Hadoop MapReduce详解:分布式编程简化
需积分: 10 158 浏览量
更新于2024-07-19
收藏 1.89MB PDF 举报
"Hadoop快速入门,MapReduce架构设计与实现原理"
Hadoop是一个开源的分布式计算框架,专门设计用于处理和存储海量数据。这个框架的核心由两个主要组件构成:MapReduce和HDFS(Hadoop Distributed File System)。MapReduce提供了一种编程模型,使得开发者能够编写出处理大量数据的分布式并行程序,而无需关心底层的分布式存储和通信细节。
MapReduce的工作原理可概括为两个主要阶段:Map和Reduce。在Map阶段,原始数据被分割成多个小块,每个块由一个独立的Map任务处理。Map任务对输入数据进行操作,生成一系列中间键值对。这些中间结果随后被排序并传递给Reduce阶段。Reduce任务则负责聚合Map阶段产生的结果,进行必要的计算,并生成最终的输出。
Hadoop的这一设计极大地简化了分布式编程的复杂性,程序员只需关注业务逻辑,即实现Map和Reduce函数,而框架会自动处理任务调度、负载均衡、容错处理等底层细节。这种抽象使得即使是对分布式计算不熟悉的开发人员也能快速上手。
MapReduce适用于那些可以被分解成独立可并行处理部分的大型数据集。例如,大数据的批量处理、数据分析、日志处理等场景。在Hadoop生态系统中,JobTracker和TaskTracker是MapReduce作业的管理和执行关键角色。JobTracker负责任务调度和监控,分配Map和Reduce任务给各个TaskTracker,而TaskTracker则在各个节点上执行实际的任务。
在Map-Reduce处理过程中,Client进程负责提交作业,JobTracker接收并管理整个作业的生命周期,它会根据集群的资源情况将Map任务和Reduce任务分配给TaskTracker。每个TaskTracker是一个在集群节点上运行的Java进程,它们接收JobTracker的指令,执行分配给它们的Map或Reduce任务,并将进度和状态报告回JobTracker。
Hadoop通过MapReduce提供了一种高效且灵活的处理大数据的方法,使得处理大规模数据集成为可能,同时也降低了并行编程的难度,为大数据分析和挖掘提供了强大的工具。

bin/stop-mapred.sh 脚本会参照 JobTracker 上
${HADOOP_CONF_DIR}/slaves 文件的内容,在所有列出的 slave 上停止
TaskTracker 守护进程。
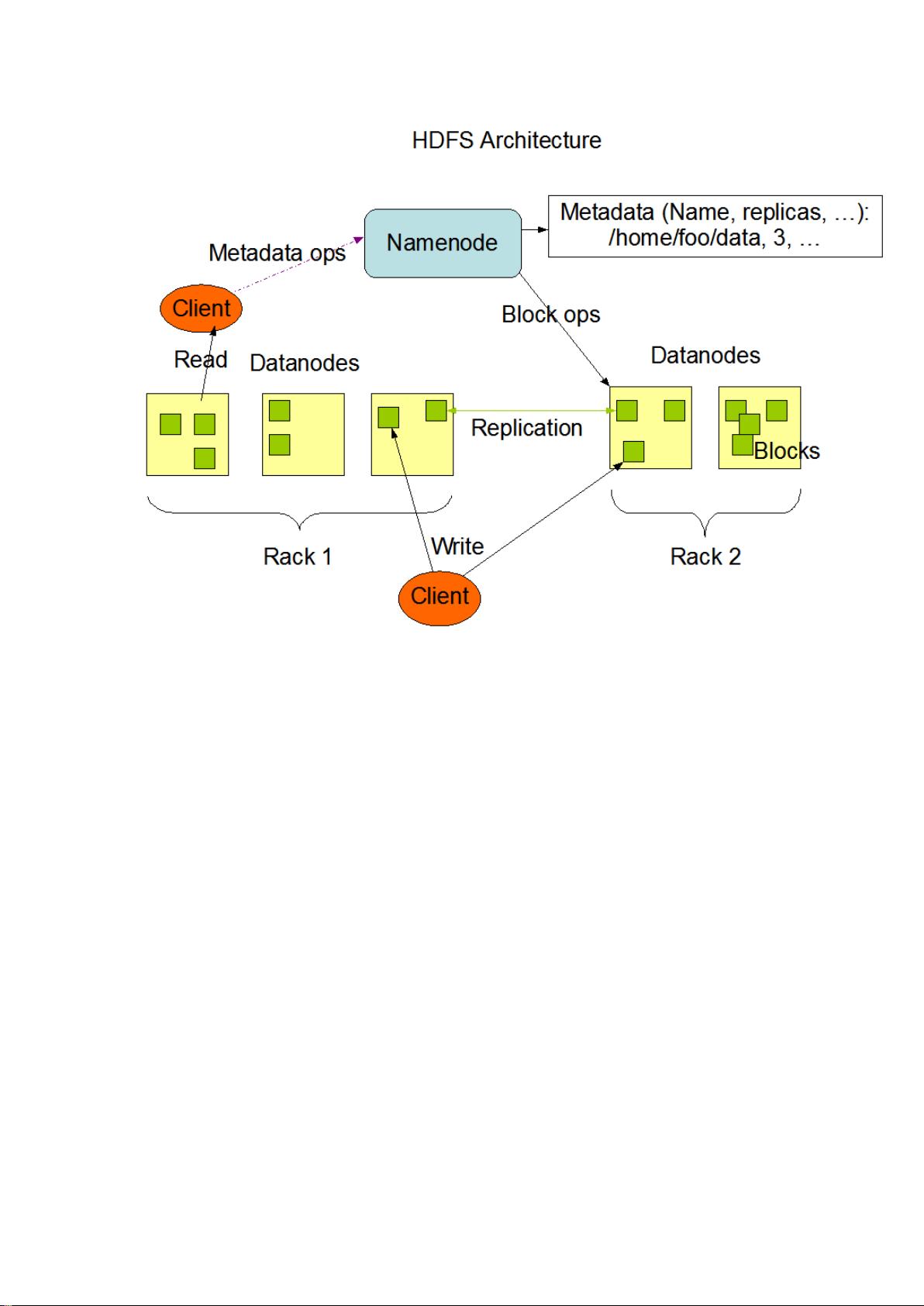
Hadoop 分布式文件系统:架构和设计
引言
Hadoop 分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity
hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,
它和其他的分布式文件系统的区别也是很明显的。HDFS 是一个高度容错性的系统,
适合部署在廉价的机器上。HDFS 能提供高吞吐量的数据访问,非常适合大规模数
据集上的应用。HDFS 放宽了一部分 POSIX 约束,来实现流式读取文件系统数据的
目的。HDFS 在最开始是作为 Apache Nutch 搜索引擎项目的基础架构而开发的。
HDFS 是 Apache Hadoop Core 项目的一部分。这个项目的地址是
http://hadoop.apache.org/core/。
前提和设计目标
硬件错误
硬件错误是常态而不是异常。HDFS 可能由成百上千的服务器所构成,每个服务器
上存储着文件系统的部分数据。我们面对的现实是构成系统的组件数目是巨大的,
而且任一组件都有可能失效,这意味着总是有一部分 HDFS 的组件是不工作的。因
此错误检测和快速、自动的恢复是 HDFS 最核心的架构目标。
流式数据访问
运行在 HDFS 上的应用和普通的应用不同,需要流式访问它们的数据集。HDFS 的
设计中更多的考虑到了数据批处理,而不是用户交互处理。比之数据访问的低延迟
问题,更关键的在于数据访问的高吞吐量。POSIX 标准设置的很多硬性约束对 HDFS
应用系统不是必需的。为了提高数据的吞吐量,在一些关键方面对 POSIX 的语义做
了一些修改。
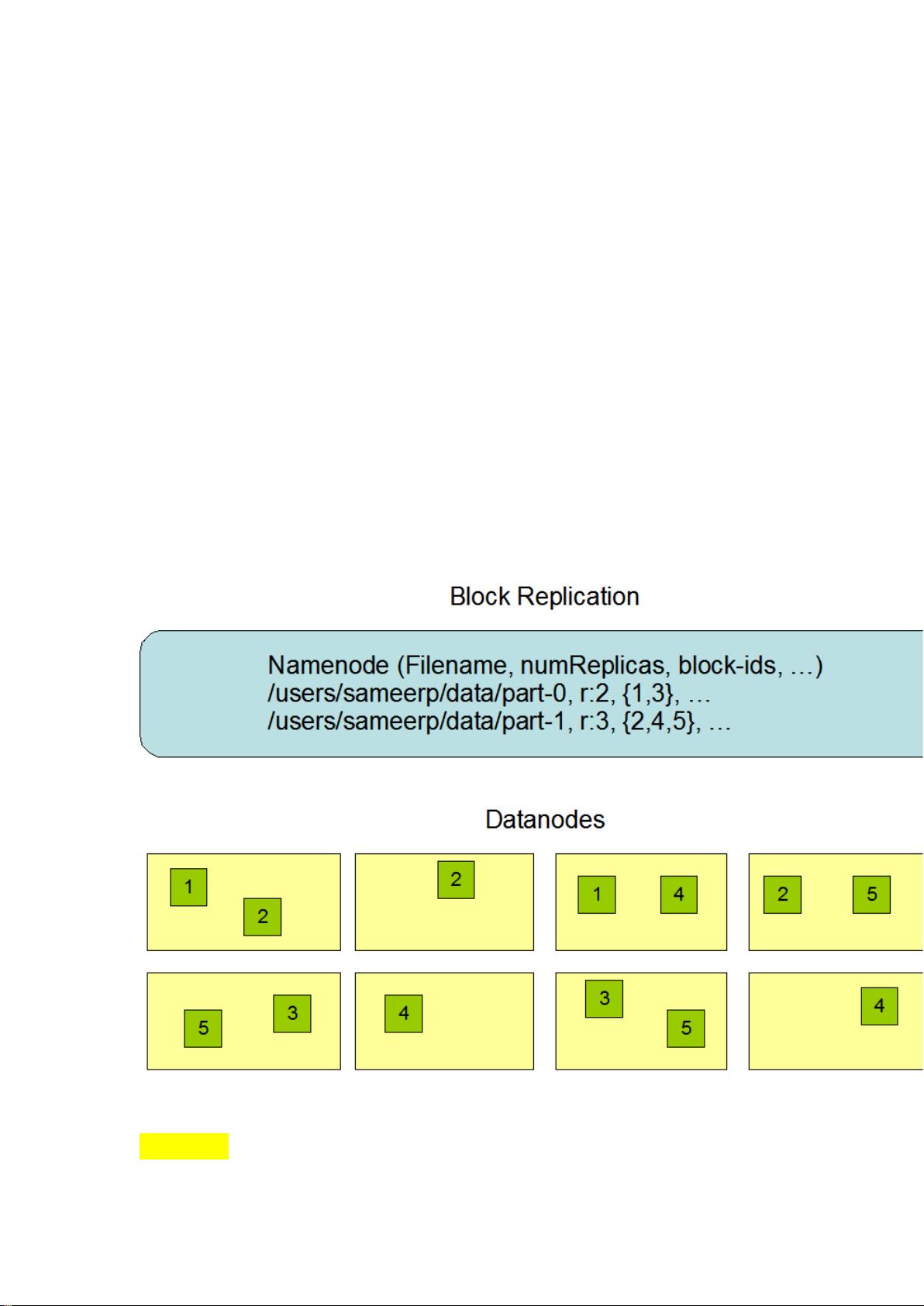
大规模数据集
运行在 HDFS 上的应用具有很大的数据集。HDFS 上的一个典型文件大小一般都在
G 字节至 T 字节。因此,HDFS 被调节以支持大文件存储。它应该能提供整体上高


剩余150页未读,继续阅读
2013-06-19 上传
2010-01-06 上传
2018-04-28 上传
2018-10-14 上传
2015-06-04 上传
2021-10-11 上传

菜鸟一碗好汤
- 粉丝: 1
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
