OpenCV HaarTraining算法详解与应用
需积分: 10 119 浏览量
更新于2024-09-11
收藏 314KB PDF 举报
本文详细介绍了OpenCV中的HaarTraining算法,这是一种基于Friedman, J. H等人提出的"Additive Logistic Regression: a Statistical View of Boosting"理论,用于实现二类分类问题的Boost算法,包括Discrete AdaBoost, Real AdaBoost, LogitBoost和Gentle AdaBoost。该算法还涉及到了Additive Logistic Trees和Weight Trimming的概念。在实际应用中,OpenCV的HaarTraining算法主要被用于构建级联分类器,这一技术源自Paul Viola和Michael Jones的"Robust Real-Time Face Detection"论文,它使用了扩展的Haar特征,这些特征对快速对象检测非常有效。
文章的结构分为三个主要部分:样本准备、创建样本集和训练分类器。首先,为了训练Haar分类器,需要准备正负样本。正样本通常包含目标对象,如人脸检测中的面部图像,需要先裁剪并调整到统一尺寸。负样本则包含没有目标对象的图像区域。
1. 样本准备:正样本是训练过程的核心,它们是含有我们想要检测的目标的图像。为了方便训练,正样本通常需要预先处理,裁剪成特定大小并保存为vec文件,以便于HaarTraining程序使用。而负样本通常从大量背景图像中随机选取,以模拟各种环境条件。
2. 创建样本集:使用OpenCV的CreateSamples工具,将正负样本转化为可以输入到训练程序的数据格式。这个步骤会生成必要的文件,如vec文件,这些文件包含了样本的像素值信息。
3. 训练分类器:最后,使用HaarTraining程序对处理好的样本集进行训练,生成一个XML文件,这个文件就是最终的分类器模型,可以用于实时检测任务。
在训练级联分类器时,HaarTraining会逐步构建多个弱分类器,每个弱分类器只排除一部分背景区域,最后组合成一个强分类器,从而实现高效率和高精度的目标检测。
OpenCV的HaarTraining算法是一种强大的机器学习工具,它结合了Boosting策略和特定的特征描述符(Haar特征),在目标检测,尤其是人脸识别领域,发挥了重要作用。理解并熟练运用这一算法,对于开发高效的计算机视觉系统至关重要。
像数据。
3.2 负样本
负样本图像可以是不含有正样本模式的任何图像,比如一些风景照等。训练时,OpenCV
需要一个负样本描述文件,该文件只需包含所有负样本的文件名及绝对(或相对)路径名。
以下是一个负样本描述文件内容示例:
nonface_200/00001.bmp
nonface_200/00002.bmp
nonface_200/00003.bmp
…
负样本描述文件的生成方法可参照正样本描述文件生成方法。
负样本图像的大小只要不小于正样本就可以,在使用负样本时,OpenCV 自动从负样本
图像中抠出一块和正样本同样大小的区域作为负样本,具体可查看函数
icvGetNextFromBackgroundData()。具体抠图过程为:
1) 确定抠图区域的左上角坐标(Point.x, Point.y)
2) 确定一个最小缩放比例,使得原负样本图像缩放后恰好包含选中负样本区域
3) 对原负样本图象按计算好的缩放比例进行缩放
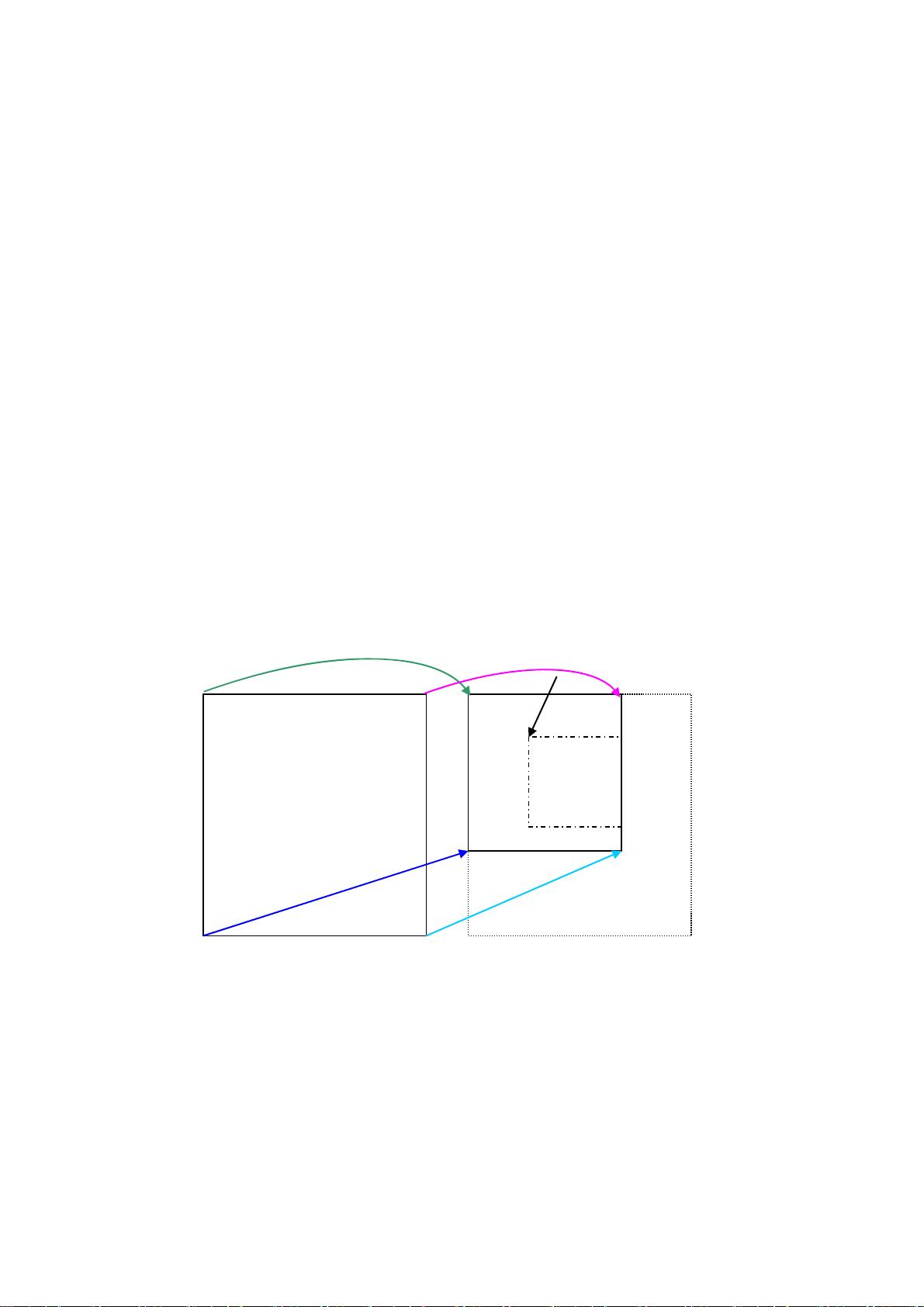
4) 在缩放后的图像上抠出负样本,如图 3.2 左半部分的虚线框所示。
Reader->img
Reader->src
(Point.x,Point.y)
图 3.2 抠图示意图
3
剩余11页未读,继续阅读
2013-08-19 上传
2013-06-02 上传
2014-08-11 上传
2008-09-26 上传
2020-10-26 上传
2023-07-06 上传
132 浏览量
2019-11-12 上传

ws1861
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
