使用matplotlib探索鸢尾花数据集:特征可视化与分析
170 浏览量
更新于2024-09-01
1
收藏 177KB PDF 举报
本篇文章主要介绍了如何使用Python的matplotlib库对经典的鸢尾花数据集(Iris Dataset)进行数据分析。Iris数据集由150个样本组成,分为三个类别:Setosa、Versicolor和Virginica,每个样本有四个特征:花瓣长度、花瓣宽度、萼片长度和萼片宽度。这些特征可用于预测鸢尾花的种类。
首先,文章提到了所需的关键Python库,包括matplotlib用于绘制图表,pandas用于数据处理和DataFrame结构,sklearn用于加载预置的Iris数据集,以及seaborn用于更高级的数据可视化。由于作者并未在本地存储数据集,因此选择从sklearn内置的示例数据中导入。
接下来的步骤是导入数据并将其转化为pandas DataFrame形式,这样可以方便地进行各种数据操作。通过`load_iris()`函数从sklearn获取Iris数据,然后创建一个字典映射特征名称到数据数组,最后将这些数据整合到DataFrame中,并添加一个'type'列来标识鸢尾花的类别。
作者通过`print(iris)`展示了完整的150行数据集,而`print(iris.head())`则展示了数据集的前五行,以及数据的初步统计信息,如类别标签(0, 1, 2分别对应Setosa, Versicolor, Virginica)。
通过这个数据集,读者可以进一步探索数据分布、各特征之间的关系,或者使用matplotlib进行单变量、双变量或多变量的可视化,例如直方图、散点图、箱线图等,以帮助理解鸢尾花数据集的特性。此外,seaborn库提供了更高级的统计图形,可以用来展示数据的复杂模式和潜在的规律。
总结来说,本文将引导读者使用matplotlib和相关库对Iris数据集进行基础分析,帮助他们熟悉数据处理和可视化流程,这对于学习和理解机器学习中的特征工程和数据预处理至关重要。
基于基于matplotlib对对iris数据集进行数据分析数据集进行数据分析
iris介绍
iris数据集也称鸢尾花数据集。包括150个数据样本,分为三类,每类五十个数据,每个数据具有四个属性,可通过四个属性预测鸢尾
花属于哪一类。
用到的python库
matplotlib、pandas、sklearn、seaborn
/这里因为我没有下载这里因为我没有下载iris数据集,所以从数据集,所以从sklearn里面导入,如果有数据集则用里面导入,如果有数据集则用pandas.read_csv打开即可。打开即可。/
有了数据集以后就直接作图等操作就好了。 let‘s go!
导入数据集,看看数据集长啥样子。
把数据集转换为pandas的DataFrame类型便于操作(类似与二维表)
import pandas as pd
from sklearn.datasets import load_iris
#因为没有iris数据集,只好从sklearn里面导入
import matplotlib.pyplot as plt
import seaborn as sns
iris=load_iris()
feature_names=['sepal length', 'sepal width', 'petal length', 'petal width'] #利用字典把数据转换为dataframe类型
#DataFrame指一种类似与excel的二维表的框架
iris=pd.DataFrame({
feature_names[0]:[iris.data[i][0] for i in range(len(iris.data))],
feature_names[1]:[iris.data[i][1] for i in range(len(iris.data))],
feature_names[2]:[iris.data[i][2] for i in range(len(iris.data))],
feature_names[3]:[iris.data[i][3] for i in range(len(iris.data))],
'type':iris.target
})
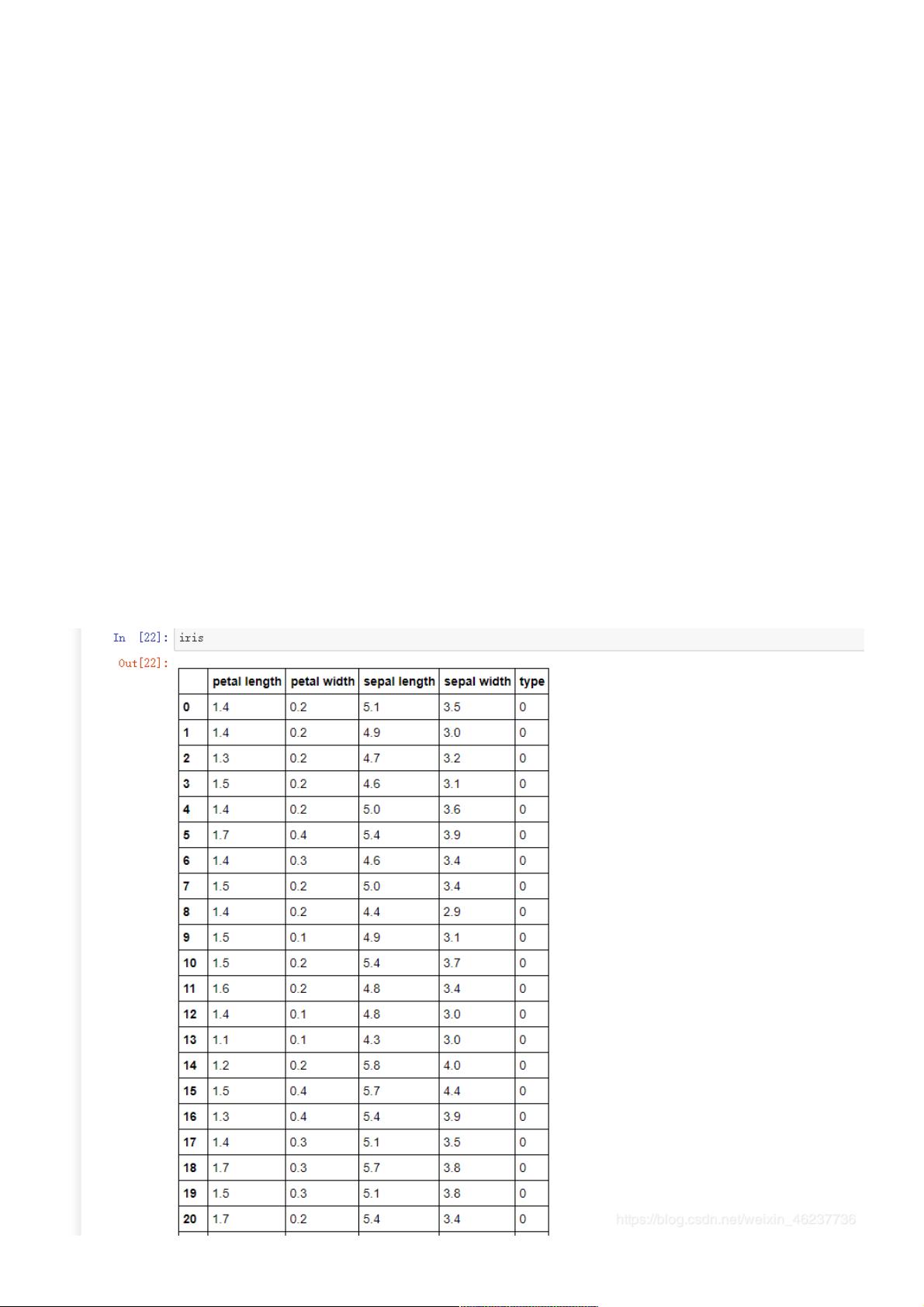
print(iris)#150*5的二维表
t
这就是iris数据集的前20行,没有截完,然后我们来看看前五行和数据总体信息描述(type的0,1,2分别表示三种花
下载后可阅读完整内容,剩余3页未读,立即下载
2019-01-15 上传
2022-02-25 上传
2021-03-12 上传
点击了解资源详情
2023-04-14 上传
2023-04-14 上传
2022-09-14 上传
2021-03-28 上传
2021-04-01 上传

weixin_38638647
- 粉丝: 7
- 资源: 993
 我的内容管理
展开
我的内容管理
展开







最新资源
- SPA美容美体连锁机构网站模板
- 变压器涌流和内部故障仿真-Simulink.zip
- salescar-front-angular
- dctx:在Docker项目中使用的上下文包
- 网络化测试
- npmrc:读取和解析.npmrc文件
- OptaplannerExample
- linux项目工程资料-基于Linux的HttpServer.zip
- PythonStuff:Python的指南,实用工具,脚本和模板
- fast-lio2代码
- Day10
- 海湾4.0高能主机调试软件.zip
- omniauth-steam:OmniAuth的Steam身份验证策略
- Rẻ Nhất Ở Đâu?-crx插件
- CurrencyExchange
- 微核固件:用于微核存储库的固件digispark部分的叉子
