER)、词性标注等,这些需要理解序列模型,如隐马尔科夫模型(HMM)、条件随机场(CRF)以及后来的循环神经网络(RNN)和长短时记忆网络(LSTM)。
语言模型是NLP的核心,它们学习语言的统计规律,如编码器-解码器模型在机器翻译中的应用。从词表征到上下文表征的进步,如BERT和XLNet,揭示了如何通过预训练模型捕捉词汇的上下文信息。
分布式表征,如GloVe和Word2Vec,是词嵌入的经典方法,它们提供了一种有效的方式将词汇映射到高维空间,使计算机可以理解词语的语义。
最后,NLP的任务部分涵盖了广泛的应用,如机器翻译(MT)、问答系统(QA)、阅读理解(Reading Comprehension)和情绪分析(Sentiment Analysis)。掌握这些任务的模型架构和评估指标,意味着你已经具备了处理实际NLP问题的能力。
学习NLP需要系统地掌握概率统计、机器学习基础、文本挖掘、序列模型、词嵌入、上下文表征和各种NLP任务,这是一个深度与广度并重的学习过程,需要持续探索和实践。
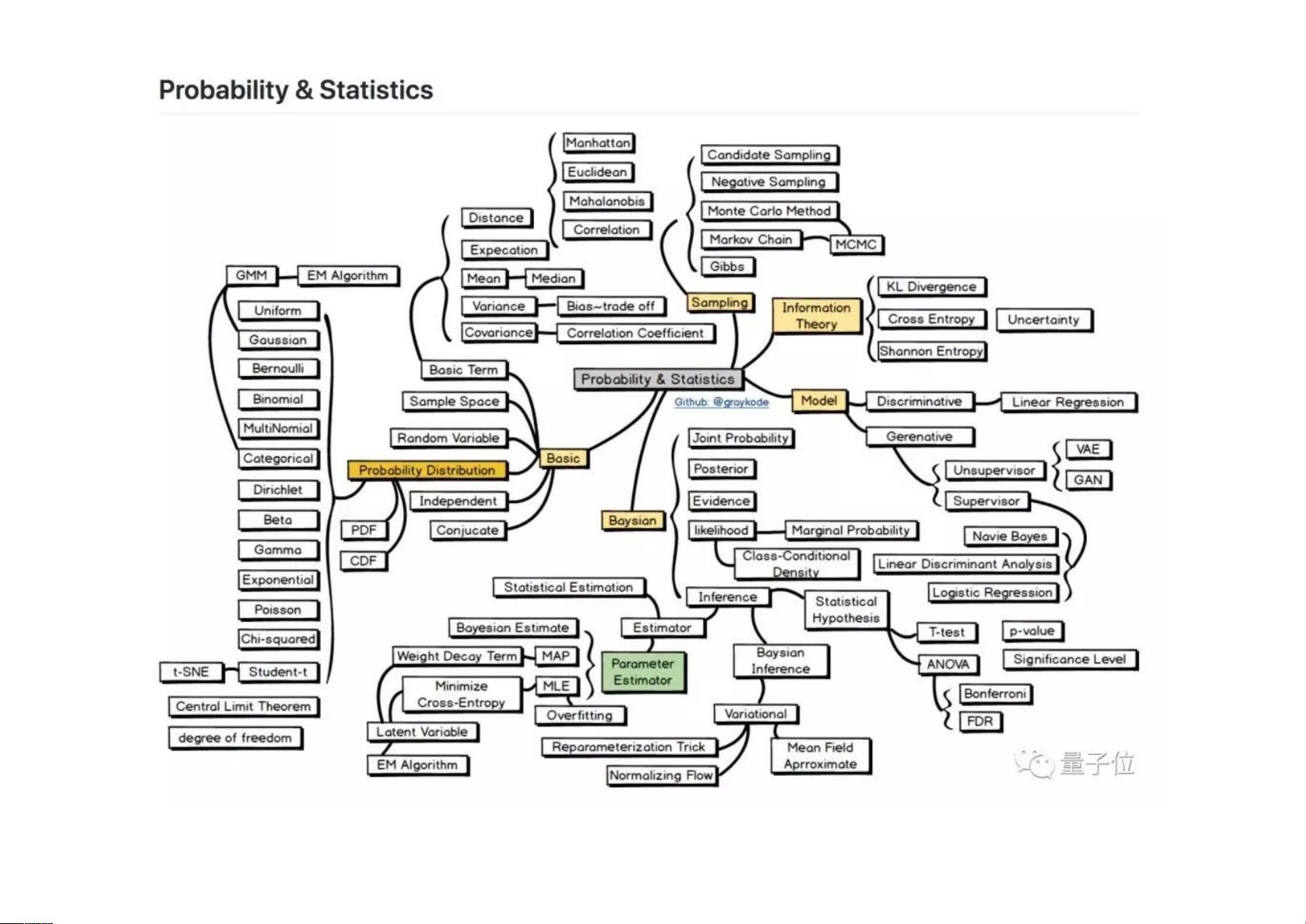
从中间的灰色方块,发散出 5 个方面:基础 (Basic) ,采样 (Sampling) 、信息理论 (Information Theory) 、模型 (Model) ,以及贝叶斯 (Baysian) 。每个方面,都有许多知识点和方法,需
要你去掌握。毕竟,有了概率统计的基础,才能昂首挺胸进入第二个板块。
下载后可阅读完整内容,剩余4页未读,立即下载
相关推荐
1394 浏览量
160 浏览量
2024-03-31 上传
233 浏览量
2021-11-20 上传
2022-11-11 上传
2023-10-08 上传
2024-05-05 上传
2025-03-11 上传

lssxzzxyz
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开








最新资源
- POJ1584题解:解法与AC代码分析
- NUSadgers开发的HackNRoll2021游戏指南
- PhpSou搜索引擎体验版v2.0:后台验证优化与模板整合
- 固定资产管理系统源代码实现与功能介绍
- 自定义View打造简单安卓折线图界面
- Protel 99SE新手电路设计入门教程详解
- AS3.0开发的道具连连看小游戏
- 用友NC各版本表关系图详细解读
- MATLAB神经网络在遥感图像分类中的应用及程序下载
- 掌握拉格朗日插值法:Matlab实现与应用示例
- 精密机械设计基础实验及微电子应用
- CSDN博客系统前台框架代码的深度解析与应用
- 北大POJ1408-Fishnet题解及AC代码解析
- Excel数据汇总与写入辅助工具的使用
- 南大傲拓NA400 PLC模块CAD图纸发布
- 实现拖放功能在Matlab中的应用与开发
