TMS320C6670多核浮点SoC架构与开发指南
需积分: 10 128 浏览量
更新于2024-07-17
收藏 2.36MB PDF 举报
TMS320C6670是一款多核浮点系统级芯片(SoC),专为高性能计算和信号处理应用设计。该文档是C6670芯片的操作手册,提供了深入的架构解析、模块构成以及功能细节,对于芯片的软硬件开发者来说,是极其重要的参考资料。以下是一些关键知识点:
1. **架构与模块组成**:
C6670基于多核心设计,包含固定和浮点运算单元,这允许它同时执行并行任务,提高了处理能力和效率。文档详细描述了芯片的各个核心模块,如处理器内核、协处理器、内存控制器、外设接口等,以及它们之间的连接和协作方式。
2. **内部通信**:
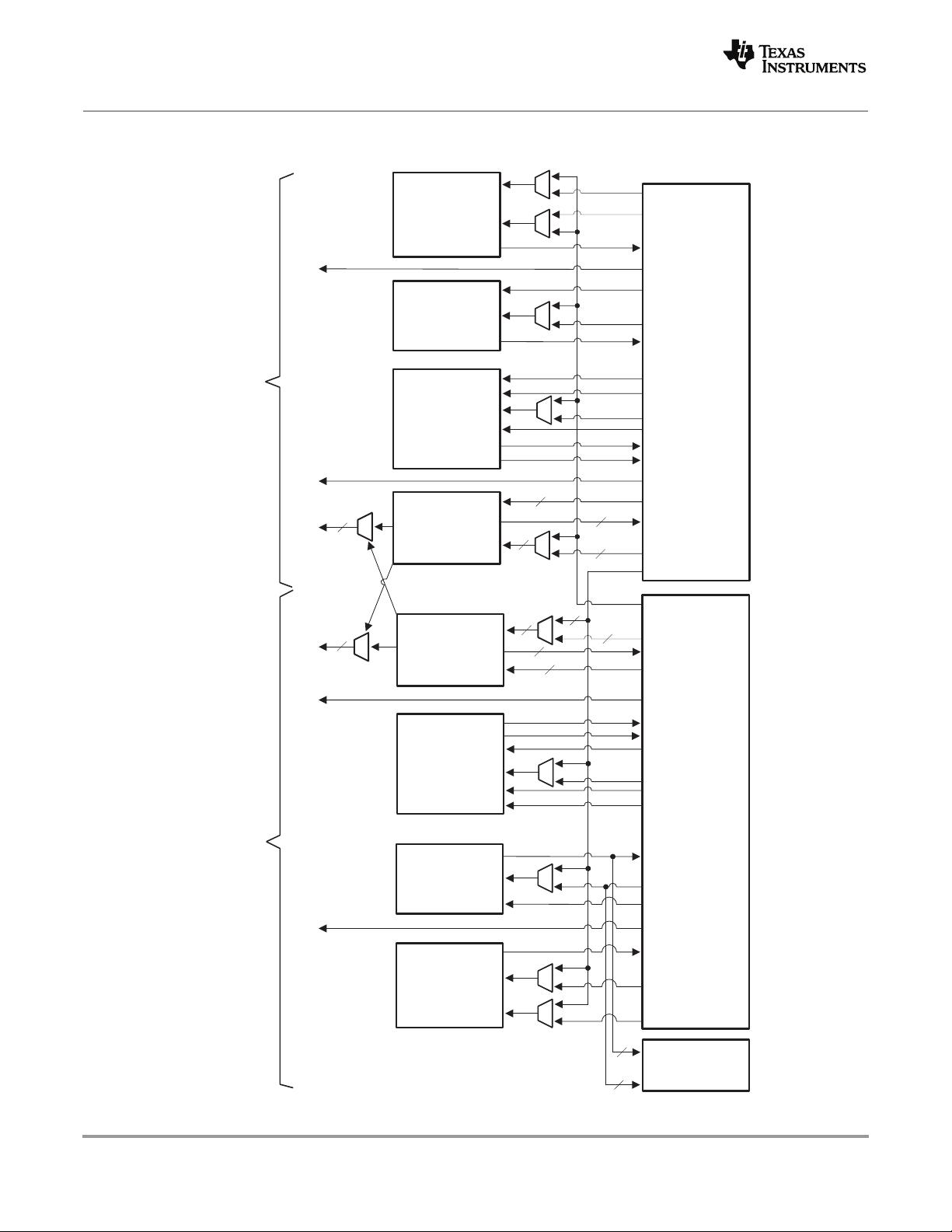
内部通信机制包括Switch Fabric矩阵,这是一种高带宽总线结构,用于快速在各核心之间传输数据。文档中更新了Switch Fabric矩阵表格,包括桥接号和块图,有助于理解其工作原理和配置。
3. **PLL控制**:
芯片使用多个锁相环(PLL)来稳定时钟频率,特别是PASSPLL和主PLL。在Rev.D版本中,对这些PLL的控制部分进行了更新,包括控制寄存器、初始化序列以及限制了SECCTL中的输出分频值。
4. **中断管理**:
TMS320C6670采用了CIC(Core Interface Controller)代替INTC,以及CPT(Core Pointer Tracer)替代Tracer,这可能涉及到中断处理和程序流程跟踪的新方法。
5. **内存支持**:
新增了DDR3 PLL相关控制寄存器,如DDR3PLLCTL1和PASSPLLC,表明芯片能够支持高级内存技术,如DDR3,这对数据吞吐量和系统性能至关重要。
6. **版本历史**:
文档还提供了详细的版本修订历史,以便开发者了解不同版本之间的改进和变更,有助于跟踪技术演进和适应新特性。
通过阅读这份操作手册,开发人员可以深入了解TMS320C6670的硬件特性、软件接口、性能优化和调试方法,确保在实际项目中实现高效和稳定的系统集成。这份文档不仅是芯片的参考指南,也是学习和应用多核处理和嵌入式系统设计的重要资源。
16 TMS320C6670 Features Copyright 2012 Texas Instruments Incorporated
SPRS689D—March 2012
Multicore Fixed and Floating-Point System-on-Chip
TMS320C6670
www.ti.com
Submit Documentation Feedback
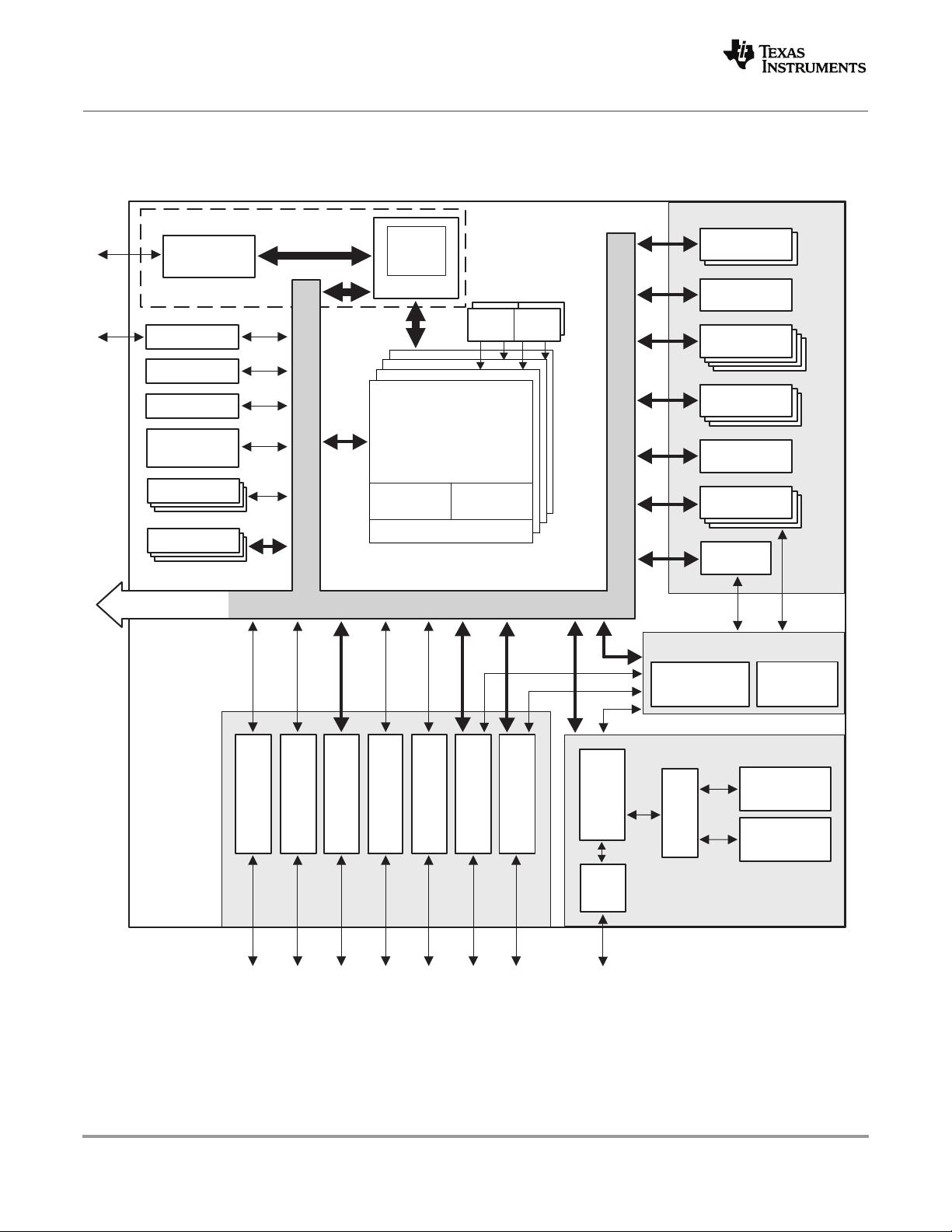
1.3 Functional Block Diagram
Figure 1-1 shows the functional block diagram of the TMS320C6670 device.
Figure 1-1 Functional Block Diagram
4 Cores @ 1.0 GHz / 1.2 GHz
C66x™
CorePac
C6670
MSMC
2MB
MSM
SRAM
64-Bit
DDR3 EMIF
BCP
TCP3e
´3
´3
Coprocessors
VCP2
´4
Power
Management
Debug & Trace
Boot ROM
Semaphore
Memory Subsystem
SRIO 4´
PCIe 2´
UART
AIF2 ´6
SPI
IC
2
Packet
DMA
Multicore Navigator
Queue
Manager
Others
´3
32KB L1
P-Cache
32KB L1
D-Cache
1024KB L2 Cache
RSA RSA
´2
PLL
EDMA
´3
HyperLink
TeraNet
Network Coprocessor
Switch
Ethernet
Switch
SGMII
2
´
Packet
Accelerator
Security
Accelerator
FFTC
TCP3d
TAC
´2
RAC


剩余224页未读,继续阅读
2021-05-21 上传
2021-12-02 上传
2014-02-27 上传
2021-08-10 上传
2022-09-20 上传
2022-09-23 上传
2011-05-27 上传
2020-06-04 上传
2019-08-13 上传

wy3650054
- 粉丝: 2
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
