深入理解Kafka:第二版精华解读
"《Kafka权威指南》第二版"
在《Kafka权威指南》第二版中,作者深入探讨了Kafka这一分布式流处理平台的核心概念和技术。Kafka是一种基于发布/订阅模式的消息传递系统,旨在解决传统消息队列系统的局限性。
**1.1 Meet Kafka**
**a. Publish/Subscribe Messaging**
Kafka的起点在于它提供的发布/订阅模型。与传统的个体队列系统不同,Kafka允许多个生产者同时发布数据,而多个消费者可以并行消费这些数据,增强了系统的并发性和处理能力。
**b. Enter Kafka**
- **Messages and Batches**: Kafka的消息是以批次的形式存储和传输,这种设计提高了效率和吞吐量。
- **Schemas**: Kafka支持使用Schema Registry来管理消息的结构,确保数据的一致性和兼容性。
- **Topics and Partitions**: 主题是Kafka中逻辑上的分类,而分区是物理上的细分,提供了水平扩展的能力。
- **Producers and Consumers**: 生产者负责写入数据,消费者则负责读取和处理数据,它们通过Kafka的API进行交互。
- **Brokers and Clusters**: Kafka集群由多个服务器(broker)组成,提供高可用性和容错性。
- **Multiple Clusters**: Kafka还支持跨多集群部署,以满足大规模和地理分布的需求。
**c. Why Kafka?**
Kafka因其以下特性而受到青睐:
- **Multiple Producers**: 支持多个生产者并发写入,提高数据输入速度。
- **Multiple Consumers**: 支持多消费者组,使得数据可以被多个并行处理的消费者同时消费。
- **Disk-Based Retention**: 数据持久化到磁盘,保证了数据的可靠性。
- **Scalable**: 能随着数据量的增长轻松扩展。
- **High Performance**: 高吞吐量和低延迟,使得Kafka成为实时数据处理的理想选择。
**d. The Data Ecosystem**
Kafka广泛应用于大数据生态系统,如日志聚合、流处理、实时分析等场景。
**e. Kafka’s Origin**
- **LinkedIn’s Problem**: Kafka最初由LinkedIn开发,用于解决内部大规模数据处理的挑战。
- **The Birth of Kafka**: 2011年,Kafka项目启动,设计目标是构建一个可扩展且高性能的消息系统。
- **Open Source**: 2011年底,Kafka开源,成为Apache软件基金会的顶级项目。
- **Commercial Engagement**: 后来,Confluent公司成立,专注于Kafka的商业支持和服务。
- **The Name**: 名字“Kafka”来源于作者喜欢的作家弗朗茨·卡夫卡。
**f. Getting Started with Kafka**
书中介绍了如何开始使用Kafka,包括安装、配置以及编写简单的生产者和消费者应用。
**2.2 Managing Apache Kafka Programmatically**
**a. Admin Client Overview**
- **Asynchronous and Eventually Consistent API**: 管理客户端的API是异步的,确保操作的高效率,但可能不立即反映在所有节点上。
- **Options**: 提供多种选项以适应不同的管理需求。
- **Flat Hierarchy**: 简单的层次结构使得管理操作更加直观。
- **Additional Notes**: 包括对客户端DNS查找和请求超时的配置建议。
**b. Admin Client Lifecycle**
- **client.dns.lookup** 和 **request.timeout.ms** 是配置管理客户端时的关键参数,影响网络通信和操作的可靠性。
**c. Essential Topic Management**
这部分详细讲解了创建、配置和删除主题的步骤。
**d. Configuration Management**
讨论了如何管理和调整Kafka集群的配置,以优化性能或适应变化的需求。
**e. Consumer Group Management**
- **Exploring Consumer Groups**: 如何查看和理解消费者组的状态。
- **Modifying Consumer Groups**: 演示如何调整消费者组的设置。
**f. Cluster Metadata**
介绍获取和更新集群元数据的方法,这对于监控和故障排查至关重要。
**g. Advanced Admin Operations**
- **Adding partitions to a topic**: 随着数据量增长,可以动态增加主题的分区。
- **Deleting records from a topic**: 提供了删除主题中特定记录的策略。
- **Leader Election**: 领导者选举是保持集群运行的关键过程,书中详细解释了这一过程。
- **Reassigning Replicas**: 当需要调整副本分配时,如何进行重新分配以优化集群性能。
这本书全面覆盖了Kafka的各个方面,无论你是初学者还是经验丰富的开发者,都能从中受益。它不仅提供了理论知识,还包含大量实践指导,帮助读者深入理解和有效使用Kafka。
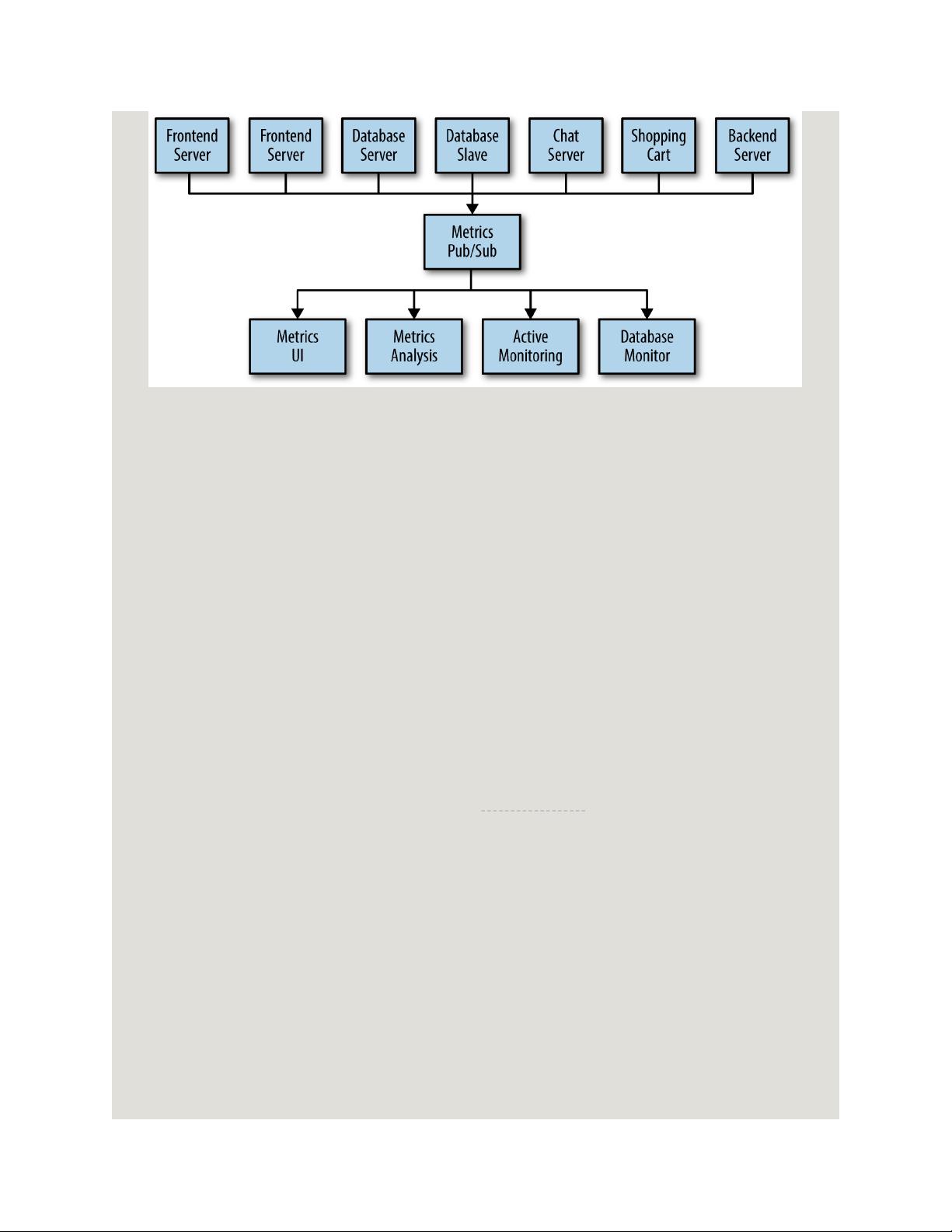
Figure 1-3. A metrics publish/subscribe system
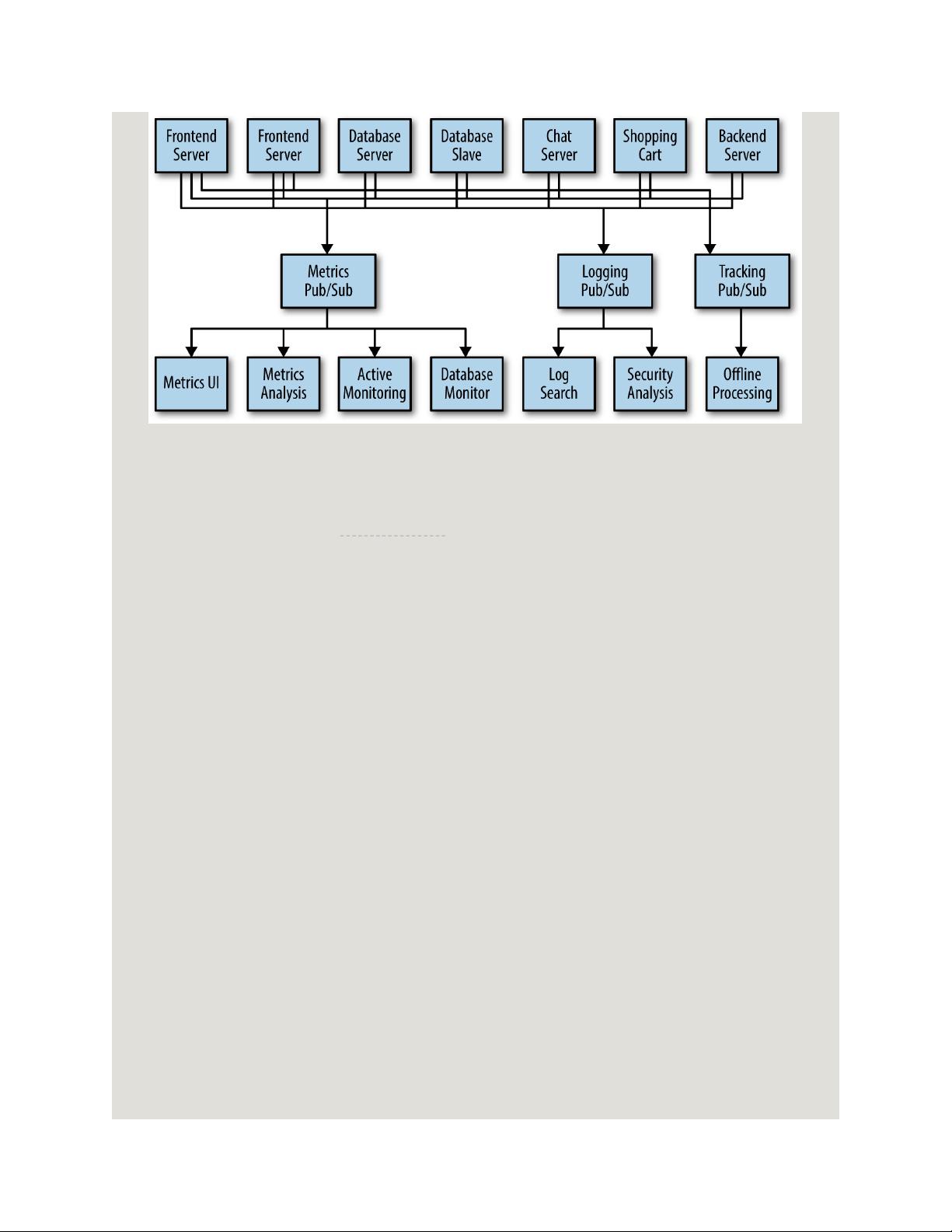
Individual Queue Systems
At the same time that you have been waging this war with
metrics, one of your coworkers has been doing similar work
with log messages. Another has been working on tracking user
behavior on the frontend website and providing that
information to developers who are working on machine
learning, as well as creating some reports for management. You
have all followed a similar path of building out systems that
decouple the publishers of the information from the
subscribers to that information. Figure 1-4 shows such an
infrastructure, with three separate pub/sub systems.


剩余79页未读,继续阅读
2019-05-03 上传
2018-10-31 上传
2017-11-09 上传
2018-06-15 上传
2017-10-06 上传
2017-11-29 上传
2017-10-06 上传
2017-11-14 上传
2018-11-13 上传

xm1223
- 粉丝: 2
- 资源: 36
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
