Python决策树分类算法详解
36 浏览量
更新于2024-09-03
2
收藏 112KB PDF 举报
"Python决策树分类算法的学习教程"
Python决策树分类算法是一种广泛应用的机器学习算法,主要用于分类任务。它的核心思想是通过构建树状模型来模拟人类决策过程,以一系列特征值作为判断条件,逐步划分数据,最终形成决策路径。决策树的优势在于易于理解和解释,同时在处理离散和连续数据时都有较好的表现。
决策树的构建通常涉及几个关键步骤:
1. **选择最佳划分属性**:在构建决策树的过程中,我们需要选择一个属性,使得基于该属性的划分能够最大程度地减少数据的不确定性,也就是最大化信息增益。信息增益是通过比较划分前后的信息熵来度量的。信息熵是衡量数据纯度的一个指标,纯度越高,熵越低。当所有样本属于同一类别时,熵为0,表示数据完全有序。
2. **ID3算法**:J.Ross Quinlan在1975年提出的ID3算法是最早的决策树构建算法之一,它基于信息增益来选择划分属性。但ID3算法在处理连续属性和缺失值时存在局限性。
3. **C4.5与C5.0**:C4.5是ID3的升级版,解决了ID3的一些问题,如处理连续属性和不纯数据,且引入了信息增益比来避免过早选择划分属性。C5.0是C4.5的进一步优化,提高了算法效率和准确性。
4. **CART(Classification and Regression Trees)**:CART算法不仅可以用于分类,还可以用于回归任务。它使用基尼不纯度(Gini Impurity)作为划分标准,更适合处理连续变量。
5. **构建过程**:在构建决策树时,算法会递归地将数据集划分为更小的子集,直到满足停止条件,如达到预设的最大深度、最小样本数量或者所有样本属于同一类别。
6. **剪枝策略**:为了避免过拟合,决策树算法通常采用预剪枝和后剪枝策略。预剪枝是在训练阶段提前停止树的生长,设定最小样本数或最大深度限制。后剪枝则是在树构建完成后,自底向上地删除子树,检查删除后的性能变化,若改善则保留剪枝。
7. **Python实现**:在Python中,常用的库如`scikit-learn`提供了决策树的实现,包括`DecisionTreeClassifier`和`DecisionTreeRegressor`,用户可以通过调整参数来控制决策树的复杂度,例如设置`max_depth`限制树的最大深度,`min_samples_split`定义划分子集所需的最小样本数等。
8. **实际应用**:决策树广泛应用于各种领域,如信用评分、医疗诊断、市场分割、文本分类等。由于其易于理解和解释的特性,决策树也常作为其他复杂模型(如随机森林和梯度提升机)的基础。
9. **案例分析**:在给出的例子中,我们看到如何通过计算信息熵和信息增益来选择最佳划分属性。在这个苹果分类的例子中,先根据“红苹果”(A0)属性划分可以得到更高的信息增益,因此更优。
Python决策树分类算法是一种强大而灵活的工具,通过理解其基本原理和操作流程,我们可以更好地利用它来解决实际的分类问题。在实践中,我们需要结合具体的数据集和业务需求,适当调整算法参数,以达到最佳的预测效果。
Python决策树分类算法学习决策树分类算法学习
主要为大家详细介绍了Python决策树分类算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
从这一章开始进入正式的算法学习。
首先我们学习经典而有效的分类算法:决策树分类算法。
1、决策树算法
决策树用树形结构对样本的属性进行分类,是最直观的分类算法,而且也可以用于回归。不过对于一些特殊的逻辑分类会有困
难。典型的如异或(XOR)逻辑,决策树并不擅长解决此类问题。
决策树的构建不是唯一的,遗憾的是最优决策树的构建属于NP问题。因此如何构建一棵好的决策树是研究的重点。
J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3算法。后续的C4.5, C5.0, CART等都是
该方法的改进。
熵就是“无序,混乱”的程度。刚接触这个概念可能会有些迷惑。想快速了解如何用信息熵增益划分属性,可以参考这位兄弟的
文章:Python机器学习之决策树算法
如果还不理解,请看下面这个例子。
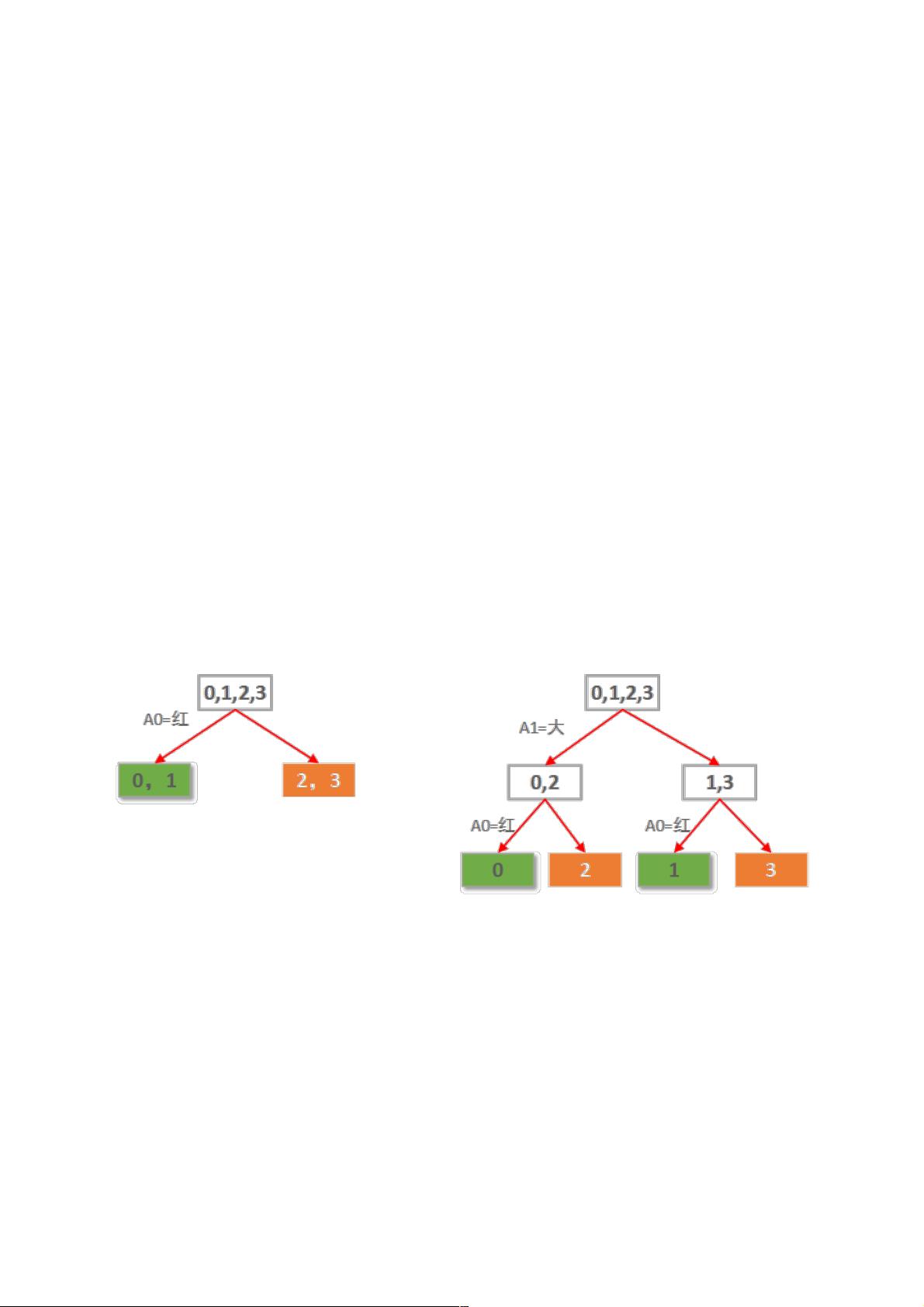
假设要构建这么一个自动选好苹果的决策树,简单起见,我只让他学习下面这4个样本:
样本 红 大 好苹果
0 1 1 1
1 1 0 1
2 0 1 0
3 0 0 0
样本中有2个属性,A0表示是否红苹果。A1表示是否大苹果。
那么这个样本在分类前的信息熵就是S = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
信息熵为1表示当前处于最混乱,最无序的状态。
本例仅2个属性。那么很自然一共就只可能有2棵决策树,如下图所示:
显然左边先使用A0(红色)做划分依据的决策树要优于右边用A1(大小)做划分依据的决策树。
当然这是直觉的认知。定量的考察,则需要计算每种划分情况的信息熵增益。
先选A0作划分,各子节点信息熵计算如下:
0,1叶子节点有2个正例,0个负例。信息熵为:e1 = -(2/2 * log(2/2) + 0/2 * log(0/2)) = 0。
2,3叶子节点有0个正例,2个负例。信息熵为:e2 = -(0/2 * log(0/2) + 2/2 * log(2/2)) = 0。
因此选择A0划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 0。
选择A0做划分的信息熵增益G(S, A0)=S - E = 1 - 0 = 1.
事实上,决策树叶子节点表示已经都属于相同类别,因此信息熵一定为0。
同样的,如果先选A1作划分,各子节点信息熵计算如下:
0,2子节点有1个正例,1个负例。信息熵为:e1 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
1,3子节点有1个正例,1个负例。信息熵为:e2 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
因此选择A1划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 1。也就是说分了跟没分一样!
选择A1做划分的信息熵增益G(S, A1)=S - E = 1 - 1 = 0.
因此,每次划分之前,我们只需要计算出信息熵增益最大的那种划分即可。
2、数据集、数据集
下载后可阅读完整内容,剩余3页未读,立即下载
2018-07-22 上传
2018-07-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-07-10 上传
2022-07-14 上传
点击了解资源详情

weixin_38547882
- 粉丝: 4
- 资源: 884
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
