HBase架构详解:核心模块、功能与Hadoop集成
109 浏览量
更新于2024-08-27
收藏 338KB PDF 举报
HBase是一个建立在Hadoop之上,以NoSQL非关系型数据库模型为基础的列式存储系统。它与Hadoop生态系统紧密集成,利用HDFS作为底层存储支持,提供可靠的数据存储,而MapReduce则为其高性能计算提供了保障。
HBase的核心功能模块主要包括:
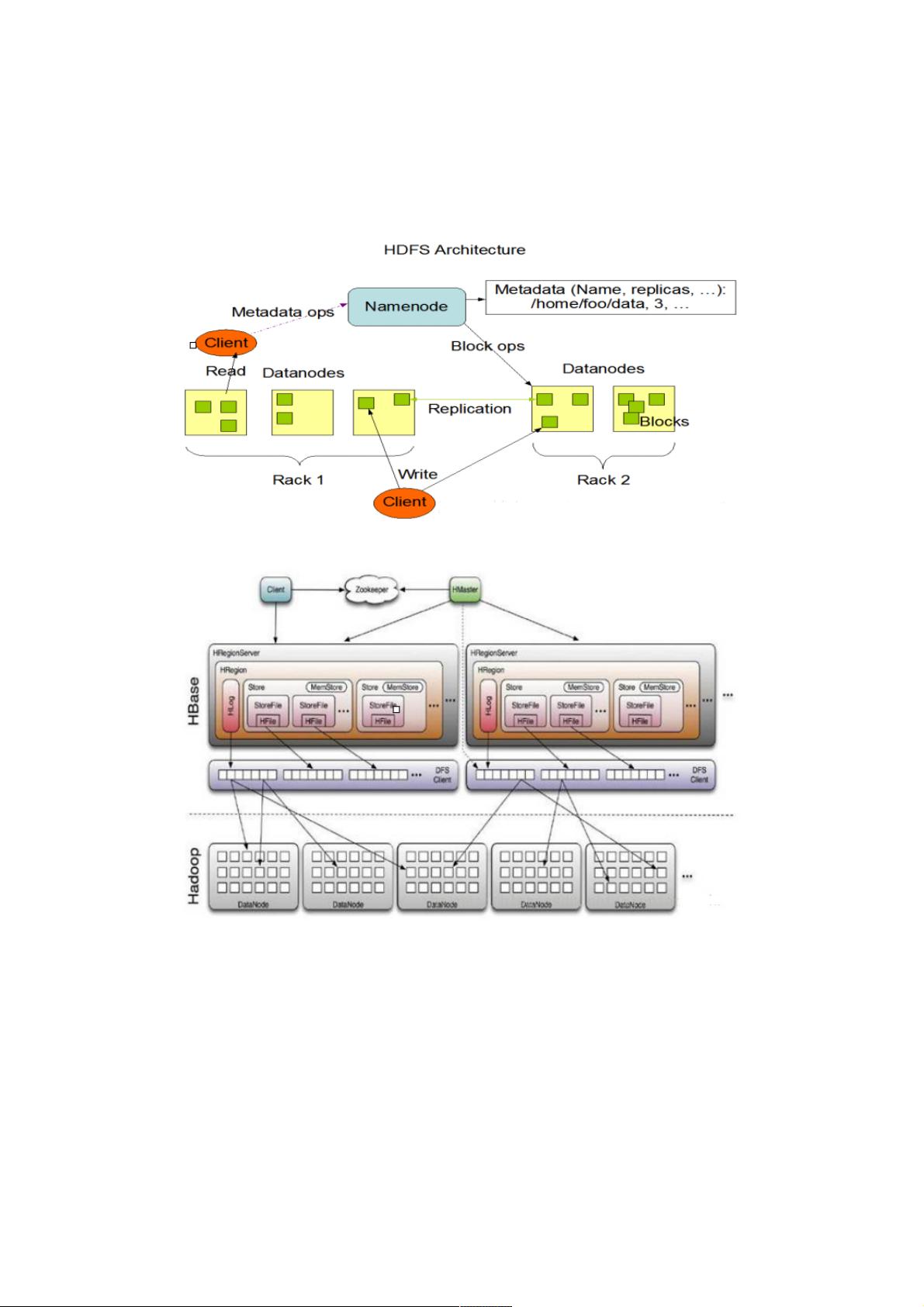
1. **客户端(Client)**: Client是HBase的用户接口,它通过Remote Procedure Call (RPC)协议与HBase的管理和数据处理组件进行交互。客户端处理大部分用户操作,包括管理类的操作(如创建、删除表),以及数据读写请求。客户端支持多种访问方式,如Java API、HBase Shell命令行工具和Avro等,以满足不同场景的需求。
2. **Zookeeper**: Zookeeper是HBase不可或缺的一部分,由雅虎公司开发,作为分布式协调服务。它负责维护HBase的元数据一致性,例如存储表的结构信息、监控RegionServer状态、协调Region分配和HMaster选举等。Zookeeper确保在分布式环境中的数据同步和可靠性。
3. **HMaster**: HMaster是集群的管理器,主要职责包括用户表操作的权限管理、RegionServer的负载均衡、新Region的分配、故障恢复和Region迁移等。它是集群的中心控制节点,通过Zookeeper实现协调和监控。
4. **HRegionServer**: HRegionServer是HBase的执行引擎,负责处理实际的数据读写请求。每个HRegionServer运行多个HRegion实例,每个HRegion对应表的一个逻辑分区,由多个HStore负责存储特定ColumnFamily的数据。HStore进一步细分为MemStore(内存缓存)和StoreFile(持久化存储),前者用于暂存用户写入数据,满后会flush到StoreFile,形成最终的存储结构。
HBase的设计模式允许它处理大规模的数据,并且能够高效地进行随机读写,特别适合于需要快速读取和处理海量数据的场景,比如日志分析、社交网络、在线广告和游戏等。理解并掌握这些核心模块对于使用HBase构建和优化大数据应用至关重要。
HBase核心模块介绍及基本概念介绍(核心模块介绍及基本概念介绍(HBase模式设计)模式设计)
一、HBase与Hadoop之间的关系
Hadoop框架中的HDFS分布式文件系统为HBase提供了可靠的底层存储支持。
Hadoop框架中的MapReduce为HBase提供了高性能的计算能力。
二、HBase的核心功能模块
1.Client
Client是整个HBase系统的入口
客户端使用RPC协议与HMaster和RegionServer进行通信
对于管理类(表的增删)操作,Client与HMaster进行RPC通信
对于数据读写类操作Client与RegionServer进行RPC交互
客户端可以是多个,也可以以不同形式访问,如Java接口、HBase shell命令行、Avro等
2.Zookeeper
Zookeeper负责消息协调通信-------由雅虎公司开发出的
Zookeeper是一个高可用的分布式数据管理与系统协调框架。
Zookeeper底层基于Paxos算法的实现,使的该框架保证了分布式环境中数据的一致性。
下载后可阅读完整内容,剩余4页未读,立即下载
2022-02-02 上传
2012-08-02 上传
2018-06-18 上传
2023-05-23 上传
2023-06-08 上传
2023-05-25 上传
2024-06-13 上传
2023-06-03 上传
2023-10-27 上传

weixin_38575536
- 粉丝: 3
- 资源: 926
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
