大数据实战:Hadoop、Spark与NoSQL技术深度解析
需积分: 9 119 浏览量
更新于2024-07-20
收藏 14.1MB PDF 举报
本资源是一份关于大数据处理和分析的实战教程,涵盖了Hadoop、Spark、NoSQL等关键技术和应用。课程以"大数据面临的挑战"为起点,首先阐述了大数据时代的特性,特别是4V特征(Volume大容量、Variety多样性、Velocity高速度和Value低价值密度),强调了大数据处理的必要性和复杂性。
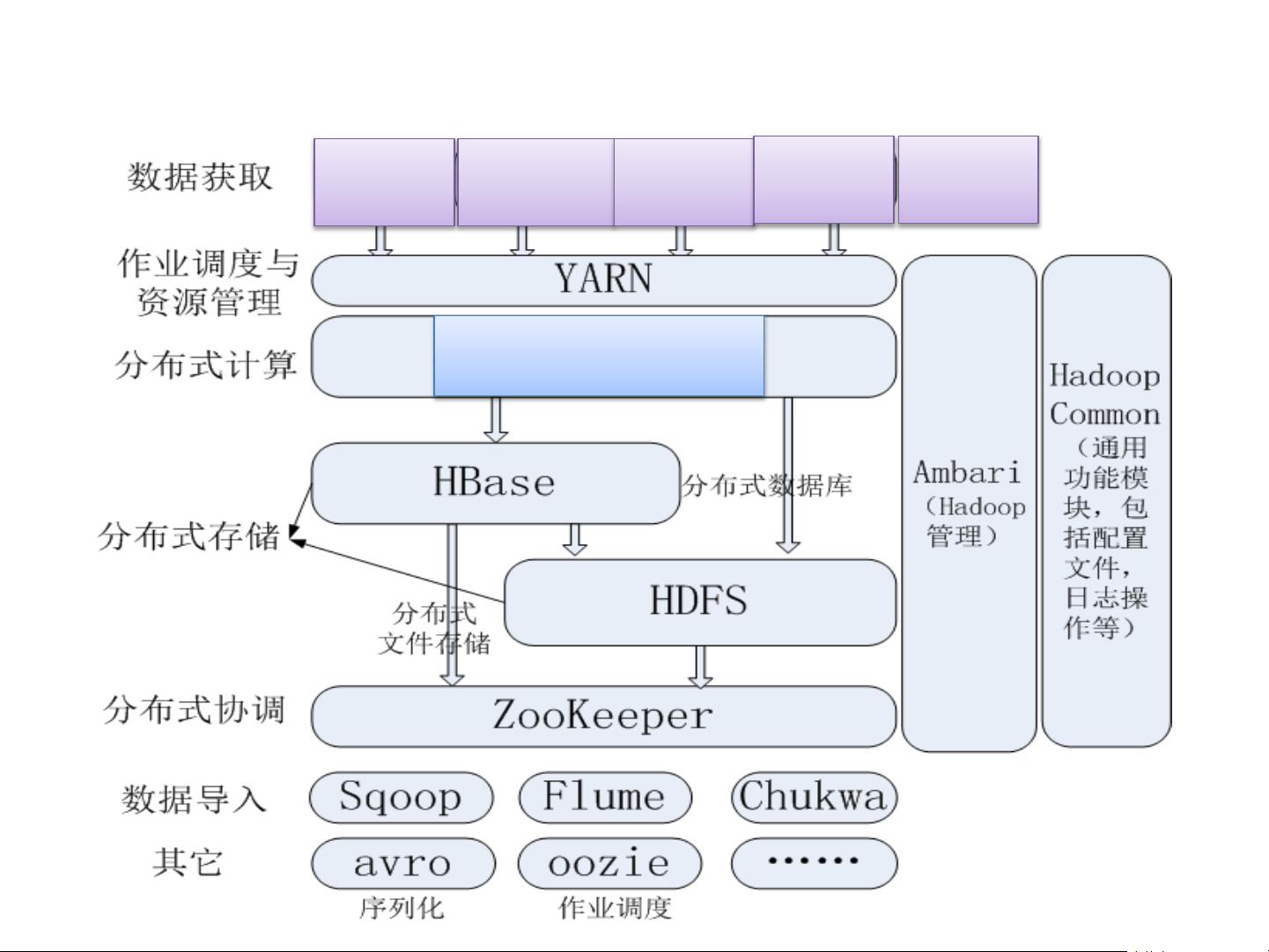
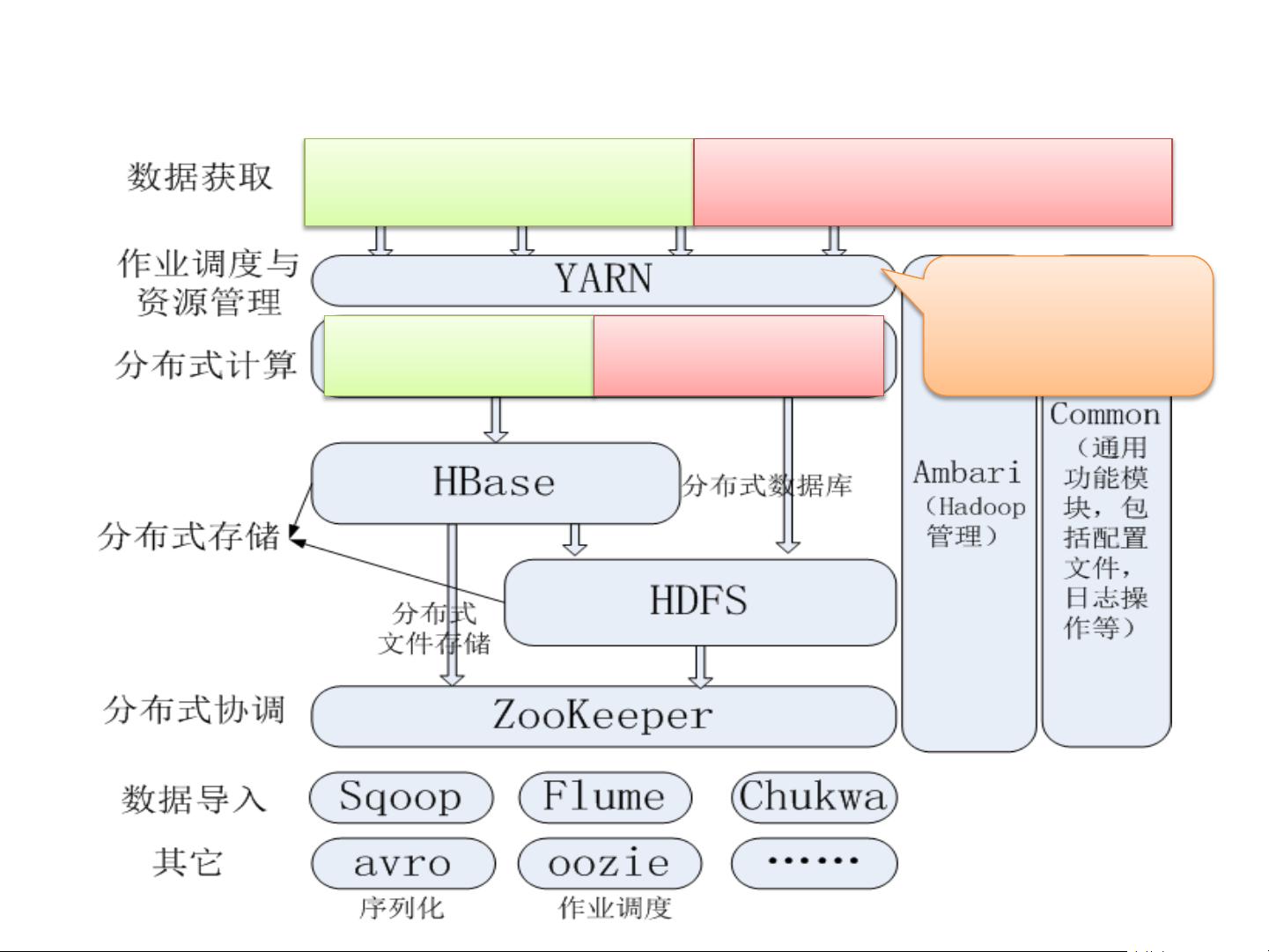
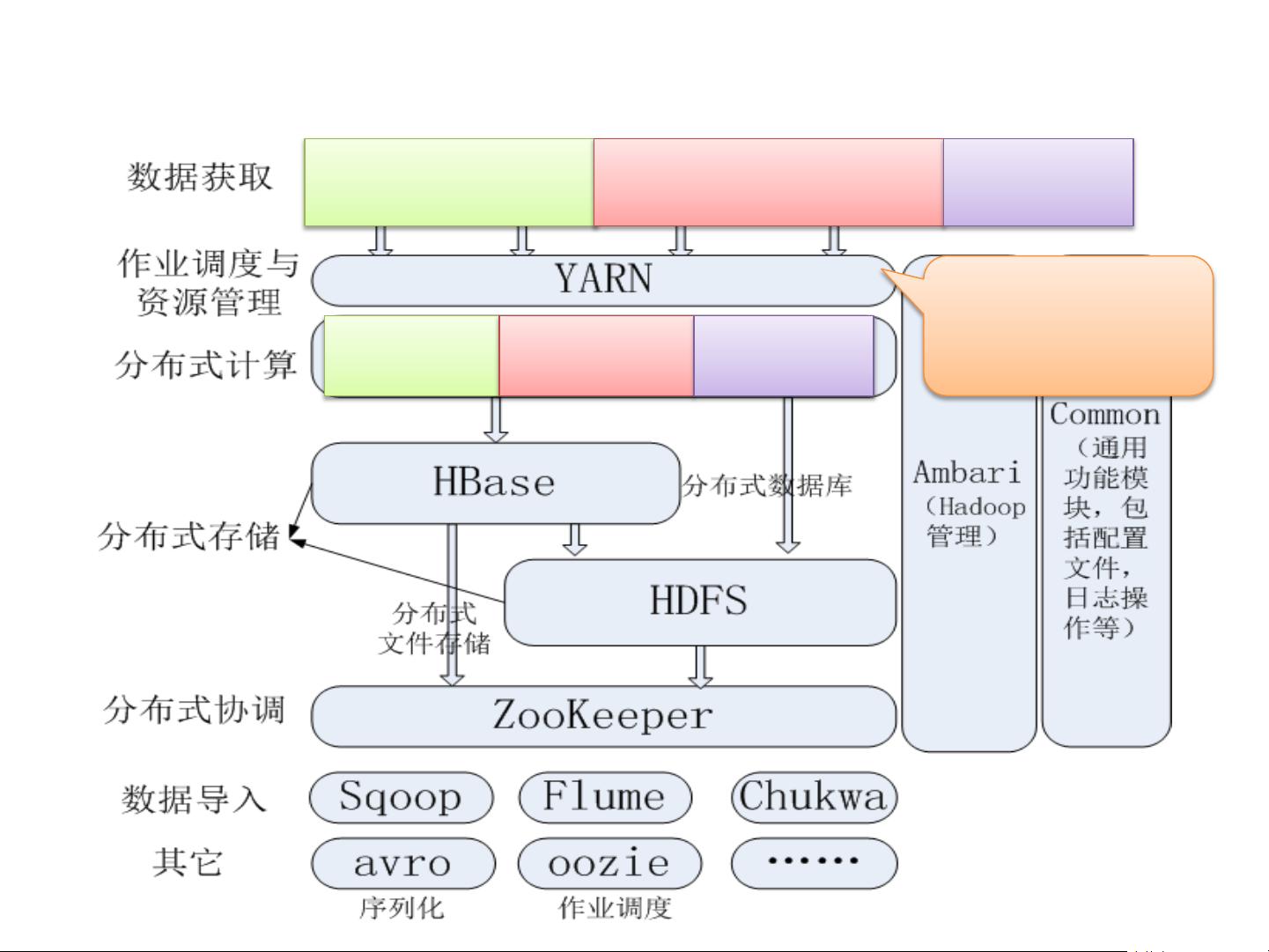
1. **大数据挑战与解决方案**:介绍了大数据所带来的挑战,如数据量巨大、数据类型多样、增长速度快和价值密度低。课程比较了Hadoop与传统大数据解决方案的差异,指出Hadoop作为以分布式计算为核心的解决方案,如HDFS(分布式文件系统)和MapReduce模型,成为主流。
2. **Hadoop技术详解**:深入讲解了Hadoop的核心技术,包括HDFS的分布式存储和MapReduce的并行计算模型。此外,还介绍了Hadoop的其他组件,如Flume用于数据收集,Sqoop用于数据迁移,Hive则提供SQL查询接口以管理大量数据。
3. **NoSQL与HBase实战**:探讨了NoSQL数据库在大数据环境中的应用,特别关注了HBase这种列式存储的分布式数据库,并提供了实战操作示例。
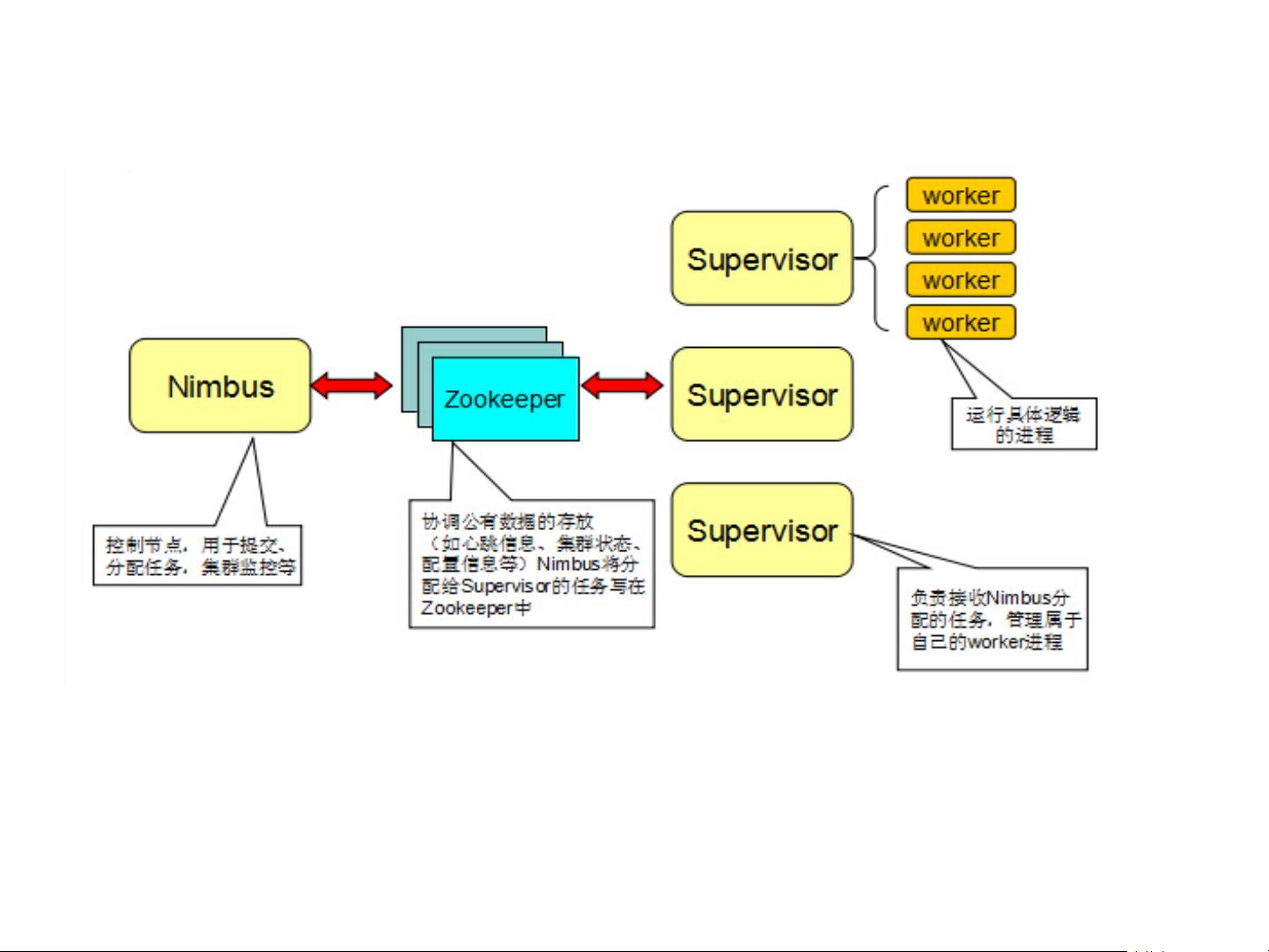
4. **新型大数据技术**:引入了Storm和Spark两个新兴的大数据处理框架。Storm适合实时流处理,而Spark则以其强大的处理能力和可扩展性,支持批处理、交互式查询以及机器学习任务。
5. **Spark实战部分**:详细讲解了Spark Streaming进行实时流处理,以及Spark SQL在大数据分析中的应用,通过实例演示了如何利用Spark的强大功能进行数据分析。
6. **大数据应用场景和体系结构**:课程不仅关注技术层面,还讨论了大数据在实际商业场景中的应用,比如数据平台构建、云计算的集成,以及围绕数据的存储、分析和价值挖掘。
7. **案例解析**:通过互联网大数据的实际案例,帮助学员理解大数据如何赋能商业决策,展示了数据驱动的商业模式和价值提升。
通过这为期两天的培训,目标是使学员掌握数据平台建设、数据处理技术以及如何在商业环境中有效利用大数据,从而实现数据的商业价值。
2016-09-20 上传
2018-01-14 上传
2019-05-21 上传
2021-04-12 上传
2019-05-22 上传
2013-05-24 上传
2017-05-18 上传
2015-09-24 上传
点击了解资源详情

小确兴
- 粉丝: 19
- 资源: 40
 我的内容管理
展开
我的内容管理
展开







