Python ID3算法实现决策树分类详解
55 浏览量
更新于2024-09-01
收藏 95KB PDF 举报
"python实现决策树分类"
在Python中实现决策树分类主要涉及到机器学习中的决策树算法,这里具体是ID3算法。ID3(Iterative Dichotomiser 3)是一种用于分类和回归的决策树算法,由Ross Quinlan在1986年提出。该算法基于信息熵和信息增益来选择最佳特征进行分裂。
决策树的工作原理是通过一系列规则创建一个树形结构,每个内部节点代表一个特征,每个分支代表一个特征值,而每个叶节点则对应一个类别决策。在训练阶段,算法根据信息增益选择最优特征进行划分,直到满足停止条件(如达到预设的树深度、所有样本属于同一类别或没有更多特征可选)。
在提供的代码中,首先引入了numpy和pandas库处理数据,以及math库计算对数,operator库用于操作符比较。`load_data()`函数用于加载数据,数据集包含特征和对应的类别标签。在这个例子中,特征有四个:年龄(age)、收入(input)、是否学生(student)和生活品质(level),类别标签是是否购买('yes'或'no')。
代码中的关键步骤包括:
1. 计算信息熵(Entropy):信息熵是衡量数据纯度的一个指标,用于评估当前节点的不确定性。熵越大,不确定性越高,节点纯度越低。
2. 计算信息增益(Information Gain):信息增益是通过选择某一特征进行划分后,子集的熵相对于原集合熵的减少量。选取信息增益最大的特征作为分裂依据。
3. 分裂节点:根据计算出的最佳特征和对应的值,将数据集划分为多个子集,并递归地在子集上重复上述过程。
4. 停止条件:当所有样本属于同一类别或者没有更多的特征可选时,停止分裂,生成叶节点。
这个ID3算法的实现没有展示完整的代码,但可以预见后续的步骤会包括计算信息熵和信息增益,以及根据信息增益选择最佳特征进行分裂的逻辑。在实际应用中,还需要考虑处理缺失值、连续值和过拟合等问题。另外,Python中常用的机器学习库如scikit-learn提供了封装好的决策树算法,例如`sklearn.tree.DecisionTreeClassifier`,可以更方便地进行决策树模型的训练和预测。
python实现决策树分类实现决策树分类
主要为大家详细介绍了python实现决策树分类的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
上一篇博客主要介绍了决策树的原理,这篇主要介绍他的实现,代码环境python 3.4,实现的是ID3算法,首先为了后面matplotlib的绘图方便,我把原
来的中文数据集变成了英文。
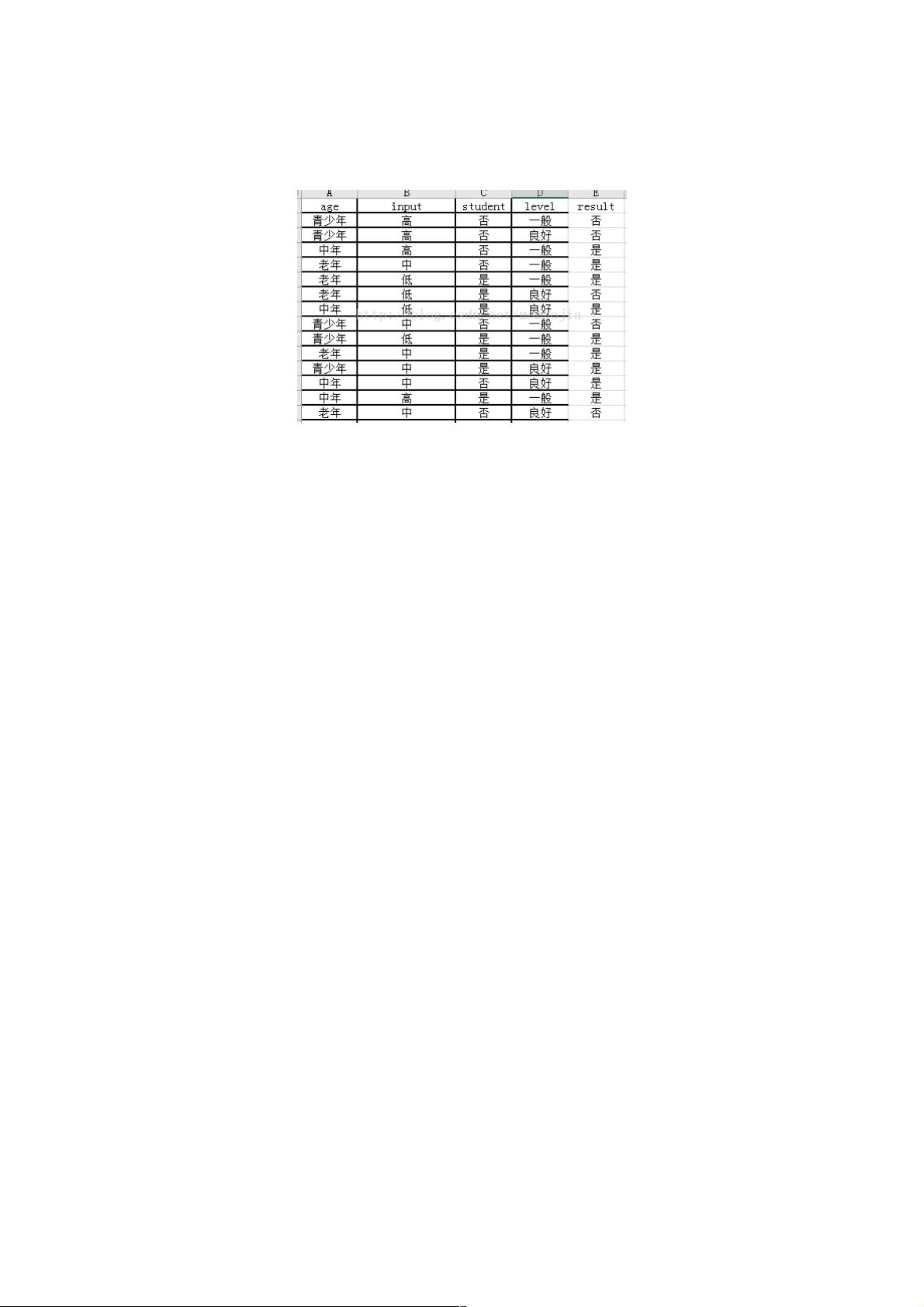
原始数据集:
变化后的数据集在程序代码中体现,这就不截图了
构建决策树的代码如下:
#coding :utf-8
'''
2017.6.25 author :Erin
function: "decesion tree" ID3
'''
import numpy as np
import pandas as pd
from math import log
import operator
def load_data():
#data=np.array(data)
data=[['teenager' ,'high', 'no' ,'same', 'no'],
['teenager', 'high', 'no', 'good', 'no'],
['middle_aged' ,'high', 'no', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'same', 'yes'],
['old_aged', 'low', 'yes', 'same' ,'yes'],
['old_aged', 'low', 'yes', 'good', 'no'],
['middle_aged', 'low' ,'yes' ,'good', 'yes'],
['teenager' ,'middle' ,'no', 'same', 'no'],
['teenager', 'low' ,'yes' ,'same', 'yes'],
['old_aged' ,'middle', 'yes', 'same', 'yes'],
['teenager' ,'middle', 'yes', 'good', 'yes'],
['middle_aged' ,'middle', 'no', 'good', 'yes'],
['middle_aged', 'high', 'yes', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'good' ,'no']]
features=['age','input','student','level']
return data,features
def cal_entropy(dataSet):
'''
输入data ,表示带最后标签列的数据集
计算给定数据集总的信息熵
{'是': 9, '否': 5}
0.9402859586706309
'''
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
label = featVec[-1]
if label not in labelCounts.keys():
labelCounts[label] = 0
labelCounts[label] += 1
entropy = 0.0
for key in labelCounts.keys():
p_i = float(labelCounts[key]/numEntries)
entropy -= p_i * log(p_i,2)#log(x,10)表示以10 为底的对数
return entropy
def split_data(data,feature_index,value):
'''
划分数据集
feature_index:用于划分特征的列数,例如“年龄”
value:划分后的属性值:例如“青少年”
'''
data_split=[]#划分后的数据集
for feature in data:
if feature[feature_index]==value:
reFeature=feature[:feature_index]
reFeature.extend(feature[feature_index+1:])
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-09-20 上传
153 浏览量
2021-01-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38656463
- 粉丝: 3
- 资源: 904
 我的内容管理
展开
我的内容管理
展开







