分布式数据库架构解析
需积分: 9 24 浏览量
更新于2024-07-25
收藏 469KB PPT 举报
"分布式数据库资料提供了对分布式数据库架构的深入探讨,包括自顶向下和自底向上的设计方法,以及不同分布式数据库系统架构的选择。同时,提到了全局目录/词典的重要角色,并概述了参考模型作为系统结构划分的工具。"
分布式数据库是一个由多个物理位置的独立数据库组成,它们共同协作并表现为单个逻辑数据库。这种架构的设计目标是提高系统的可伸缩性、可用性和性能,同时保持数据的一致性和完整性。
1. **自顶向下设计**:
在自顶向下设计中,首先定义全局模式,即整个分布式数据库的完整数据结构。接着,这个全局模式被分解为局部模式,每个局部模式对应一个独立的数据库节点。分布透明性是关键,意味着用户无需知道数据在哪个节点上,只需按照全局模式进行操作。这一设计方法强调了逻辑独立性,简化了应用开发。
2. **自底向上设计**:
相反,自底向上设计是从现有的独立数据库开始,根据需求将它们集成。这种方法更多地考虑了现有的硬件和软件基础设施,可能更适用于已经建立的系统。它通常涉及数据复制、数据分区和数据分片策略,以实现负载均衡和容错能力。
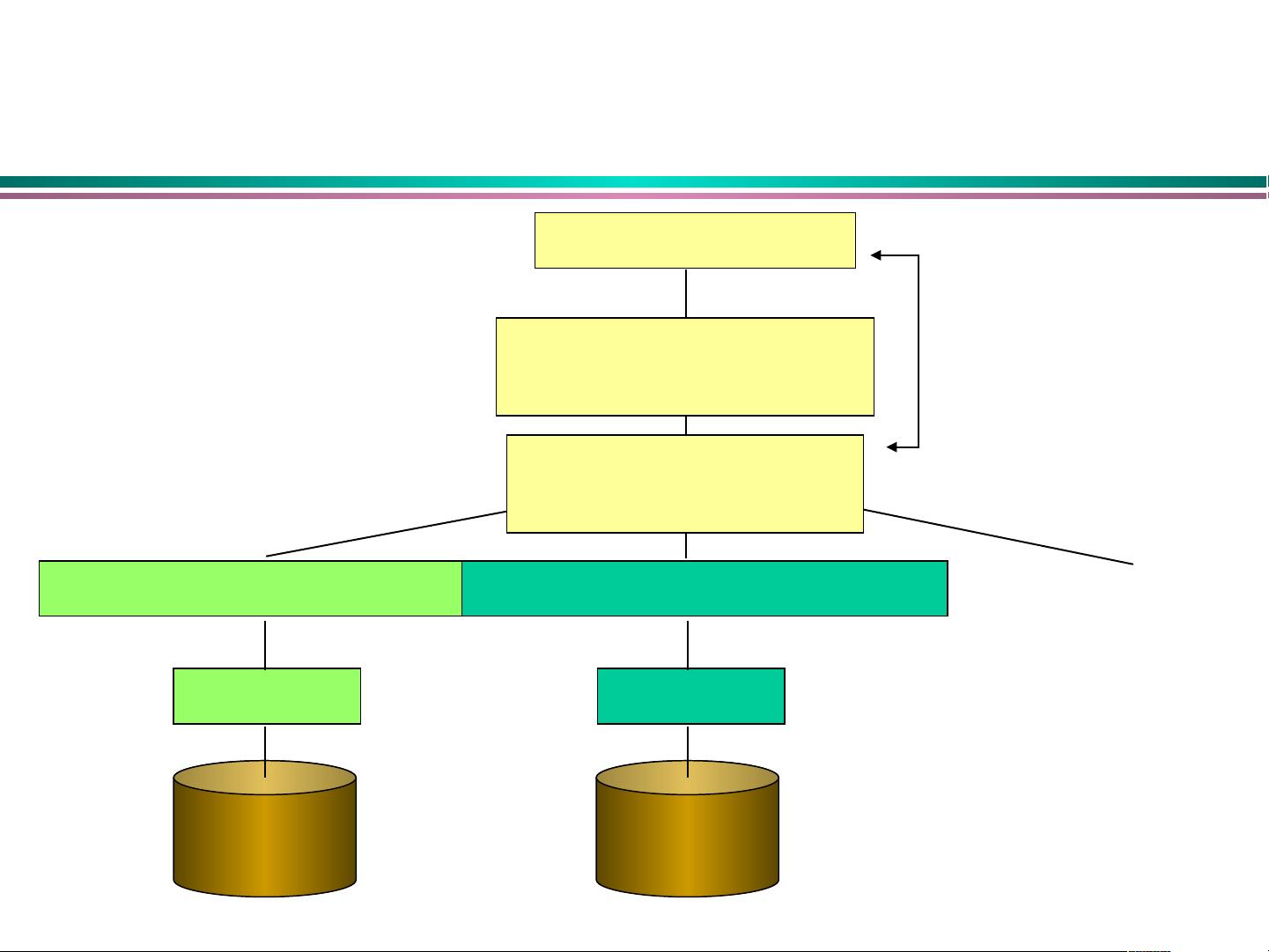
3. **分布式数据库系统架构**:
- 客户/服务器架构:在这种架构中,客户端应用程序通过网络向服务器发送请求,服务器处理请求并返回结果。这通常用于集中式访问控制和数据管理。
- 对等对等(Peer-to-Peer)分布式数据库:所有节点地位平等,可以直接与其他节点通信,降低了对中心节点的依赖,提高了系统的弹性和扩展性。
- 多数据库架构:多个独立的数据库在需要时进行交互,可能通过复制或消息传递来协调数据。
4. **全局目录/词典**:
全局目录或词典是分布式数据库中的一个重要组件,它存储了关于所有局部数据库的信息,包括数据的位置、分布和元数据。这对于查询优化和数据定位至关重要。
5. **参考模型**:
参考模型是系统设计的基础,它将标准工作划分为可管理的部分,并展示了这些部分之间的关系。组件基础的方法侧重于定义系统组件及其相互关系,适合系统设计和实现;而功能基础的方法则关注用户类别和系统提供的功能,有助于满足不同用户群体的需求。
分布式数据库的设计和实施涉及到复杂的数据分布策略、事务处理、并发控制和恢复机制,这些都需要仔细考虑以确保系统的正确性和高效性。此外,还要注意安全性、容错能力和网络延迟等问题。对于开发者和管理员来说,理解和掌握分布式数据库的基本原理和技术是至关重要的。

10
External View (外部模式 ) –
Example 2
CREAT VIEW PAYROLL(ENO, ENAME, SAL)
AS SELECT EMP.ENO, EMP.ENAME, PAY.SAL
FROM EMP, PAY
WHERE EMP.TITLE = PAY.TITLE
Create a Payroll view from relations EMP and PAY
剩余55页未读,继续阅读
2021-10-17 上传
2013-01-16 上传
2022-06-16 上传
2022-06-05 上传
2022-06-05 上传
2022-06-04 上传
2010-12-01 上传

thekingtheking
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- cumpositiontyp,c语言聊天软件源码详解,c语言
- 1click Paintbrush-crx插件
- private_party
- tiffread2.m:读取 tiff 文件,包括带有信息的堆栈-matlab开发
- yipay:易支付
- pdi-ce-9.5.0.1-261.zip
- bond-cni:Bond-cni用于实现云编排中的故障转移和网络的高可用性
- 软硬
- 猫和老鼠主题的简单网页(HTML+CSS)
- ASO –适用于初学者的应用商店优化
- 940383,c语言的源码不能跨平台,c语言
- 互联网IT科技互联网站模板
- node_mysql_retrogaming:一个带有NodeJS,Express和MySQL的附带项目
- project_code_print:打印源代码到word文档里面,方便纸质阅读。简易树形图,压缩代码行间距,尽量节省纸张
- 社交媒体策略:在获得客户的Facebook和Twitter帐户访问权限并从其帖子下载参与度指标后,为其创建了社交媒体策略。 步骤包括数据清理和新变量的特征工程,将每个帖子分类为不同的主题,创建视觉效果,自然语言处理和回归分析,所有这些操作均使用Python完成
- MinecraftChat:基于Minecraft的网络聊天客户端
