分布式爬虫与云计算:提升网络抓取效率
需积分: 3 141 浏览量
更新于2024-07-26
收藏 1.62MB DOC 举报
"网络爬虫技术随着互联网与云计算的发展,逐渐走向分布式,以提升抓取性能和可扩展性。分布式爬虫将任务分配到不同节点,例如按地理位置或网络运营商来定位目标网站。分布式计算与云计算密切相关,前者利用网络中的多台计算机协同处理任务,后者则是分布式计算、并行计算和网格计算的延伸,提供大规模数据处理和存储能力。分布式网络允许数据存储和处理在本地,降低对中央服务器的依赖,提高了数据访问速度和系统的灵活性。而云计算则进一步优化资源利用,降低成本,支持大规模的数据共享和处理。"
在深入探讨网络爬虫分布式技术之前,我们先理解什么是网络爬虫。网络爬虫,又称为网页蜘蛛或机器人,是一种自动遍历和抓取互联网信息的程序。它们按照一定的规则,模拟人类浏览器的行为,从一个网页出发,通过解析HTML和其他相关文件,发现新的链接,并继续抓取这些链接指向的页面,以此构建起庞大的网页索引。
分布式爬虫是应对互联网海量信息的策略之一。在分布式系统中,爬虫任务被分割并分配给多个独立的节点执行,这不仅有助于提高抓取速度,还能有效防止单一节点过载,增强系统的稳定性。例如,Google的分布式爬虫体系就利用了大量硬件设备,实现了高效且全面的网页抓取。
云计算为分布式爬虫提供了强大的计算和存储资源。云计算平台如Amazon AWS、Microsoft Azure和Google Cloud等,提供了弹性伸缩的计算实例,可根据需要快速增加或减少计算资源。此外,云服务还提供了数据存储、负载均衡和分布式数据库等服务,为爬虫项目提供了便利的基础设施。
分布式爬虫的设计通常包括以下几个关键点:
1. **任务调度**:确定哪些任务应分配给哪个节点,确保负载均衡和效率。
2. **URL管理**:维护一个URL队列,确保不重复抓取和丢失链接。
3. **数据存储**:在分布式环境中,数据需要在节点间同步和共享,可能涉及分布式数据库或消息队列。
4. **爬虫节点协调**:节点之间需要通信,交换状态信息和结果数据。
5. **错误处理和恢复**:节点故障时,系统应能自动检测并恢复,保证爬取工作的连续性。
云计算环境中的分布式爬虫,可以通过配置动态调整资源,根据爬取任务的负载自动扩缩规模。同时,云计算平台的全球数据中心布局,可以更贴近目标网站,降低网络延迟,提高爬取效率。
总结来说,网络爬虫的分布式技术结合云计算的优势,能够以更低的成本、更高的效率和更强的可扩展性处理大规模的网页抓取任务。这对于数据分析、搜索引擎优化、市场研究等多个领域都有重要价值。

78
1
步骤五:考察服务器的变动。
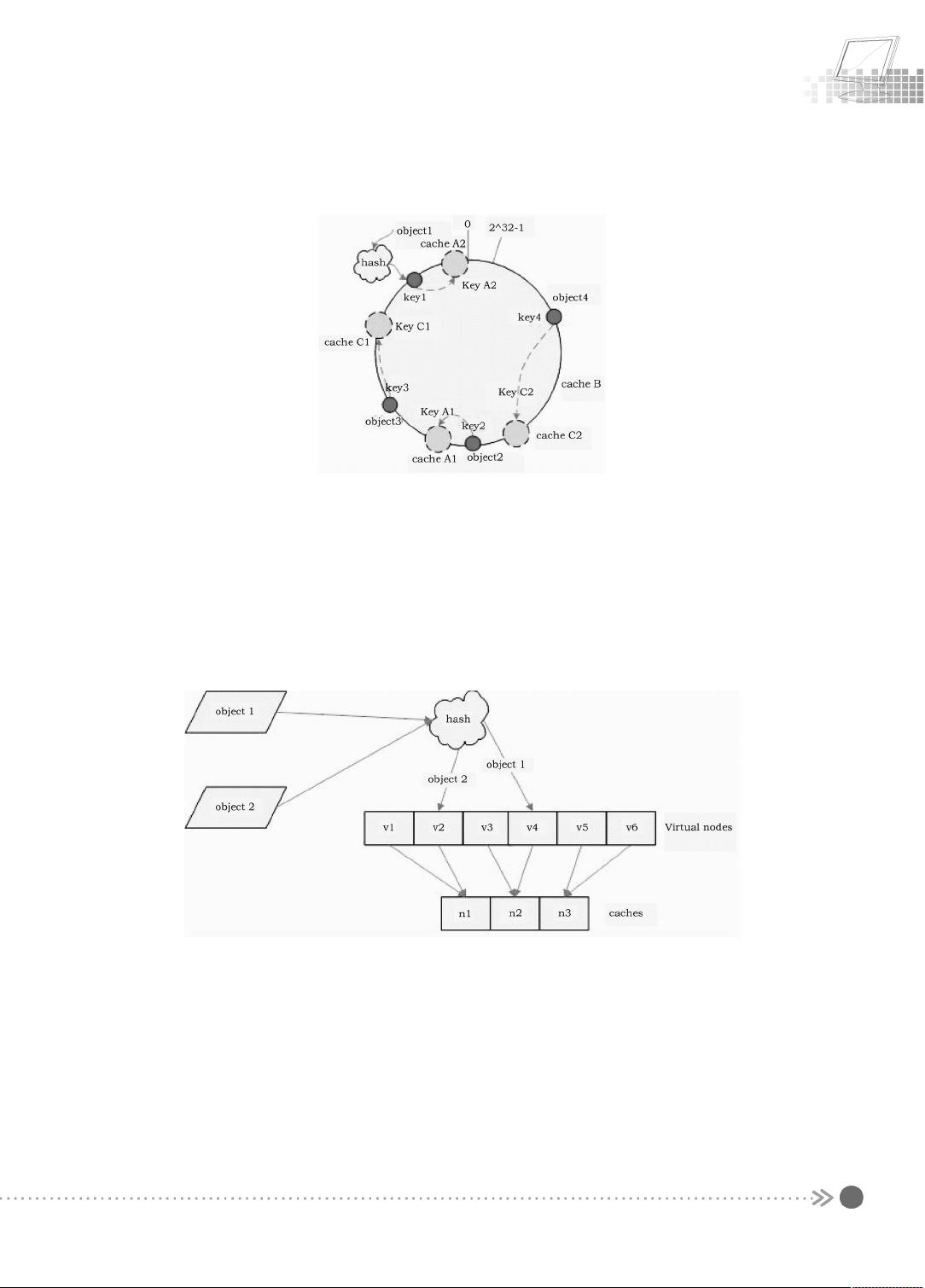
前面讲过,通过 hash 算法然后求余的方法带来的最大问题就在于不能满足单调性,当
服务器有所变动时,服务器会失效,进而对后台服务器造成巨大的冲击,现在就来分析
Consistent Hashing 算法。
(1) 移除服务器。
考虑假设服务器 B 挂掉了,根据上面讲到的映射方法,这时受影响的将只是那些沿
cache B 逆时针遍历直到下一个服务器(服务器 C )之间的对象,也即是本来映射到服务器 B
上的那些对象。
因此这里仅需要变动对象 object4,将其重新映射到服务器 C 上即可,如图 2.5 所示。
(2) 添加服务器。
再考虑添加一台新的服务器 D 的情况,假设在这个环形 hash 空间中,服务器 D 被映
射在对象 object2 和 object3 之间。这时受影响的仅是那些沿 cache D 逆时针遍历直到下一
个服务器(服务器 B )之间的对象,将这些对象重新映射到服务器 D 上即可。 因此这里仅需
要变动对象 object2,将其重新映射到服务器 D 上,如图 2.6 所示。
考量 hash 算法的另一个指标是平衡性(Balance),定义如下:
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中,这样可以使所有的缓冲空间
都得到利用。
hash 算法并不能保证绝对的平衡,如果服务器较少,对象并不能被均匀地映射到服务
器上,比如在上面的例子中,仅部署服务器 A 和服务器 C 的情况下,在 4 个对象中, 服务
器 A 仅存储了 object1,而服务器 C 则存储了 object2、object3 和 object4,分布是很不均
衡的。
图 2.5 服务器 B 被移除后的映射 图 2.6 添加服务器 D 后的映射关系
为了解决这种情况,Consistent Hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一个实际节点对
应若干个“虚拟节点”,这个对应个数也称为“复制个数”,“虚拟节点”在 hash 空间中以 hash
值排列。
仍以仅部署服务器 A 和 服务器 C 的情况为例,在图 2.5 中我们已经看到,服务器分布
并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2,这就意味着一共会存在 4 个
剩余54页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2012-09-28 上传
2011-05-05 上传
2014-10-03 上传
2011-12-29 上传
2022-05-29 上传

当时我是真惊了
- 粉丝: 2
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
