YOLO-World:开启实时开放词汇对象检测新时代
版权申诉
"YOLO-World:实时开放词汇对象检测,通过视觉语言建模和大规模数据集预训练增强YOLO的开放词汇检测能力,提出可重新参数化的视觉-语言路径聚合网络(RepVL-PAN)和区域-文本对比损失,实现高效率、高准确性的对象检测。"
YOLO-World 是针对 You Only Look Once (YOLO) 系列目标检测器的扩展和优化,旨在解决其在处理开放场景时受限于预定义和训练对象类别的问题。YOLO 系列检测器以其高效的实时性能而著名,但它们对于新出现或未经过训练的物体类别往往表现不佳。YOLO-World 通过引入视觉语言建模和大规模数据集的预训练,增强了模型的开放词汇检测能力,使其能适应更广泛的环境和应用场景。
核心创新点在于 RepVL-PAN(可重新参数化的视觉-语言路径聚合网络),这是一个设计用于促进视觉和语言信息之间深度交互的网络结构。通过这种交互,YOLO-World 可以理解和识别更多未在训练集中出现的物体类别,实现零样本(zero-shot)检测,即在没有特定类别实例的情况下也能检测到这些类别。这极大地扩展了模型的泛化能力和实用性。
同时,YOLO-World 引入了区域-文本对比损失(region-text contrastive loss),这种损失函数有助于模型更好地匹配图像区域与相应的文本描述,从而提高检测精度。通过这种方式,模型能够学习到更丰富的语义信息,增强对不同物体的识别能力。
在实验中,YOLO-World 在具有挑战性的 LVIS 数据集上展示了优越的性能。它在 NVIDIA V100 显卡上以 52.0 帧每秒(FPS)的速度实现了 35.4 AP(平均精度),在保持高效的同时,精度也超越了许多现有的先进方法。此外,经过微调后的 YOLO-World 在多个下游任务如目标检测和开放词汇实例分割中也表现出色,进一步证明了其在复杂场景下的适应性和实用性。
YOLO-World 的这些进步对于推动实时开放词汇对象检测的发展具有重要意义,尤其是在自动驾驶、无人机监控、智能安防等领域,需要模型能够处理未知和多变的环境条件。代码和模型已公开,这将有利于研究者和开发者进一步探索和利用这一技术,推动目标检测技术的边界。
Detector
Text Encoder
(a) Traditional Object Detector (b) Preivous Open-Vocabulary Detector (c) YOLO-World
Object Detector
Fixed
Vocabulary
Text
Encoder
Large Detector
Text
Encoder
Lightweight Detector
Offline
Vocabulary
User User
Online
Vocabulary
Re-parameterize
User
Train-only
Figure 2. Comparison with Detection Paradigms. (a) Traditional Object Detector: These object detectors can only detect objects
within the fixed vocabulary pre-defined by the training datasets, e.g., 80 categories of COCO dataset [26]. The fixed vocabulary limits the
extension for open scenes. (b) Previous Open-Vocabulary Detectors: Previous methods tend to develop large and heavy detectors for
open-vocabulary detection which intuitively have strong capacity. In addition, these detectors simultaneously encode images and texts as
input for prediction, which is time-consuming for practical applications. (c) YOLO-World: We demonstrate the strong open-vocabulary
performance of lightweight detectors, e.g., YOLO detectors [20, 42], which is of great significance for real-world applications. Rather than
using online vocabulary, we present a prompt-then-detect paradigm for efficient inference, in which the user generates a series of prompts
according to the need and the prompts will be encoded into an offline vocabulary. Then it can be re-parameterized as the model weights
for deployment and further acceleration.
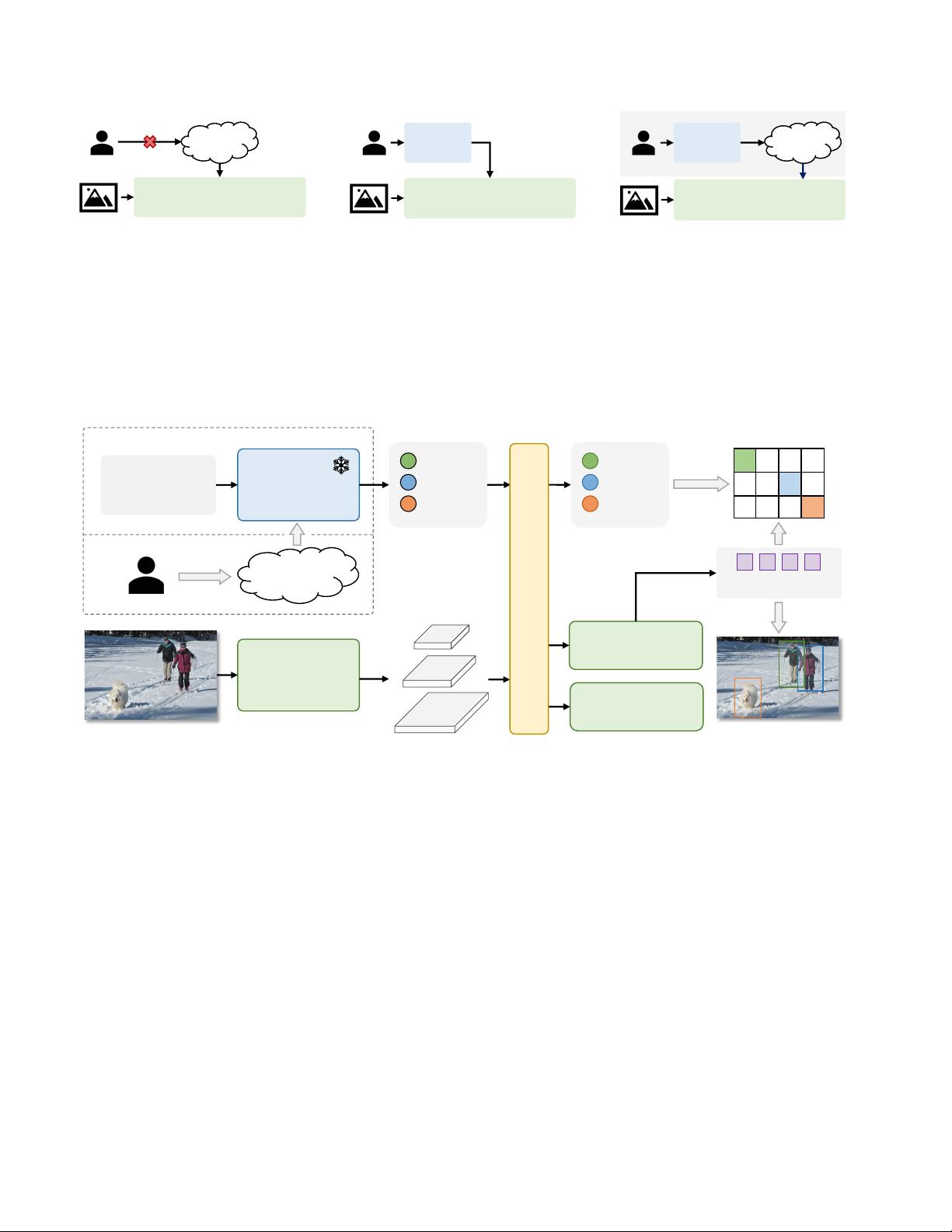
YOLO
Backbone
Text
Encoder
A man and a
woman are skiing
with a dog
caption, noun phrases, category…
User
Text Embeddings
Multi-scale Image Features
Text
Contrastive Head
Box Head
man
woman
dog
Vocabulary Embeddings
man
woman
dog
User’s
Vocabulary
Dog
Image-aware Embeddings
Multi-scale
Image Features
Training: Online Vocabulary
Deployment: Offline Vocabulary
Vision-Language PAN
Object Embeddings
Region-Text Matching
Input Image
Extract Nouns
Figure 3. Overall Architecture of YOLO-World. Compared to traditional YOLO detectors, YOLO-World as an open-vocabulary detector
adopts text as input. The Text Encoder first encodes the input text input text embeddings. Then the Image Encoder encodes the input image
into multi-scale image features and the proposed RepVL-PAN exploits the multi-level cross-modality fusion for both image and text features.
Finally, YOLO-World predicts the regressed bounding boxes and the object embeddings for matching the categories or nouns that appeared
in the input text.
by vision-language pre-training [19, 39], recent works [8,
22, 53, 62, 63] formulate open-vocabulary object detection
as image-text matching and exploit large-scale image-text
data to increase the training vocabulary at scale. OWL-
ViTs [35, 36] fine-tune the simple vision transformers [7]
with detection and grounding datasets and build the sim-
ple open-vocabulary detectors with promising performance.
GLIP [24] presents a pre-training framework for open-
vocabulary detection based on phrase grounding and eval-
uates in a zero-shot setting. Grounding DINO [30] incor-
porates the grounded pre-training [24] into detection trans-
formers [60] with cross-modality fusions. Several meth-
ods [25, 56, 57, 59] unify detection datasets and image-text
datasets through region-text matching and pre-train detec-
tors with large-scale image-text pairs, achieving promising
performance and generalization. However, these methods
often use heavy detectors like ATSS [61] or DINO [60]
with Swin-L [32] as a backbone, leading to high com-
putational demands and deployment challenges. In con-
trast, we present YOLO-World, aiming for efficient open-
vocabulary object detection with real-time inference and
easier downstream application deployment. Differing from
ZSD-YOLO [54], which also explores open-vocabulary de-
tection [58] with YOLO through language model align-
ment, YOLO-World introduces a novel YOLO framework
with an effective pre-training strategy, enhancing open-
3
剩余14页未读,继续阅读
2024-05-30 上传
2021-05-08 上传
2019-04-11 上传
2024-08-19 上传
点击了解资源详情
2024-10-27 上传
2024-10-27 上传
2024-10-27 上传


人工智能_SYBH
- 粉丝: 4w+
- 资源: 222
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
