爱丁堡大学:机器学习驱动的并行任务自动划分技术
需积分: 10 87 浏览量
更新于2024-09-18
收藏 670KB PDF 举报
爱丁堡大学的并行程序设计研究聚焦于机器学习驱动的流式并行任务划分,以优化多核处理器的性能。作者Zheng Wang和Michael F. O’Boyle,作为爱丁堡大学计算机系统架构研究所的学者,提出了一个创新的编译器基方法,旨在解决现代应用中流式编程在多核处理器上的高效映射问题。
在传统的流式编程语言中,如StreamIt,程序的并行性表达往往依赖于特定的程序结构和底层硬件。然而,这种映射并不总是最优,特别是对于复杂的多线程任务。为了解决这个问题,他们的研究开发了一个自动的、可移植的机器学习技术。该技术预先通过离线学习积累了关于不同程序特性的知识,构建了一个预测模型,能够根据给定的流式应用程序动态地预测出理想的并行任务划分结构。
通过这个预测器,研究人员能够在不执行任何代码的情况下,在程序空间中快速搜索,生成并选择最佳的并行分区方案。这种方法的优势在于它具有通用性和自动化,能够减少手动调整的工作量,提升并行程序的性能。
在实验中,他们将这项技术应用于标准的StreamIt应用,并将其与现有的并行化方法进行了对比。在四核平台上,新的机器学习驱动的并行任务划分策略显示出显著的性能优势,尤其是在处理大规模数据流和复杂计算任务时,其效率和可扩展性得到了验证。
爱丁堡大学的这项工作为并行程序设计领域提供了一种新颖且实用的方法,它结合了机器学习的力量来自动优化流式程序在多核环境中的性能,有望推动并行计算技术的发展,使得开发者能更轻松地构建高性能的并行应用。这对于提高现代信息技术系统的整体效能具有重要意义。
MP3DECODER DES DCT
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Dynamic Programming Partitioner Greedy Partitioner
Speedup
(a) 4-core platform
MP3DECODER DES DCT
0.0
0.5
1.0
1.5
2.0
Speedup
Dynamic Programming Partitioner Greedy Partitioner
(b) 8-core platform
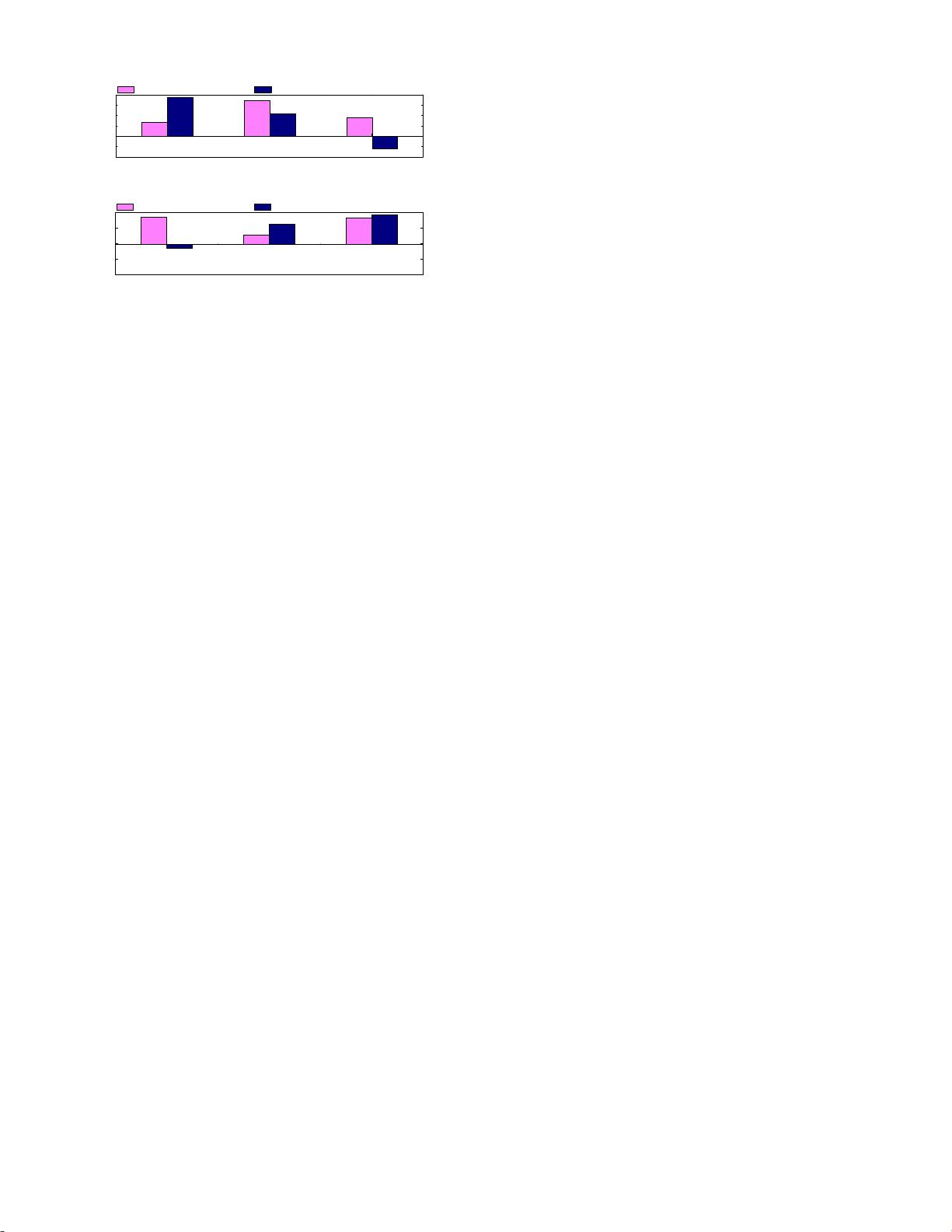
Figure 2: The relative performance of 2 partitioning
schemes with respe ct to a na
¨
ıve partitioning s cheme.
The results are shown for 2 platforms and 3 distinct
StreamIt programs. Greedy partitioning performs
well on MP3DECODER on the 4-core platform but
not as well as dynamic programming partitioning
on the 8-core. This relative ordering is reversed for
DES and DCT. Determining the best partitioning
depends on program and platform.
form is known to be NP-complete and it is difficult to devise
a general heuristics [5].
To illustrate this point, consider figure 2, which shows the
performance of each partitioning approach on two different
multi-core platforms: a 2x dual-core (4-core) machine and
a 2x quad-core (8-core) machine. On the 4-core the greedy
scheme performs well for MP3DECODER; it has a lower
communication cost, exploiting data parallelism rather than
the pipeline parallelism favoured by the dynamic p rogram-
ming partitioner. On the 8-core p latform, however, the dy-
namic programming-based heuristic delivers better perfor-
mance as load balancing becomes critical.
When examining two further programs, DES and DCT,
we see the best partitioning algorithm for a particular ma-
chine is reversed. The figure shows that there is no current
”one-fits-all” heuristic and the best heuristic varies across
programs and architectures. Rather than relying on heuris-
tics, we would like a scheme that automatically predicts the
right sequence of fuse and fission operations for each pro-
gram and architecture. In the case of MP3DECODER, th is
means we want to select the operations that give the parti-
tioned code in figure 1 (b) for 4-cores and the partitioned
code in figure 1 (c) for 8-cores. However, predicting the cor-
rect sequences of fuse and fission is highly non-triv ial given
the unbounded stru cture of the input program graphs.
In the next section we describe our novel approach. Rather
than predicting the sequence of fuse and fission operations
directly, it tries to predict the right structure of the final
partitioned program. Given this target structure, it then
searches for a sequence of fuse and fission operations that
generates a partitioned program that fit s the predicted struc-
ture as closely as possible.
3. PREDICTING AND GENERATING A
GOOD PARTITION
One of the hurdles in predicting the best sequence of fu-
sion and fission op erations is that the graph keeps changing
structure after each operation. In figure 3, the second oper-
ation fiss(2.3) would have to be renamed fiss(1.6) if the first
operation (fuse(1.2,1.3,1.4,1.5)) had not taken place. A ny
scheme that tries to predict a sequence of fuse and fission
operations h as therefore to take into consideration the struc-
ture of the graph at each intermediate stage. The supervised
predictive modelling schemes explored to date are incapable
of managing this [9]. We take a different approach. Instead
of trying to predict the sequence of fuse and fission opera-
tions, we divide the problem into two stages as illustrated
in figure 4:
1. Predict the ideal structure of the final partitioned pro-
gram.
2. Search a space of operation sequences th at delivers a
program as close as possible to the ideal structure.
The first stage focuses on determining th e goal of parti-
tioning, i.e., the structure of the partitioned p rogram with-
out regard to how it may be actually realised. The second
stage explores different legal operation sequences u ntil the
generated partitioned p rogram matches the goal. This frees
us from the concern of correctly predicting the syntactically
correct sequence of fuse and fission operations. Instead we
can try arbitrary sequences u ntil we reach a partition that
closely matches our goal. The next section describes how
we can predict a good partitioning goal and is followed by
a section describing how we can generate a sequence of fuse
and fission operations to reach that goal.
3.1 Predicting the Ideal Partitioning Structure
- Setting the Goal
We wish to predict the ideal partitioned stru cture of any
input graph program. In order to cast this as a machine
learning problem, we wish to build a function f which, given
the essential characteristics or features X
orig
of the origi-
nal program predicts the features of the ideal partitioned
program X
ideal
. Building and using such a model follows
the well-known 3 step process for supervised machine learn-
ing [4]: (i) generate training data (ii) train a predictive
model (iii) use th e predictor. We generate training data
by evaluating (executing) randomly generated partitions for
each training program and recording their execution time.
The features of the original and best p artitioned program
are then used to train a mod el which is then used to pre-
dict the best ideal partitioning structure for any new unseen
program. One of the key aspects in building a successful pre-
dictor is developing the right program features in order to
characterise the original and goal program. This is described
in th e next section. This is followed by sections describing
training data generation, building the predictor using near-
est neighbors and then using t he predictor.
3.2 Extracting Features
Rather than trying to deal with unbounded program graphs
as input and outputs to our predictor, we describe the essen-
tial characteristics of such graphs by a fixed feature vector
of numerical values. The intention is that programs with
similarly feature vectors have similar behaviour. We empir-
ically evaluate this assumption in section 6.3. In this work,
we use program features, to characterise a streaming applica-
tion. The set of program features are summarized in table 1.
We extract two sets of those features from the overall stream
graph and the critical path of the program. Thereby, one set
309
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-04 上传
269 浏览量
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传

yuanjilai
- 粉丝: 40
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小学水墨风学校网站模板设计
- 深入理解线程池的实现原理与应用
- MSP430编程代码集锦:实用例程源码分享
- 绿色大图幻灯商务响应式企业网站开发源码包
- 深入理解CSS与Web标准的专业解决方案
- Qt/C++集成Google拼音输入法演示Demo
- Apache Hive 0.13.1 版本安装包详解
- 百度地图范围标注技术及应用
- 打造个性化的Windows 8锁屏体验
- Atlantis移动应用开发深度解析
- ASP.NET实验教程:源代码详细解析与实践
- 2012年工业观察杂志完整版
- 全国综合缴费营业厅系统11.5:一站式缴费与运营管理解决方案
- JAVA原生实现HTTP请求的简易指南
- 便携PDF浏览器:随时随地快速查看文档
- VTF格式图片编辑工具:深入起源引擎贴图修改
