Hadoop+Scala+Spark配置详解与步骤
需积分: 14 66 浏览量
更新于2024-09-09
收藏 116KB DOC 举报
本文主要介绍了如何配置Hadoop分布式系统,结合Scala和Spark进行开发。Hadoop是一个开源的大数据处理框架,核心组成部分包括Hadoop Distributed File System (HDFS) 和 MapReduce引擎。HDFS负责存储大规模数据,而MapReduce则提供了并行处理数据的能力。在此基础上,本文还着重讲解了以下几个关键步骤:
1. **DNS配置**:为了确保正确解析主机名,修改了`/etc/sysconfig/network-scripts/ifcfg-eth0`文件,添加了DNS服务器地址(例如8.8.8.8),并重启网络服务。
2. **主机名和SSH无密码登录**:配置了主机名`master`,修改了`/etc/hostname`和`/etc/sysconfig/network`中的主机名。通过SSH密钥对实现了Master节点与其他节点之间的无密码登录,包括密钥生成、复制和授权。
3. **JDK和Hadoop安装**:首先通过`yum`安装Java 1.7.0版本,然后下载Hadoop 2.6.0版本,解压到`/usr/local`目录,并设置Hadoop环境变量到`.bashrc`文件中,以便在终端中调用Hadoop命令。
4. **Scala和Spark集成**:虽然题目中没有明确提到Scala和Spark的配置,但可以推测是在这个阶段开始考虑如何在Hadoop环境中集成Scala语言,因为Scala是Hadoop生态系统中常用的编程语言之一,而Spark是基于Hadoop的实时大数据处理框架,通常会与Hadoop一起部署。
5. **数据仓库工具和分布式数据库**:文中提到了Hive,这是一个基于Hadoop的数据仓库工具,用于查询和分析大规模数据;还有HBase,一个分布式NoSQL数据库,也是Hadoop生态系统的一部分。这些工具可以进一步扩展Hadoop的功能,提高数据处理效率。
6. **文件传输**:使用SCP命令将SSH公钥复制到其他节点的`~/.ssh/authorized_keys`,便于后续的无密码登录。
这篇文章提供了一个详细的Hadoop配置指南,包括基础环境的设置、安全性和Java环境的准备,以及如何与Scala和Spark协同工作,对于希望在Hadoop平台上进行大数据处理和分析的开发者来说,是一份宝贵的参考资料。
核心架构
Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存
储 Hadoop 集群中所有存储节点上的文件。HDFS(对于本文)的上一层是 MapReduce
引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对 Hadoop 分布式计算平台最核
心的分布式文件系统 HDFS、MapReduce 处理过程,以及数据仓库工具 Hive 和分布式数
据库 Hbase 的介绍,基本涵盖了 Hadoop 分布式平台的所有技术核心
一 hadoop 配置
1,配置 DNS
添加
然后重启
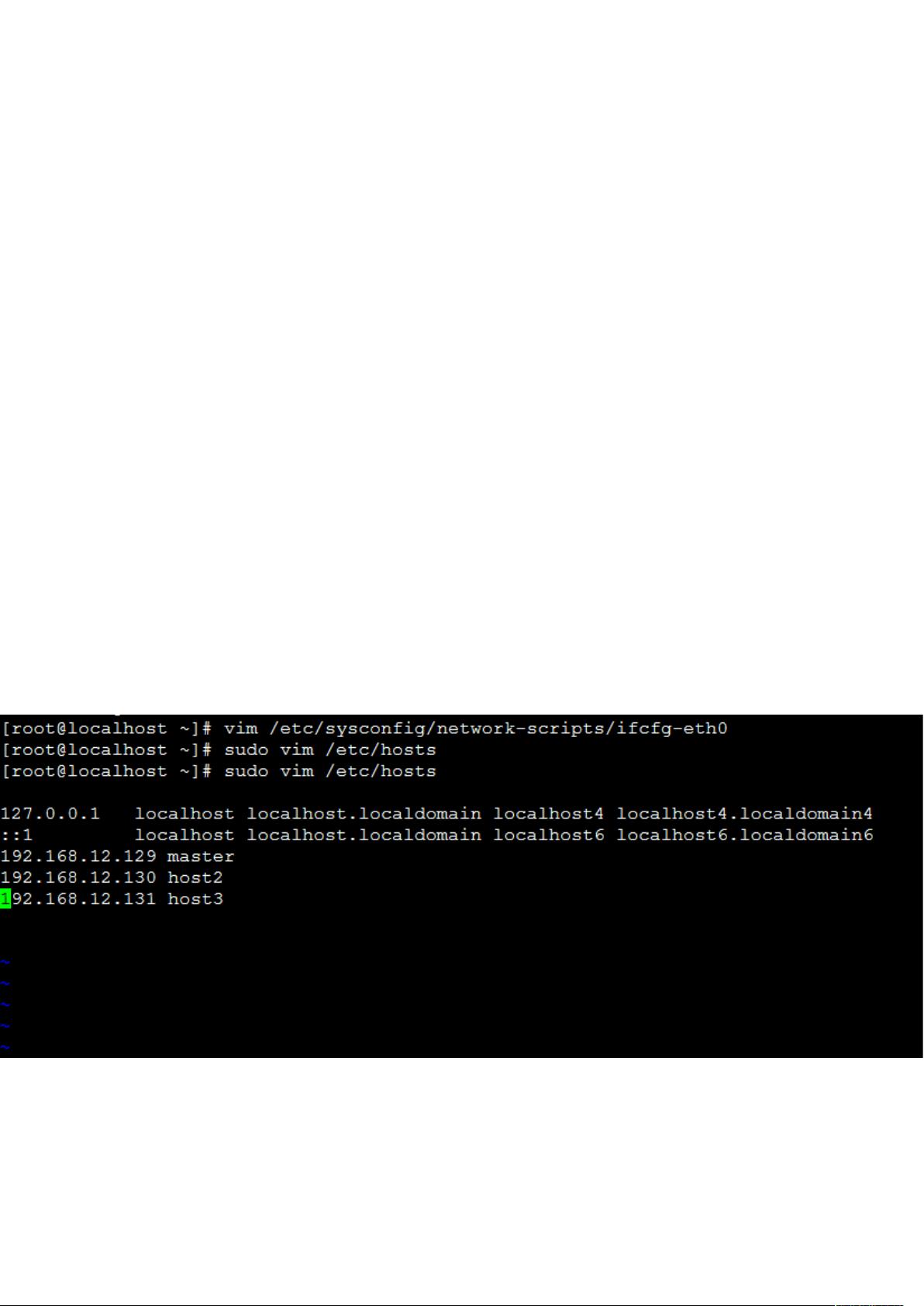
2,配置 hosts,
如图
配置添加
配置修改 !"#$%&
下载后可阅读完整内容,剩余8页未读,立即下载
2020-07-08 上传
2023-10-16 上传
点击了解资源详情
2020-09-17 上传
2024-05-29 上传
2018-01-26 上传
2023-05-05 上传
2023-09-17 上传
2018-02-02 上传

doudou_715
- 粉丝: 2
- 资源: 47
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
