iptables数据包处理流程与目标动作详解
需积分: 49 183 浏览量
更新于2024-07-21
收藏 341KB PDF 举报
"该资源是一份关于iptables的学习笔记,涵盖了数据包流向、iptables的基本组成以及各种目标和跳转,旨在帮助读者理解iptables的工作原理和配置方法。"
iptables是Linux操作系统中用于网络安全和流量控制的工具,它允许系统管理员定义一系列规则来决定网络数据包应该如何处理。这份学习笔记详细介绍了iptables的关键概念和流程。
首先,数据包流向顺序是理解iptables工作方式的基础。当一个数据包到达主机时,它会按照特定的步骤依次经过不同的表和链:
1. 数据包在网络中传输,例如通过Internet;
2. 进入主机的物理接口,如eth0;
3. 在mangle表的PREROUTING链中,用于修改数据包,如设置TOS(Type of Service);
4. 在nat表的PREROUTING链中,通常进行DNAT(Destination Network Address Translation)操作,改变目标IP地址;
5. 路由判断决定数据包是发送给本地还是转发;
6. mangle表的INPUT链,进一步修改数据包;
7. filter表的INPUT链,这是对所有目标为本地的数据包进行过滤的地方;
8. 数据包到达本地应用程序。
对于以本地为源的数据包,流程略有不同:
1. 本地应用程序发出数据包;
2. 路由判断,确定源地址、出站接口等信息;
3. mangle表的OUTPUT链,可对数据包进行修改,但不推荐在此处过滤;
4. nat表的OUTPUT链,用于SNAT(Source Network Address Translation),改变源IP地址;
5. 随后,数据包离开主机,继续其网络旅程。
笔记还提到了多个关键概念,包括:
- Tables(表):iptables有三个主要表,即mangle、nat和filter,分别处理不同的任务。
- Command(命令):用于添加、删除和检查规则。
- Matches(匹配规则):分为通用、隐含和显式,用于确定哪些数据包符合规则。
- Targets/Jumps:ACTIONs(接受、拒绝、丢弃、重定向等)或JUMPs(如到另一个链)。
理解这些基本概念和流程对于有效配置iptables规则至关重要,特别是对于需要自定义网络行为,如端口转发、NAT转换、安全过滤等场景。通过学习笔记,读者可以深入掌握iptables的使用,从而更好地管理和保护自己的网络环境。
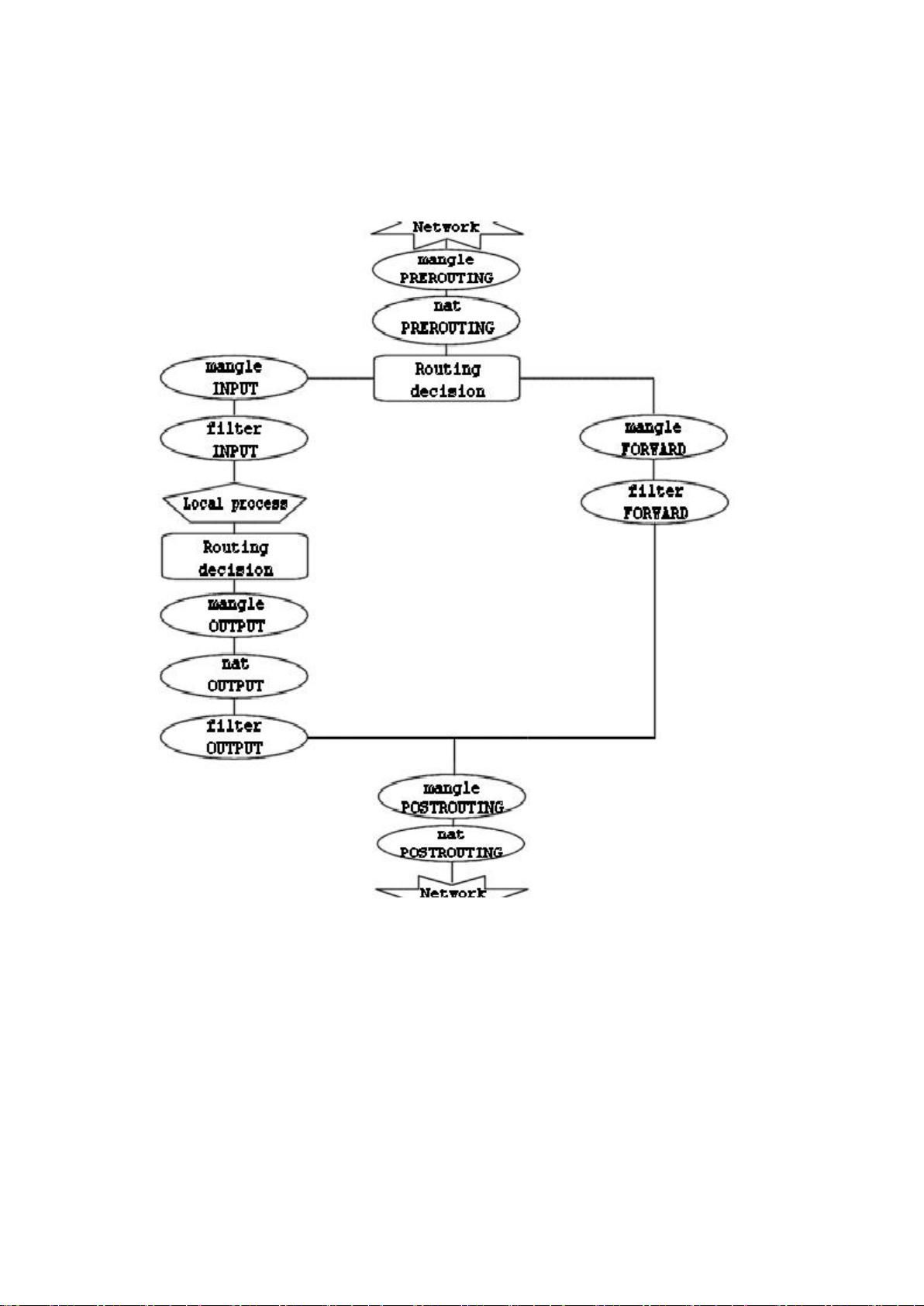
现在,我们来看看在以上三种情况下,用到了哪些不同的链。图
示如下:
规则的组成
一条完整的规则是由以下形式组成: iptables [-t table]
command [match] [target/jump] 1、表名 mangle,nat,filter
等 2、命令 -A,-I,-D 等 3、匹配 如-p tcp, -m state –state
RELATED,ESTABLISHED。 4、target/jump,如-j ACCEPT 或-j DROP

剩余43页未读,继续阅读
2021-05-24 上传
2019-05-29 上传
2020-03-11 上传
2020-06-11 上传
2021-02-05 上传

calm1
- 粉丝: 1
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
