HDFS读写数据流程详解与分布式环境下的字节流操作
版权申诉
145 浏览量
更新于2024-07-17
收藏 2.04MB PPT 举报
HDFS(Hadoop Distributed File System)是一种分布式文件系统,专为大数据处理而设计,它在大规模集群环境下提供高吞吐量的数据存储和访问。本资源聚焦于HDFS的读写数据流程分析,特别是针对客户端如何通过DFSInputStream与HDFS进行交互的深入理解。
首先,客户端在与HDFS通信时,会通过DFSOutputStream创建一个新的文件流。这个过程涉及创建一个DFSOutputStream实例,用于向HDFS写入数据。DFSOutputStream的创建会初始化一系列数据结构和连接,以便后续的I/O操作。
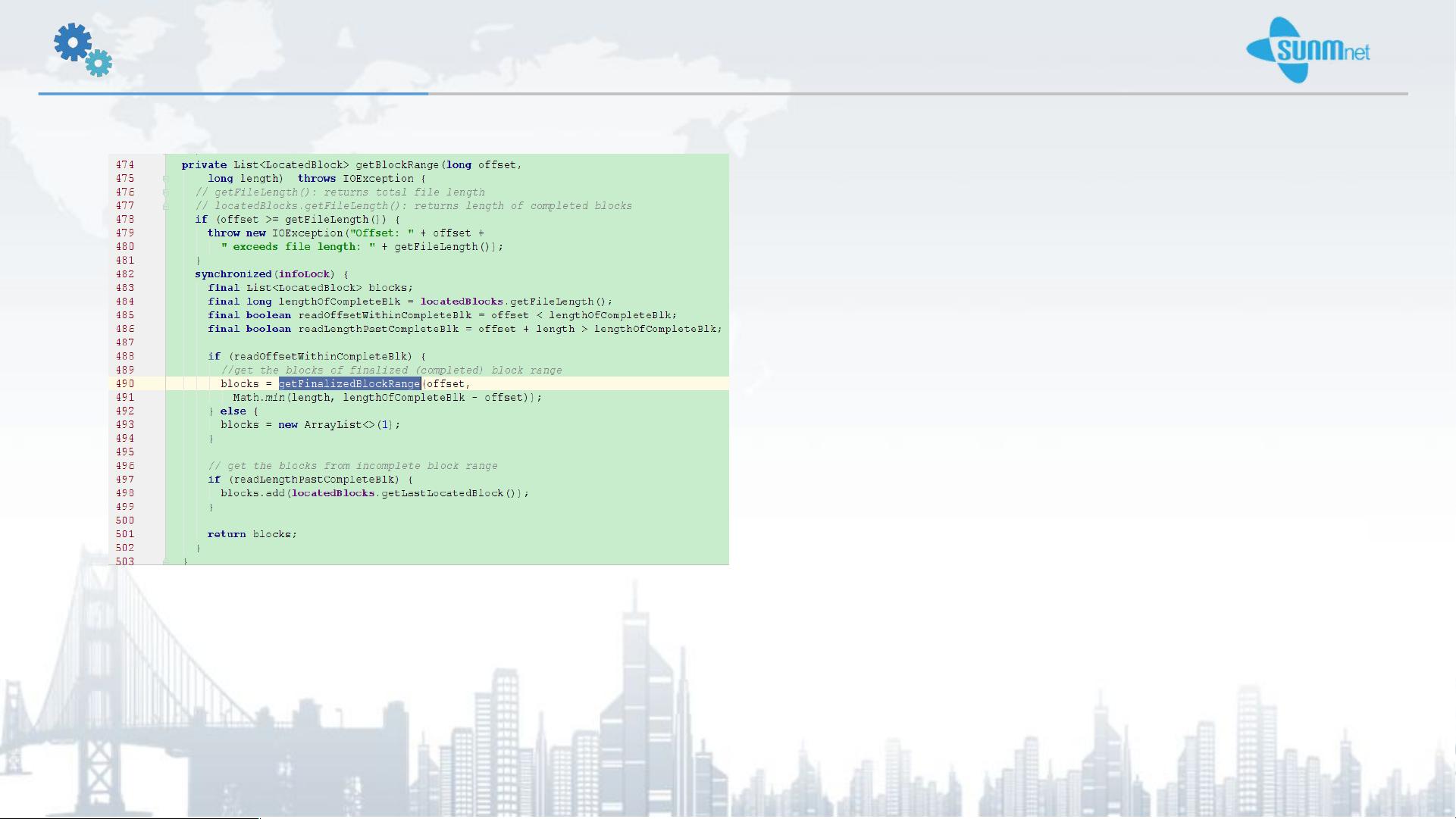
当客户端需要读取数据时,它会使用DFSInputStream的read方法,该方法的核心是read(long position, byte[] buffer, int offset, int length)。这个方法的工作原理相对直观:首先,它会对输入流的状态进行检查,确保流未被关闭,并且客户端与HDFS的连接有效。接着,它会根据提供的位置和所需读取的字节数计算出需要读取的块范围,这一步通过getBlockRange方法实现。
getBlockRange方法考虑了文件的实际长度,包括已知的完整块和可能存在的未完成的最后一个块。完整块的长度可以通过调用getFileLength()获取,而实际长度则包括最后一个可能不完整的块。如果有必要,getFinalizedBlockRange()方法会负责获取并添加这个最后一块。
read方法中,有两种获取字节的方法:hedgedFetchBlockByteRange和fetchBlockByteRange。hedgedFetchBlockByteRange使用Future异步执行,提高了并发性和性能,而fetchBlockByteRange则是同步获取,适合于简单的场景。这两种方法共同确保了数据块的高效读取。
在获取到块信息和字节范围后,DFSInputStream会逐个读取这些块,并将数据缓存到指定的buffer中。这一步是整个读取流程的关键部分,它涉及到了HDFS的数据分片和副本策略,确保了即使在分布式环境中,数据也能可靠地被读取和处理。
HDFS读写数据流程涉及客户端与服务器之间的连接管理、数据块定位、异步和同步读取策略以及数据缓存,这些都是为了在大规模分布式环境中提供高性能和容错性。理解这些细节对于开发和优化基于HDFS的应用至关重要。
DFSInputStream.read
好啦 , 先看看怎样获取块信息和字节范围 , 要进入 g
etBlockRange 方法里详细看看 :
这里讲述了两个 getFileLength() 的区别 : 前者是这
个文件的长度 , 要加上” lastBlockBeingWrittenLength” 这
个变量 ( 上一次实验最后得到的那个最后块的长度 ), 而
后者就是完整块的长度 . 这里的逻辑就是先加入已经完
整快到块列表 , 最后如果有需求就加上最后一块到块列
表 , 主要是功能在 490 行的 getFinalizedBlockRange(), 里
面功能有个循环用 fetchBlockAt(curOff, remaining, true)
方法来获取每一个块的信息 .
剩余26页未读,继续阅读
139 浏览量
2022-11-21 上传
2022-07-08 上传
397 浏览量
2022-06-21 上传
2021-10-02 上传
103 浏览量
251 浏览量
109 浏览量

制冷技术咨询与服务
- 粉丝: 4112
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决Android应用混淆错误:Can't process class的方法
- 零基础入门AppInventor开发Android应用
- 掌握简易正则表达式,轻松编程 — SimpleRegex介绍
- C语言字符串行查找方法解析
- 键盘模拟与自动化控制技术 - KeyCode应用
- Get Arrays Udemy课程支持门户网站:Angular、Spring和JWT实战
- 《愤怒的小鸟》第二阶段:类继承与图像处理深度解析
- OpenGL下模拟泡泡物理动态的实现方法
- 解决VC++编译错误:如何正确包含bios头文件
- 打造高效jQuery插件:jQuery.nice助您一臂之力
- R语言自定义组学分析函数库的介绍
- 实现高效无刷新聊天室的ASP.NET+AJAX源码解析
- H5游戏开发实例:Web2.0打地鼠与迷宫游戏
- MFC C++ 数字图像处理编程技术详解
- 纯OC与纯Swift实现的手势滑动返回教程
- GwasQcPipeline测试数据集:伪造样本与Illumina测试案例
