"19-华勤-Sage Practical项目简介及实际应用案例"
需积分: 0 43 浏览量
更新于2024-02-01
收藏 4.62MB PDF 举报
华勤是一家在人工智能领域具有丰富经验和专业能力的公司。他们提供的Sage Practical解决方案为企业提供了一种快速高效的生成文本的能力。
首先,Sage Practical具备强大的自然语言处理能力。它可以理解和分析人类语言,从而能够生成与人类类似的文本内容。无论是自动化客服回复、新闻稿、市场调研报告还是广告宣传语,Sage Practical都可以快速生成高质量的文本,节省了大量的时间和人力。
其次,Sage Practical还具备智能化的文本生成能力。他们采用了最先进的机器学习和深度学习算法,通过大量训练数据来提高文本生成的准确性和流畅度。无论是生成长篇大论的文章还是简短的广告文案,Sage Practical都可以根据用户的要求和预设条件,将信息组织得井井有条,让人一目了然。
此外,Sage Practical还拥有高度可定制化的特点。用户可以根据自己的需求和偏好,对生成的文本进行进一步的调整和编辑。无论是修改词汇、调整句子结构还是重新组织段落,Sage Practical都可以灵活应对,确保生成的文本符合用户的要求。
更重要的是,Sage Practical还具备自学习的能力。它可以通过与用户的交互不断学习和优化自身的模型,提高文本生成的质量和效率。随着使用时间的增长,Sage Practical将变得越来越智能化,越来越懂得用户的需求和喜好,帮助用户更好地完成工作任务。
最后,Sage Practical在数据隐私和安全方面也非常重视。他们采用了先进的数据加密和存储技术,确保用户的数据得到充分的保护和安全。用户可以放心使用Sage Practical进行文本生成,而不用担心数据泄露或滥用的风险。
总之,Sage Practical是一种功能强大、智能高效的文本生成工具。无论是对于个人用户还是企业客户来说,他们都可以通过使用Sage Practical节省时间、提高工作效率,并生成高质量的文本内容。华勤作为一个在人工智能领域具有丰富经验和专业能力的公司,通过Sage Practical为人工智能技术在文本生成领域的应用提供了新的可能性。
ASPLOS ’21, April 19–23, 2021, Virtual, USA Yu Gan, Mingyu Liang, Sundar Dev, David Lo, and Christina Delimitrou
A
B
- : Request send queueing
- : Request network latency
- : Request recv queueing
- : RPC server-side latency
- : Response send queueing
- : Response network latency
- : Response recv queueing
- : RPC client-side latency
RPC 0
Figure 2: RPC latency breakdown. Red bars: RPC server-side
latency, blue bars: network latency, green bars: application
queueing.
NIC. After being processed by the server’s network protocol stack
at
3
, the request is queued in the RPC channel’s receive queue,
waiting to be processed via the
rpc0_handler
, which starts at
time
4
and ends at
5
. Finally, the RPC response follows the same
process from server to client, until it is received by the client’s
application layer at time
8
.
1
-
8
and
4
-
5
are the application-
level client- and server-side latencies, respectively.
2
-
3
and
6
-
7 are the latencies in the network protocol, switches, and wiring.
1
-
2
,
3
-
4
,
5
-
6
, and
7
-
8
is the queueing time in the
application layer of the client and server, respectively.
Timestamps for the user-level events
1
,
4
,
5
, and
8
can be
obtained with distributed tracing frameworks, such as Jaeger. Times-
tamping
2
,
3
,
6
, and
7
, would require probing the Linux kernel
with high-overhead tools, like SystemTap [
45
]. Instead, we approxi-
mate the request/response network delay by measuring the latency
of heartbeat signals between client and server, when queueing in
the application is zero.
B
C
D E
A
RPC 0
RPC 1
RPC 2
RPC 3
RPC 0
RPC 1
RPC 2
RPC 3
Figure 3: Dep endency graph and traces of nested RPCs.
3.2.2 Markov Property of RPC Latency Propagation.
Multiple RPCs form a tree of nested traces in a distributed mon-
itoring system. Fig. 3 shows an example RPC dependency graph
with ve services, four RPCs, and its corresponding latency traces.
When the user request arrives at
A
, it sends
RPC0
to service
B
.
B
further forwards the request to
C
via
RPC1
, and
C
sends it to the
backend services
D
and
E
via
RPC2
and
RPC3
in parallel. After pro-
cessing the responses from
D
and
E
,
C
replies to
B
, and
B
replies to
A, as RPC1 and RPC0 return.
The server-side latency of any non-leaf RPC is determined by the
processing time of the RPC itself and the waiting time (i.e., client-
side latency) of its child RPCs. This latency propagates through
the RPC graph to the frontend. Since the latency of a child RPC
cannot propagate to its parent without impacting its own latency,
the latency propagation follows a local Markov property, where
each latency is conditionally independent on its non-descendant
RPCs, given its child RPC latencies [
69
]. For instance, the latency
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
MI/CMI
MI
CMI
MI(0;2)
CMI(0;2|1)
MI(1;3)
CMI(1;3|2)
MI(2;4)
CMI(2;4|3)
MI(3;5)
CMI(3;5|4)
MI(4;6)
CMI(4;6|5)
MI(5;7)
CMI(5;7|6)
MI(6;8)
CMI(6;8|7)
MI(7;9)
CMI(7;9|8)
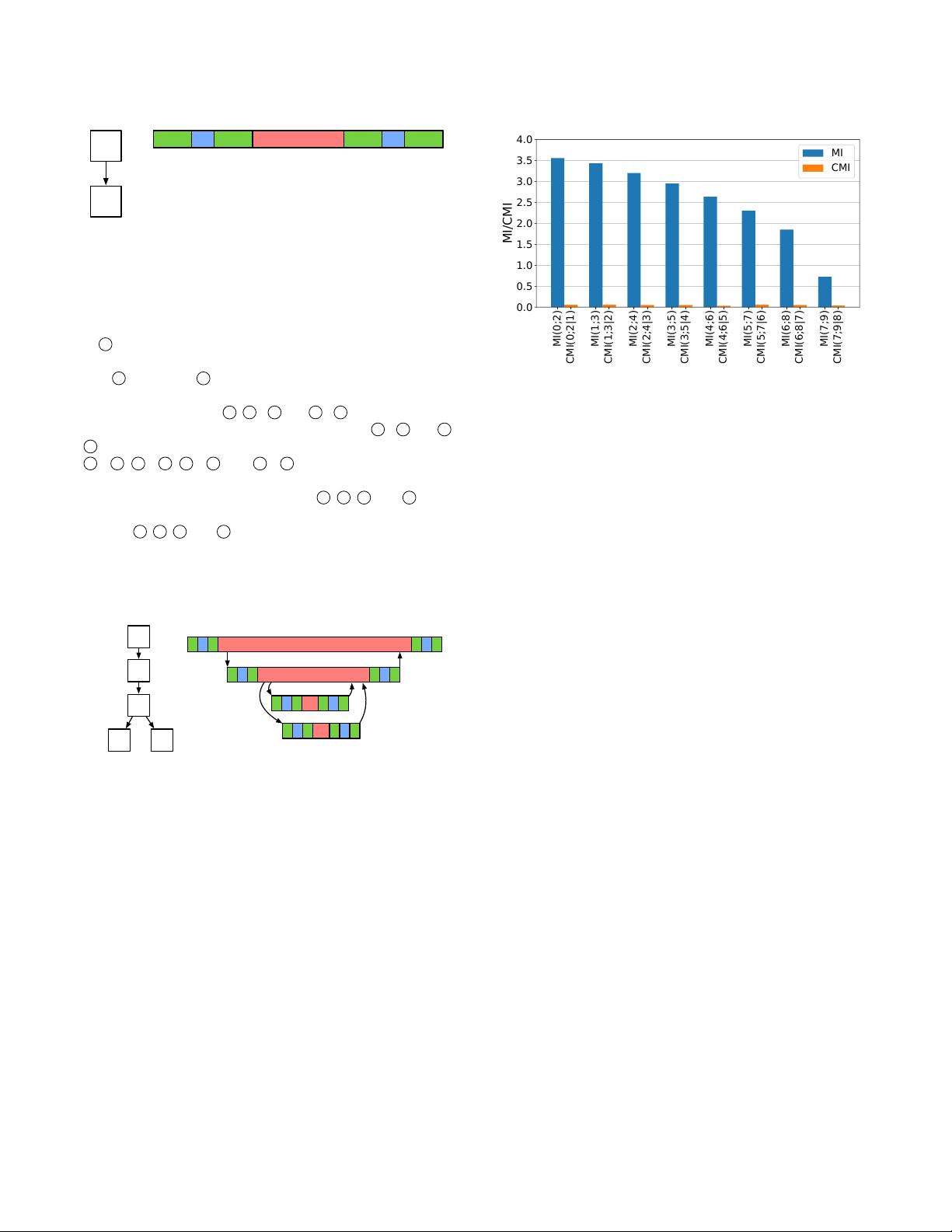
Figure 4: Mutual Information (MI) of two distance-of-2
RPCs, and Conditional Mutual Information (CMI) given the
server latency of the middle RPC. CMI of zero means that
the latencies of the two RPCs are conditionally independent,
given the latency of their in-between RPC.
of
RPC0
is conditionally independent of
RPC2
and
RPC3
, given the
latency of RPC1.
In information theory, mutual information measures the reduc-
tion of uncertainty in one random variable given another random
variable. Two random variables are independent or conditionally
independent if their mutual information (MI) or conditional mu-
tual information (CMI) is zero [
53
]. Fig. 4 shows the MI of the
server-side latencies of two RPCs with distance of two, and their
CMI, given the server-side latency of the in-between RPC, in a
10-microservice chain. The MI of each two non-adjacent RPCs is
blocked by the latency of the RPC in the middle, making them
conditionally independent [27].
3.3 Modeling Microservice Dependency Graphs
3.3.1 Causal Bayesian Networks.
A CBN is a directed acyclic graph (DAG), where the nodes are
random variables and the edges indicate their conditional depen-
dencies, from cause to eect [84, 88]. Sage uses three node types:
• Metric nodes (X )
: They contain resource-related metrics of all
services and network channels collected with tools, like Google
Wide Proling [
24
,
34
,
96
]. They are the exogenous variables that
cause latency variances across RPCs, and fall into two groups:
server- and network-related. Server-related metrics (
X
s
), include
CPU utilization, memory bandwidth, context switches, etc., and
impact the server’s processing time. Network-related metrics
(
X
net
), such as the round trip time (RTT), packet loss rate, net-
work bandwidth, etc., aect the delay of RPC channels. The set
of sucient metrics was derived by selecting those features that
improve the model’s accuracy, without overtting to a specic
deployment. Features that may be capturing overlapping informa-
tion are discarded by the network by demoting the corresponding
neuron weights. To keep the shape of the vector for each metric
the same regardless of the replicas per tier, we use a vector of
percentiles [
64
], e.g., [10th%, ..., 90th%, 100th%] computed across
the tier’s replicas.
剩余16页未读,继续阅读
2024-03-14 上传
2024-10-17 上传
2024-10-17 上传
2024-10-17 上传

丛乐
- 粉丝: 37
- 资源: 312
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
