深入剖析Hadoop源代码:分布式云计算基石
"Hadoop源代码分析"
Hadoop作为开源的分布式计算框架,是云计算开发领域的重要组成部分,尤其对于深入理解分布式系统和大数据处理至关重要。Hadoop借鉴了Google的几大核心技术,包括Chubby、GFS、BigTable和MapReduce,并在Apache社区中发展成为Hadoop项目,具体对应为ZooKeeper、HDFS、HBase和Hadoop MapReduce。
HDFS(Hadoop Distributed File System)是Hadoop的核心组件之一,它是一个高容错、高可用的分布式文件系统,能够处理PB级别的数据。HDFS的设计目标是提供高吞吐量的数据访问,适合大规模数据集的应用。分析HDFS的源代码有助于理解其数据存储和分发机制,以及如何保证数据的可靠性和一致性。
MapReduce是另一种关键组件,它是一种编程模型,用于大规模数据集的并行计算。Map阶段将输入数据拆分成键值对,并在多台机器上并行处理;Reduce阶段则将Map的输出聚合在一起,生成最终结果。MapReduce的源代码分析有助于开发者理解任务调度、数据分发和容错机制。
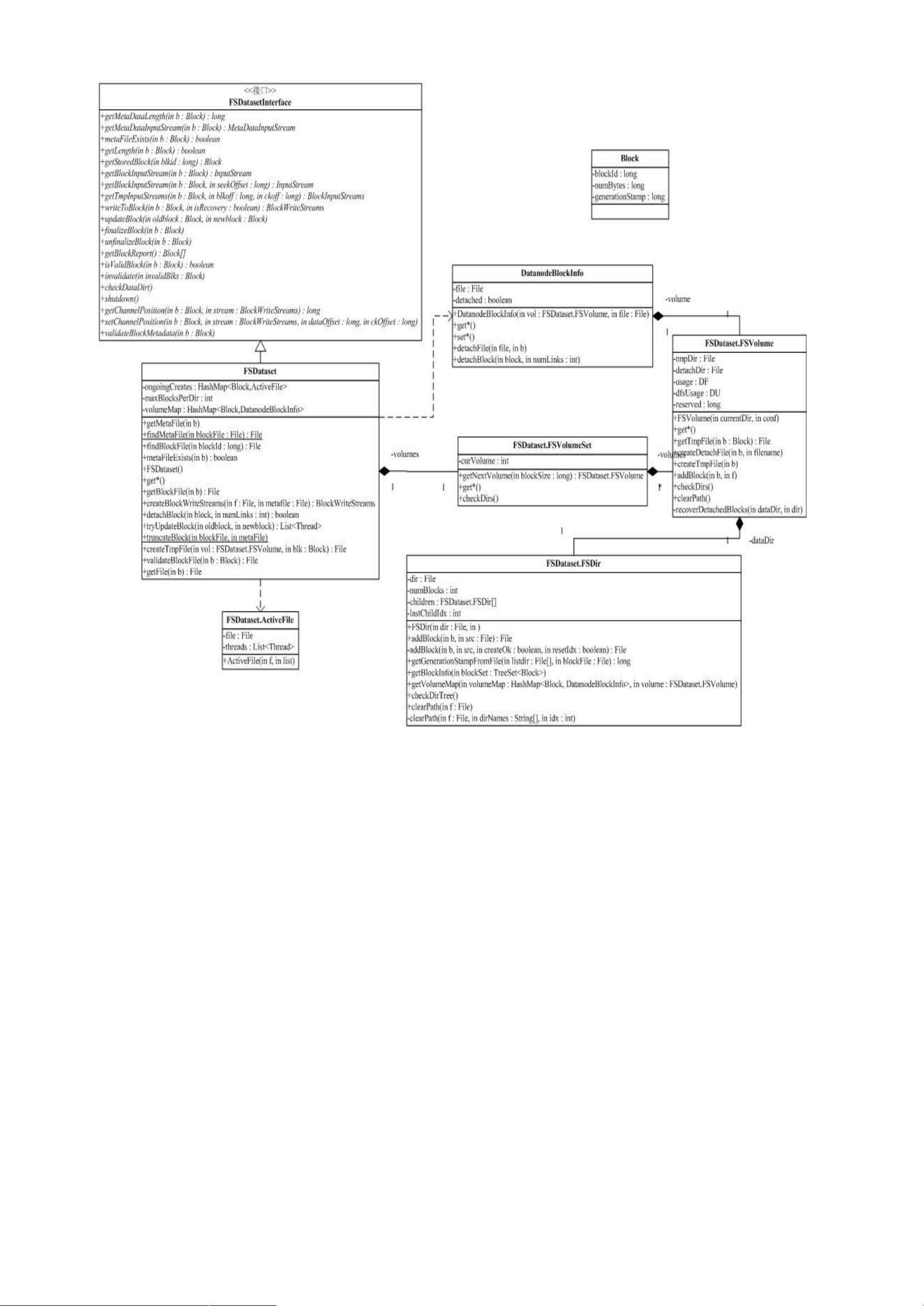
Hadoop的包结构复杂,其中conf包用于读取系统配置,fs包提供了对文件系统的抽象,使得HDFS可以透明地支持多种存储系统。这种设计允许Hadoop在各种环境下运行,包括本地文件系统、分布式文件系统和云存储服务。
在Hadoop源代码分析中,蓝色部分的包被视为关键部分,这通常包括与HDFS和MapReduce相关的实现。例如,`org.apache.hadoop.mapred`包包含了MapReduce作业的生命周期管理,`org.apache.hadoop.hdfs`包则包含了HDFS的实现。这些包的功能分析可以帮助开发者深入理解Hadoop内部的工作原理,从而更好地优化和定制Hadoop应用。
Hadoop源代码的详细分析涉及许多方面,如数据块的分配策略、心跳机制、数据复制、故障恢复、MapReduce作业的调度算法等。通过深入研究源代码,开发者可以学习到分布式系统的设计原则、并发控制、网络通信以及容错机制等核心概念。这对于提升云计算开发能力,尤其是在处理大数据问题时,具有非常重要的实践价值。

,) 包含了 . 个字段,分别是 D):版本号,如果 " 调整文件结构布局,版本号就会修改,这样
可以保证文件结构和应用一致。),' 是 的 ,',,)。
和 ,) 相比, 就是个大家伙了。
可以包含多个根(参考配置项 的说明),这些根通过 的内部类 ' 来表示。
' 中最重要的方法是 )-,它将根据系统启动时的参数和我们上面提到的一些判断条件,返回
系统现在的状态。' 可能处于以下的某一个状态(与系统的工作状态一定的对应):
NON_EXISTENT:指定的目录不存在;
NOT_FORMATTED:指定的目录存在但未被格式化;
COMPLETE_UPGRADE:previous.tmp 存在,current 也存在
RECOVER_UPGRADE:previous.tmp 存在,current 不存在
COMPLETE_FINALIZE:finalized.tmp 存在,current 也存在
COMPLETE_ROLLBACK:removed.tmp 存在,current 也存在,previous 不存在
RECOVER_ROLLBACK:removed.tmp 存在,current 不存在,previous 存在
COMPLETE_CHECKPOINT:lastcheckpoint.tmp 存在,current 也存在
RECOVER_CHECKPOINT:lastcheckpoint.tmp 存在,current 不存在
NORMAL:普通工作模式。
' 处于某些状态是通过发生对应状态改变需要的工作文件夹和正常工作的 ) 夹来进行判断。状态改变
需要的工作文件夹包括:
previous:用于升级后保存以前版本的文件
previous.tmp:用于升级过程中保存以前版本的文件
removed.tmp:用于回滚过程中保存文件
finalized.tmp:用于提交过程中保存文件
lastcheckpoint.tmp:应用于从 NameNode 中,导入一个检查点
previous.checkpoint:应用于从 NameNode 中,结束导入一个检查点

剩余63页未读,继续阅读
6676 浏览量
2012-01-05 上传
773 浏览量
2013-09-12 上传
2013-10-23 上传
2022-06-18 上传

wjl111
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- NotATokenLogger
- capture_react
- ac:YML放置区
- 学生成绩管理系统.rar
- 【Java毕业设计】Java 网上商城系统-毕业设计.zip
- 电子功用-按键识别方法、键盘和电子设备
- AT91SAM7X256开发板(工程文件+程序),可直接制板加工-电路方案
- kbd_check:键盘检查器
- python实例-13 截图工具.zip源码python项目实例源码打包下载
- DA_project-
- Bot-S-ries-SITE-TOP-FLIX:阿尔法玛意甲上的Bot para passar osepisódios现场,Top Flix,testei unicamente nasérie宣言。
- django_sso:Django框架实现OAuth2
- 【Java毕业设计】c++,毕业设计,因为网络专业不能写java。冥思苦想了这么个玩意儿,本来想借此机会学习http.zip
- 电子功用-可充电锂硫电池的正极活性物质及其制备方法
- PackCC:用于C的packrat解析器生成器-开源
- 卡片式插入列表(iPhone源代码)
