CUDA C编程指南:版本4.2更新与详解
需积分: 0 84 浏览量
更新于2024-07-26
收藏 3.06MB PDF 举报
"CUDA_C_Programming_Guide"
CUDA(Compute Unified Device Architecture)是NVIDIA推出的一种并行计算平台和编程模型,主要用于利用图形处理器(GPU)进行高性能计算。CUDA C Programming Guide是NVIDIA官方提供的详细指南,用于指导开发者如何利用CUDA C语言进行GPU编程。在Version 4.2中,该指南进行了若干更新和改进,以适应更高级别的设备,如计算能力为3.0的设备,并提供新的功能和优化。
CUDA的核心概念包括以下几个方面:
1. **从图形处理到通用并行计算**:CUDA最初是为了提升图形处理性能而设计,但随着时间的发展,它已扩展成为一个能执行广泛通用计算任务的平台,允许开发者利用GPU的并行计算能力。
2. **CUDA架构**:CUDA是一种通用的并行计算架构,通过GPU的多处理器(multiprocessors)实现大规模并行运算。在Version 4.2中,更新了关于计算能力为3.0的设备的信息,这些设备通常具有更高的内存带宽和更多的CUDA核心,能够处理更复杂的计算任务。
3. **可扩展的编程模型**:CUDA提供了一个层次化的线程模型,包括线程块、线程网格、流和事件等概念,允许程序员高效地组织和同步大量并发执行的任务。
4. **内存层次结构**:CUDA内存包括全局内存、共享内存、常量内存、纹理内存和寄存器,每种都有其特定的访问速度和使用场景。更新后的指南可能更详细地介绍了这些内存类型在计算能力3.0设备上的表现。
5. **异构编程**:CUDA支持在CPU和GPU之间进行混合编程,允许开发者充分利用两者的优势。开发者可以将计算密集型部分分配给GPU,而将控制逻辑保留在CPU上。
6. **计算能力**:每个CUDA兼容的GPU都有一个计算能力,它定义了设备的特性,如SIMD宽度、浮点精度支持等。在Version 4.2中,增加了对计算能力3.0设备的支持。
7. **编程接口**:CUDA编程涉及到使用NVCC编译器,该编译器有离线编译和即时编译两种工作模式,处理CUDA源代码并生成针对不同GPU架构的二进制。此外,还有关于二进制兼容性和链接选项的讨论,确保代码能在不同设备上运行。
8. **新功能**:在Version 4.2中,新增了关于warp shuffle函数的Section B.13,这些函数允许在同一warps(一组32个线程)内的线程之间交换数据,提供了更高效的内部通信机制。
CUDA C Programming Guide详细阐述了这些概念和接口,是CUDA编程的重要参考资料。通过深入理解和应用这些知识,开发者可以编写出高效利用GPU并行性的程序,显著提高计算效率。

Chapter 1. Introduction
4 CUDA C Programming Guide Version 4.2
solve many complex computational problems in a more efficient way than on a
CPU.
CUDA comes with a software environment that allows developers to use C as a
high-level programming language. As illustrated by Figure 1-3, other languages,
application programming interfaces, or directives-based approaches are supported,
such as FORTRAN, DirectCompute, OpenCL, OpenACC.
Figure 1-3. CUDA is Designed to Support Various Languages
and Application Programming Interfaces
1.3 A Scalable Programming Model
The advent of multicore CPUs and manycore GPUs means that mainstream
processor chips are now parallel systems. Furthermore, their parallelism continues
to scale with Moore’s law. The challenge is to develop application software that
transparently scales its parallelism to leverage the increasing number of processor
cores, much as 3D graphics applications transparently scale their parallelism to
manycore GPUs with widely varying numbers of cores.
The CUDA parallel programming model is designed to overcome this challenge
while maintaining a low learning curve for programmers familiar with standard
programming languages such as C.
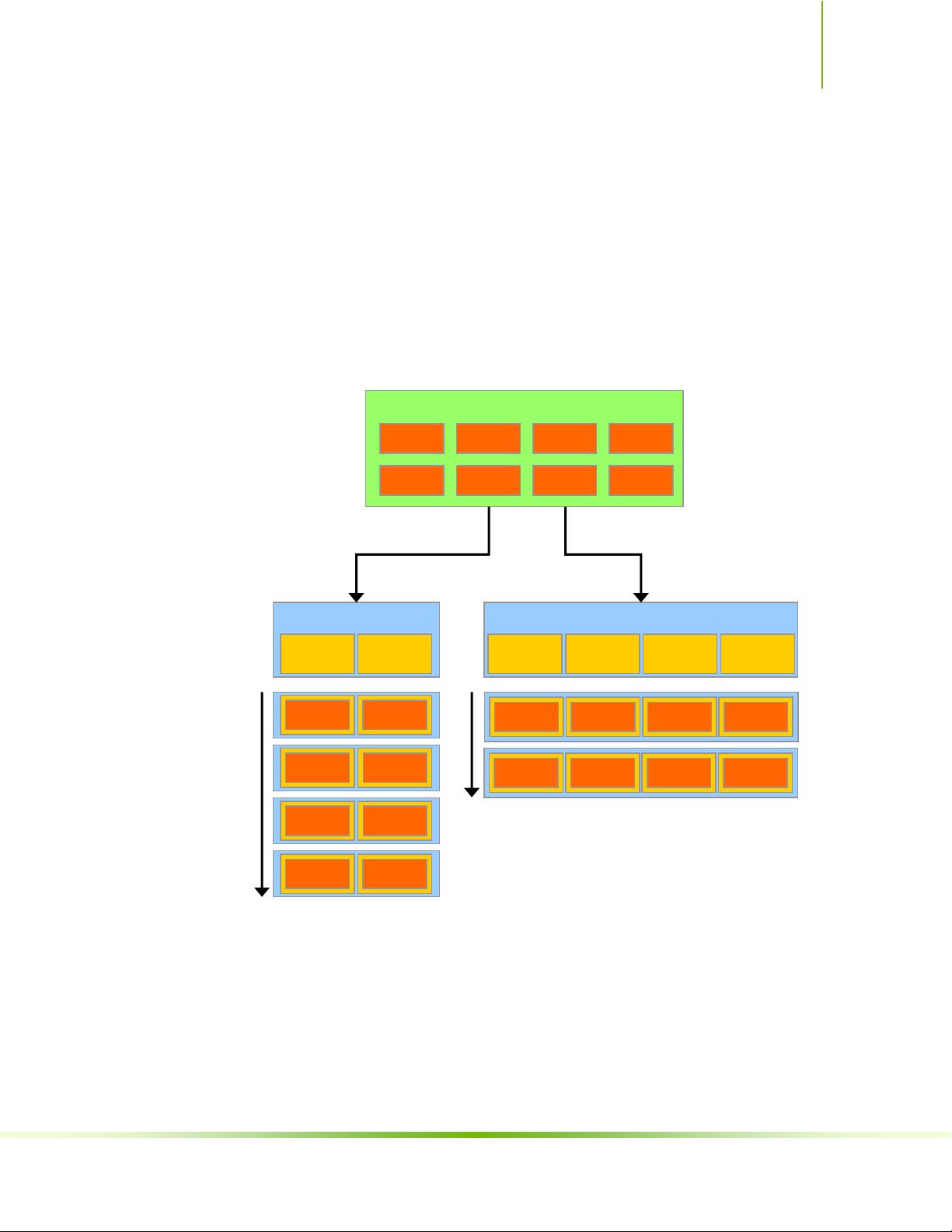
At its core are three key abstractions – a hierarchy of thread groups, shared
memories, and barrier synchronization – that are simply exposed to the programmer
as a minimal set of language extensions.
These abstractions provide fine-grained data parallelism and thread parallelism,
nested within coarse-grained data parallelism and task parallelism. They guide the
programmer to partition the problem into coarse sub-problems that can be solved
independently in parallel by blocks of threads, and each sub-problem into finer
pieces that can be solved cooperatively in parallel by all threads within the block.


剩余172页未读,继续阅读
2020-05-20 上传
2019-03-29 上传
2015-12-23 上传
2012-01-06 上传
2018-03-28 上传
2012-03-20 上传
2015-11-16 上传
2015-11-25 上传
2011-05-24 上传

txp914
- 粉丝: 22
- 资源: 700
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fizmez Web Server-开源
- jdk-8u271-linux-x64.zip
- c代码-这是一个输出0-50z之间所有能被3整除的的程序。
- movie-inc:影片制作数据库中的挑战奖的制作,预告片制作和制作,以及在影片库中编写的API
- matlab归零码功率谱源码-Genesis-1.3-Version4:随时间变化的3D代码可模拟自由电子激光器的放大过程
- acnh-critter-calendar:生成可以在岛上捕获的生物的列表
- video-layout2.zip
- Filter IE History-开源
- BooksStoreExcercise
- mysql代码-单表查询,多表查询
- 模拟电路-答案.zip-综合文档
- SD_HTMLRegPage
- mysql5.7安装软件及教程含主从配置.zip
- Fast Login Script-开源
- ShaggyShooters
- rock_paper_scissors:石头剪刀布游戏
