Apache Flink流处理详解:分布式数据流引擎与API介绍
需积分: 10 176 浏览量
更新于2024-07-15
收藏 19.93MB PDF 举报
"flink-1.7-中文文档.pdf"
Apache Flink是一个强大的开源大数据处理框架,专注于实时和批量数据处理。它提供了流数据流引擎,该引擎支持数据的高效分发、通信以及容错机制,确保在分布式环境中运行的稳定性。Flink不仅限于流处理,还构建了批处理功能,并且内建对迭代计算的支持,以及内存管理和程序优化,使其成为一种全面的数据处理解决方案。
在Flink的数据流编程模型中,用户可以通过DataStream API来定义数据处理任务。API提供了丰富的操作符,如map、filter、reduce等,用于转换和聚合数据。此外,Flink支持事件时间和水印的概念,用于处理乱序事件,保证数据处理的正确性。
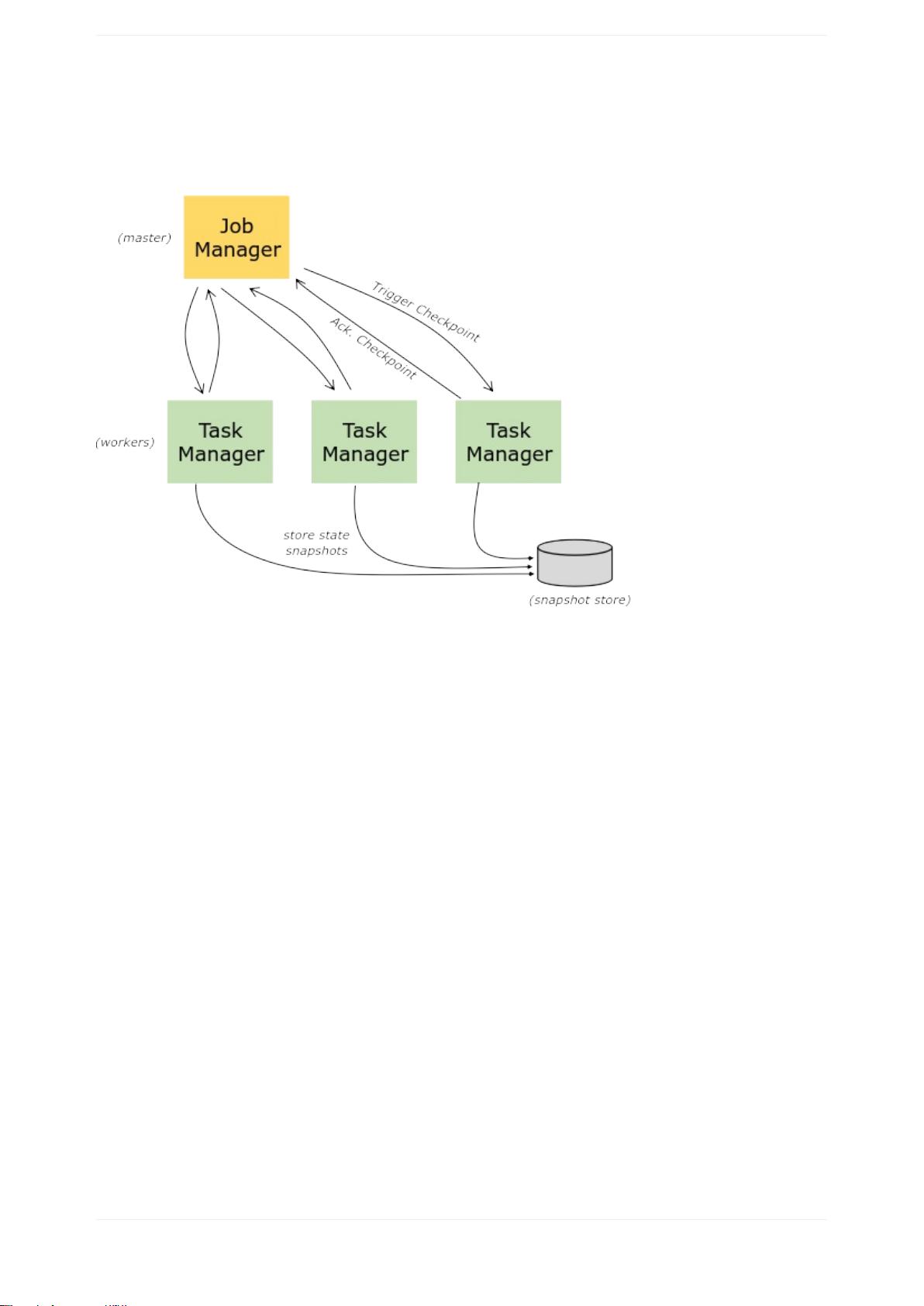
分布式运行时环境是Flink的核心组成部分,它包括数据分发、任务调度、故障恢复策略等。Flink通过检查点实现容错,保证在系统发生故障时能够恢复到一致状态。状态管理是另一个关键特性,允许程序保存中间结果并支持状态的持久化。Flink还引入了广播状态模式,使得某些状态可以被所有并行实例共享。
Flink的DataStream API提供了丰富的窗口操作,包括时间窗口、滑动窗口、会话窗口等,这些窗口可以用于处理时间相关的聚合操作。同时,Flink支持各种类型的连接操作,如内连接、外连接、全连接等。过程函数允许用户自定义低级操作,实现更复杂的逻辑。
在应用开发方面,Flink支持Java和Scala两种主要的编程语言,并提供了相应的项目模板。用户需要配置依赖关系,包括连接器和库,以便访问不同的数据源和输出。Flink还支持使用Java Lambda表达式简化代码编写。
对于外部数据访问,Flink提供了异步I/O机制,优化了数据读写性能。此外,Flink集成了多种数据连接器,如Apache Kafka、Apache Cassandra和亚马逊AWS Kinesis Streams,使得数据源和接收器的容错得到了保障。
总结起来,Apache Flink 1.7版本提供了强大的分布式流处理和批处理能力,具有高效的数据流编程模型、强大的容错机制和灵活的状态管理。通过其丰富的API和连接器,开发者可以轻松处理各种类型的数据处理任务,无论是实时流数据还是批量数据,都在Flink的掌控之中。
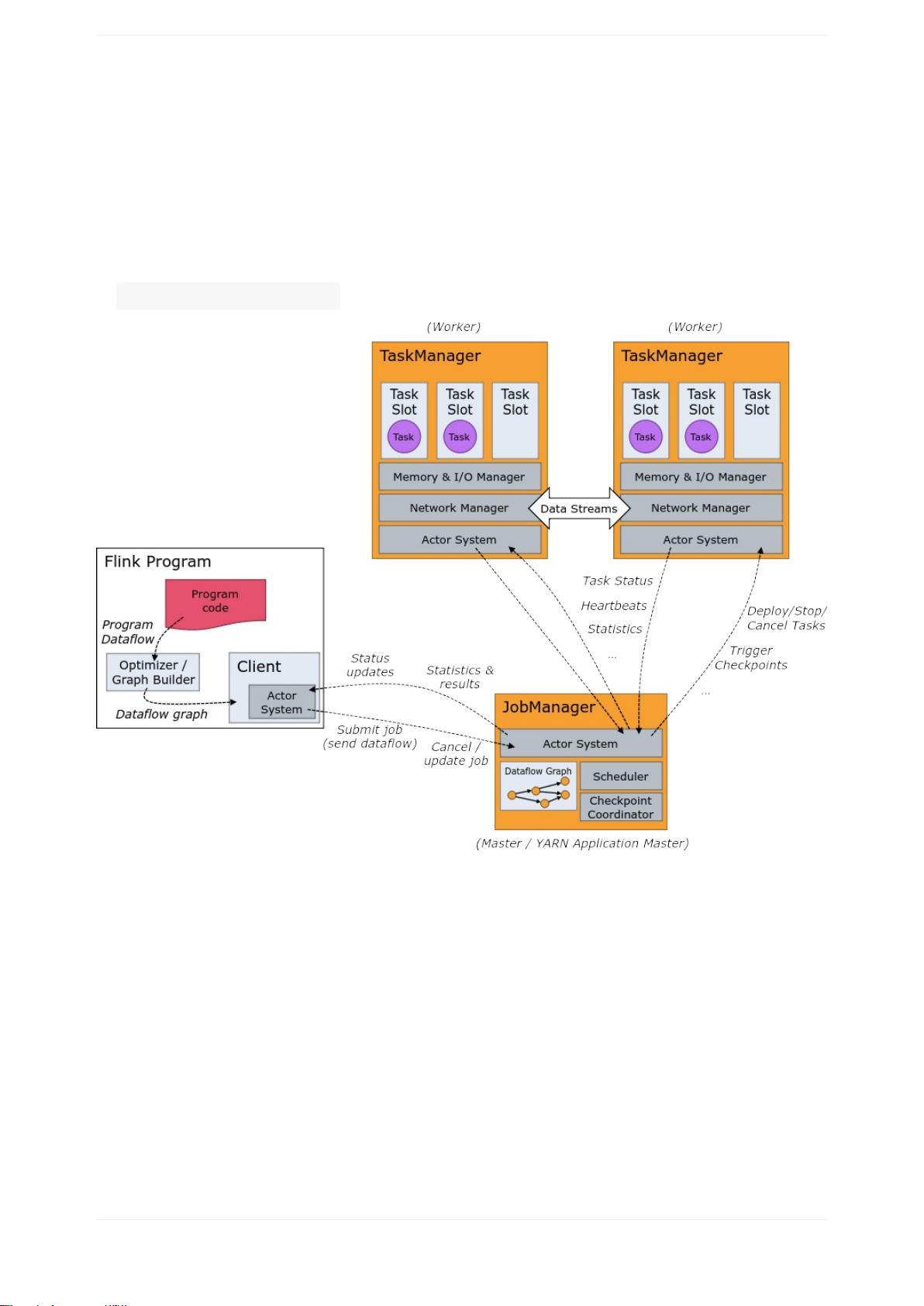
必须始终至少有一个TaskManager。
JobManagers和TaskManagers可以通过多种方式启动:作为独立集群直接在计算
机上,在容器中,或由YARN或Mesos等资源框架管理。TaskManagers连接到
JobManagers,宣布自己可用,并被分配工作。
该客户端是不运行时和程序执行的一部分,而是被用来准备和发送的数据流的
JobManager。之后,客户端可以断开连接或保持连接以接收进度报告。客户端既
可以作为触发执行的Java / Scala程序的一部分运行,也可以在命令行进程中运
行 ./bin/flink run ... 。
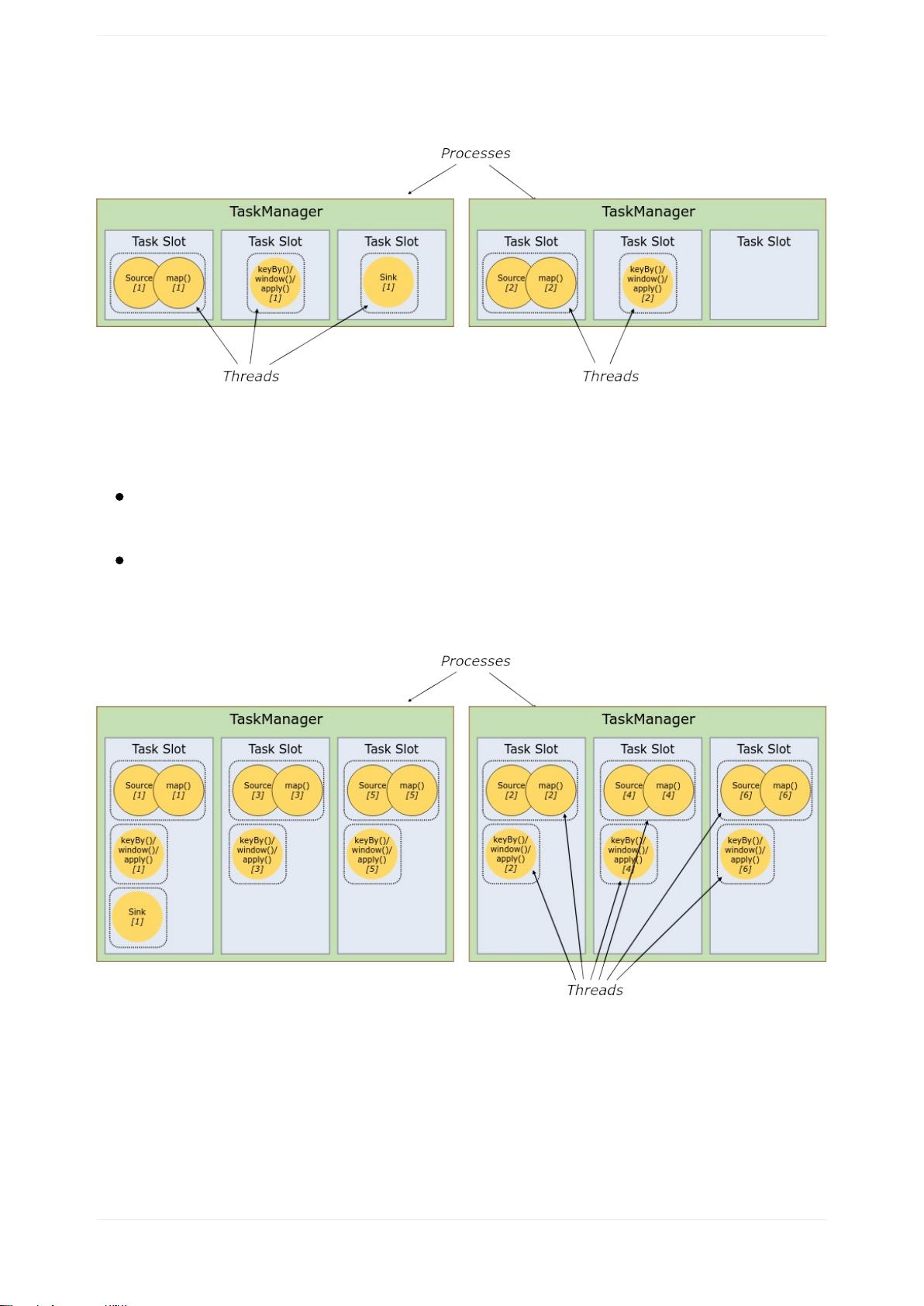
任务槽和资源
每个worker(TaskManager)都是一个JVM进程,可以在不同的线程中执行一个或
多个子任务。为了控制工人接受的任务数量,工人有所谓的任务槽(至少一个)。
每个任务槽代表TaskManager的固定资源子集。例如,具有三个插槽的
TaskManager将其1/3的托管内存专用于每个插槽。切换资源意味着子任务不会与来
自其他作业的子任务竞争托管内存,而是具有一定数量的保存托管内存。请注意,
此处不会发生CPU隔离; 当前插槽只分离任务的托管内存。
通过调整任务槽的数量,用户可以定义子任务如何相互隔离。每个TaskManager有
一个插槽意味着每个任务组在一个单独的JVM中运行(例如,可以在一个单独的容
器中启动)。拥有多个插槽意味着更多子任务共享同一个JVM。同一JVM中的任务
分布式运行时环境
16


剩余1168页未读,继续阅读
2018-11-07 上传
2019-11-05 上传
2019-06-26 上传
2021-06-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

heyirong2012
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
