"7个经典的python爬虫案例附源码分享,适合新手入门学习"
需积分: 5 181 浏览量
更新于2024-01-29
6
收藏 2.99MB PDF 举报
本次爬虫案例涉及了对某吧中的 NBA 吧中一篇帖子的回复内容进行爬取。我们使用了Python的requests库来发送HTTP请求,并设置了合适的User-Agent来模拟浏览器请求。具体源码如下:
```python
import requests
import re
def crawl_comments():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
page = 1
while True:
url = f'https://tieba.baidu.com/p/7882177660?pn={page}'
resp = requests.get(url, headers=headers)
html = resp.text
comments = re.findall('style="display:;"> (.*?)</div>', html)
if not comments:
break
for comment in comments:
print(comment)
page += 1
crawl_comments()
```
使用上述代码,我们先定义了一个函数`crawl_comments()`,函数中设置了请求头部信息,包括User-Agent,然后通过一个循环来依次爬取每一页的评论。在每一页的HTML代码中,我们使用正则表达式来匹配回复的具体内容,并将其打印出来。
这个爬虫案例中涉及到了re正则表达式的使用,通过正则表达式找到了帖子中的回复内容。顺便提一下,正则表达式是用来处理字符串的一种工具,可以根据一定的规则来匹配、查找和替换字符串中的内容。在爬虫中,我们可以利用正则表达式来提取需要的数据。
当然,如果你对re正则有所不熟悉,也可以使用其他库来处理HTML代码,比如XPath或者Beautiful Soup。接下来,我们将介绍一些其他案例涉及到的知识点,比如XPath和Beautiful Soup。
在爬虫中,XPath是一种在HTML或XML文档中进行导航和提取数据的语言。它是基于节点关系的表达式语言,可以通过节点名称、层级关系、属性等来选择和筛选需要的内容。
Beautiful Soup是一个Python库,可以用于从HTML或XML文档中提取数据。它可以根据标签的名称、属性、层级关系等来筛选和提取需要的内容,功能强大而且使用简便。
总体来说,本次的7个Python爬虫小案例涉及了正则、XPath、Beautiful Soup和Selenium等知识点,非常适合刚入门Python爬虫的小伙伴参考学习。无论是使用哪种工具,关键是理解其原理和使用方法,然后根据实际需求选择合适的方式来提取数据。
同时,需要注意的是在进行爬虫时遵守相关法律法规,尊重网站的隐私和版权,如果涉及到版权或隐私问题,请及时联系网站管理员进行处理。
以上是本次爬虫案例的简要总结和描述,希望对大家有所帮助。如果有任何问题或疑问,欢迎在评论区留言,我会尽快回复。
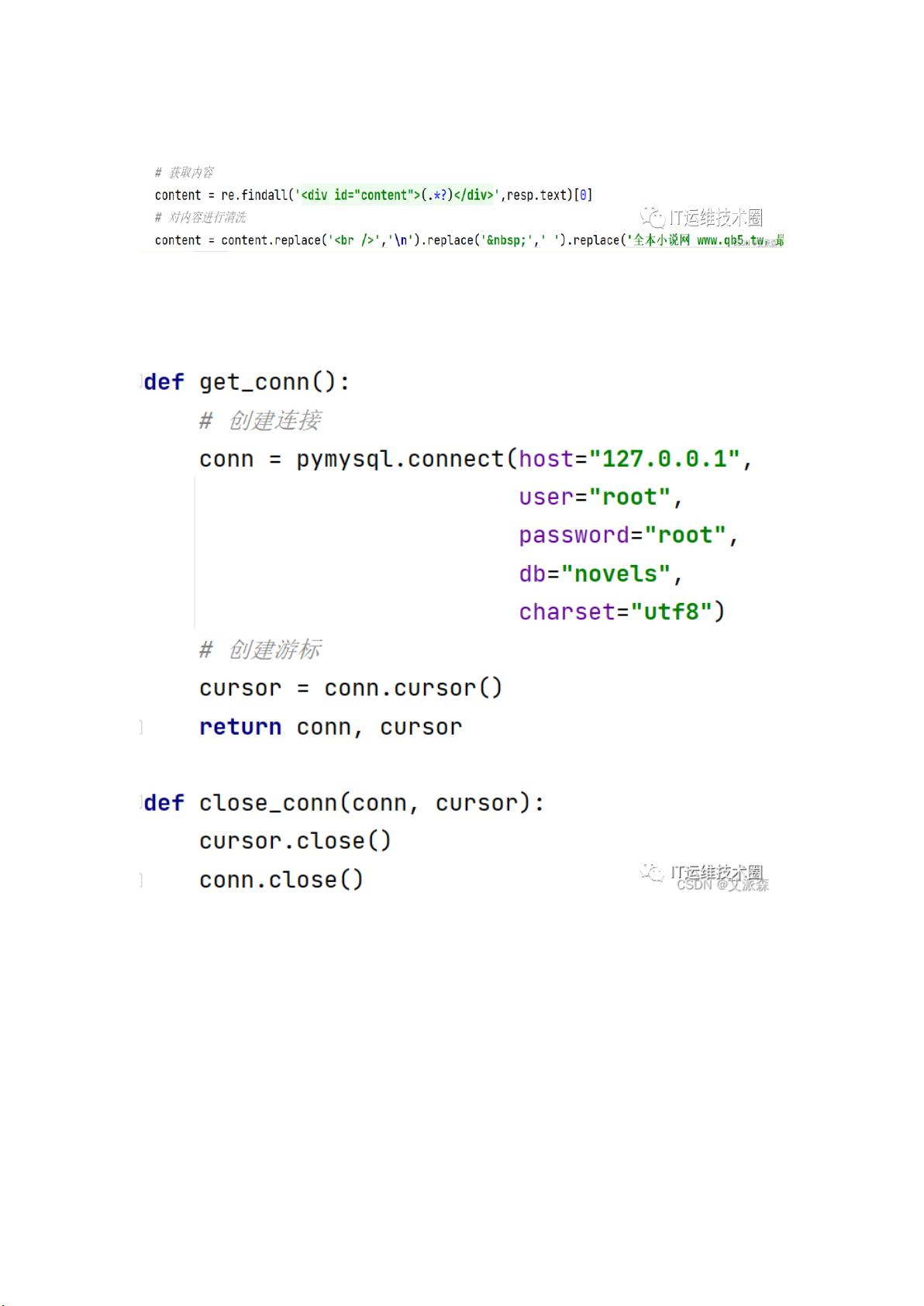
这里我们选用 re 正则表达式进行数据提取,并对最后的结果进行清洗
然后我们需要将数据保存到数据库中,这里我将爬取的数据存储到 mysql 数据
库中,先封住一下数据库的操作
接着将爬取到是数据进行保存
剩余26页未读,继续阅读
2023-11-21 上传
2023-09-04 上传
2023-06-08 上传
2024-10-05 上传
2023-06-01 上传
2021-12-25 上传

红烧小肥杨
- 粉丝: 1455
- 资源: 2063
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
