HBase Scan最佳实践:深入理解与误区解析
178 浏览量
更新于2024-08-28
收藏 294KB PDF 举报
HBase最佳实践——深入解析Scan用法
在HBase中,尽管基本的增删改查操作相对简单,但Scan方法的使用却可能涉及更为复杂的场景和潜在问题。Scan是HBase数据读取的核心工具,它在HBase中的主要用法包括Scan API、TableScanMR和SnapshotScanMR三种。这三种扫描方式各有其原理和适用场景,理解它们的工作原理和最佳实践至关重要。
首先,Scan API是最常见的扫描方式,它的原理并非一次性从服务器获取所有满足条件的数据,而是通过客户端与服务器交互实现。当客户端发起一个next请求时,它会先检查本地缓存,如果没有数据,则向服务器请求。服务器会从BlockCache、HFile和memcache等多个层次逐行查找数据,达到一定数量后返回给客户端,客户端再逐步处理这些数据。这种设计使得HBase能够在大规模数据中高效地进行扫描,但同时也需要注意缓存策略对性能的影响。
TableScanMR(MapReduce扫描)适用于需要对大量数据进行离线分析或批量处理的场景,它通过MapReduce框架将扫描任务分解到集群的不同节点,从而提高处理能力。然而,TableScanMR相比Scan API可能导致更高的延迟,并且在实时性要求高的场景下可能不太适用。
SnapshotScanMR则涉及到数据快照,当需要基于某个特定时间点的数据进行扫描时,它利用HBase的快照功能,提供了对历史版本数据的访问。这种扫描方式通常用于审计或回溯等需求,对数据一致性有较高要求。
理解并掌握这三种Scan用法,企业可以根据自身的业务场景选择最合适的扫描策略,如对实时性要求高的应用适合Scan API,大数据分析任务则可能倾向于TableScanMR,而需要历史数据查询的场景则选择SnapshotScanMR。同时,避免对Scan的常见误解,如错误地认为HBase能立即返回所有数据,实际它是按需获取的。通过深入理解这些核心概念,开发者可以更有效地优化HBase的数据读取性能,提升整体系统的效率。后续文章将会深入探讨Scan在HDFS层面的具体实现细节,敬请关注。
HBase最佳实践最佳实践–Scan用法大观园用法大观园
HBase从用法的角度来讲其实乏陈可善,所有更新插入删除基本一两个API就可以搞定,要说稍微有点复杂的话,Scan的用法
可能会多一些说头。而且经过笔者观察,很多业务对Scan的用法可能存在一些误区(对于这些误区,笔者也会在下文指
出),因此有了本篇文章的写作动机。也算是Scan系列的其中一篇吧,后面对于Scan还会有一篇结合HDFS分析HBase数据
读取在HDFS层面是怎么一个流程,敬请期待。
HBase中Scan从大的层面来看主要有三种常见用法:ScanAPI、TableScanMR以及SnapshotScanMR。三种用法的原理不尽
相同,扫描效率也当然相差甚多,最重要的是这几种用法适用于不同的应用场景,业务需要根据自己的使用场景选择合适的扫
描方式。接下来分别对这三种用法从工作原理、最佳实践两个层面进行解析,最后再纵向对三种用法进行一下对比,希望大家
能够从用法层面对Scan有更多了解。
ScanAPI
scan客户端设计原理
最常见的scan用法,见官方API文档。scan的原理之前在多篇文章中都有提及,为了表述方便,有必要在此简单概述一番。
HBase中scan并不像大家想象的一样直接发送一个命令过去,服务器就将满足扫描条件的所有数据一次性返回给客户端。而
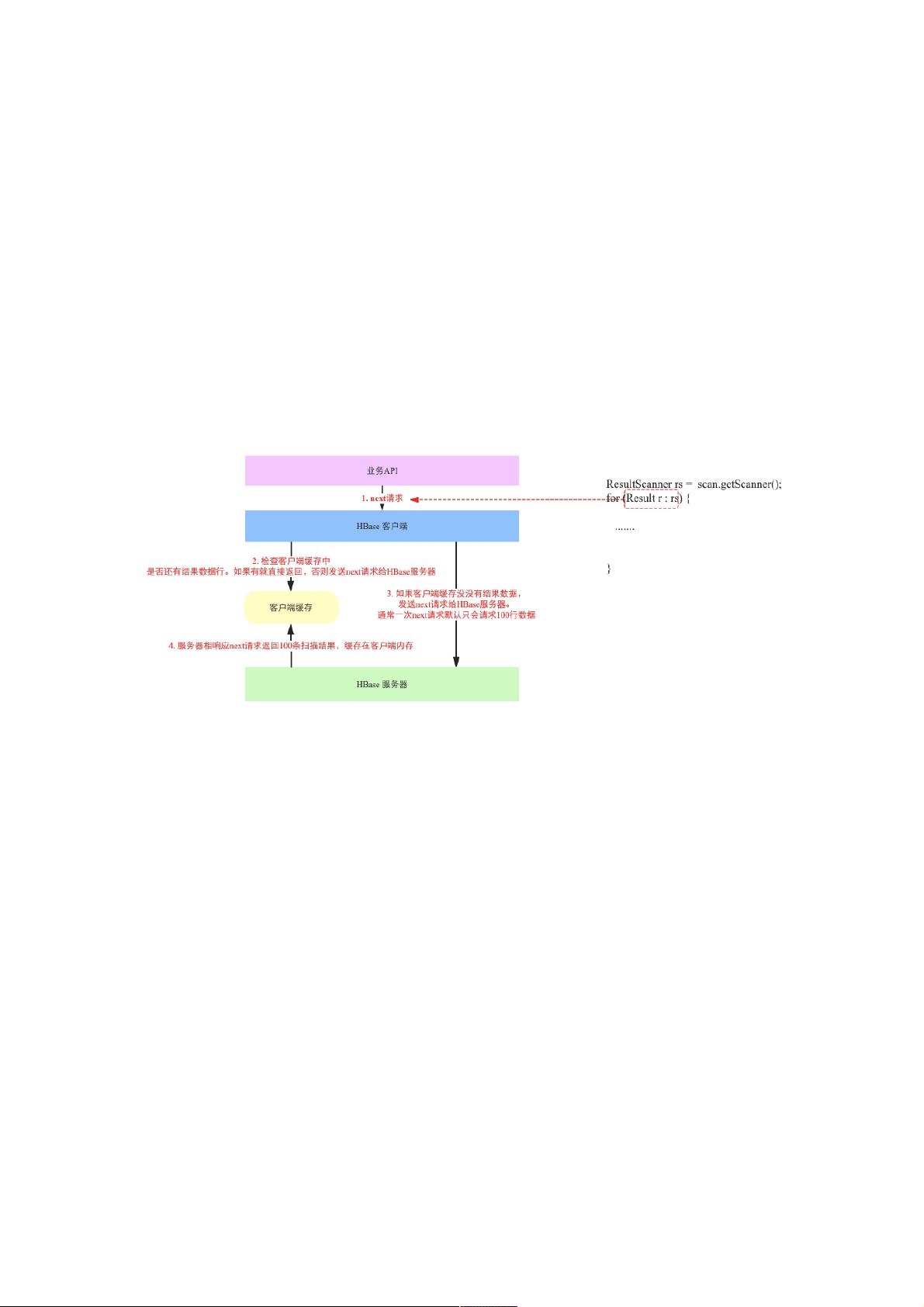
实际上它的工作原理如下图所示:
上图右侧是HBase scan的客户端代码,其中for循环中每次遍历ResultScanner对象获取一行记录,实际上在客户端层面都会
调用一次next请求。next请求整个流程可以分为如下几个步骤:
next请求首先会检查客户端缓存中是否存在还没有读取的数据行,如果有就直接返回,否则需要将next请求给HBase服务器端
(RegionServer)。
如果客户端缓存已经没有扫描结果,就会将next请求发送给HBase服务器端。默认情况下,一次next请求仅可以请求100行数
据(或者返回结果集总大小不超过2M)
服务器端接收到next请求之后就开始从BlockCache、HFile以及memcache中一行一行进行扫描,扫描的行数达到100行之后
就返回给客户端,客户端将这100条数据缓存到内存并返回一条给上层业务。
上层业务不断一条一条获取扫描数据,在数据量大的情况下实际上HBase客户端会不断发送next请求到HBase服务器。有的朋
友可能会问为什么scan需要设计为多次next请求的模式?个人认为这是基于多个层面的考虑:
HBase本身存储了海量数据,所以很多场景下一次scan请求的数据量都会比较大。如果不限制每次请求的数据集大小,很可
能会导致系统带宽吃紧从而造成整个集群的不稳定。
如果不限制每次请求的数据集大小,很多情况下可能会造成客户端缓存OOM掉。
如果不限制每次请求的数据集大小,很可能服务器端扫描大量数据会花费大量时间,客户端和服务器端的连接就会timeout。
这样的设计有没有瑕疵?
next策略可以避免在大数据量的情况下发生各种异常情况,但这样的设计对于扫描效率似乎并不友好,这里举两个例子:
scan并没有并发执行。这里可能很多看官会问:扫描数据分布在不同的region难道也不会并行执行扫描吗?是的,确实不会,
至少在现在的版本中没有实现。这点一定出乎很多读者的意料,我们知道get的批量读请求会将所有的请求按照目标region进
行分组,不同分组的get请求会并发执行读取。然而scan并没有这样实现。
大家有没有注意到上图中步骤3和步骤4之间HBase服务器端扫描数据的时候HBase客户端在干什么?阻塞等待是吧。确实,
所以从客户端视角来看整个扫描时间=客户端处理数据时间+服务器端扫描数据时间,这能不能优化?
下载后可阅读完整内容,剩余3页未读,立即下载
2019-11-09 上传
2018-03-18 上传
2021-01-27 上传
2018-04-18 上传
2021-02-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

x_jiali
- 粉丝: 5
- 资源: 897
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
